
Python pandas 的索引方式 data.loc[],data[][]示例详解
更新时间:2023年02月15日 14:35:01 作者:暖仔会飞
这篇文章主要介绍了Python pandas 的索引方式 data.loc[], data[][]的相关资料,其中data.loc[index,column]使用.loc[ ]第一个参数是行索引,第二个参数是列索引,本文结合实例代码讲解的非常详细,需要的朋友可以参考下
1. data.loc[index,column]
使用.loc[ ]第一个参数是行索引,第二个参数是列索引
import pandas as pd data = pd.DataFrame([range(1,5),range(6,10),range(11,15)]) print(data) dt = data.loc[0,1] //[index,column] print(dt)
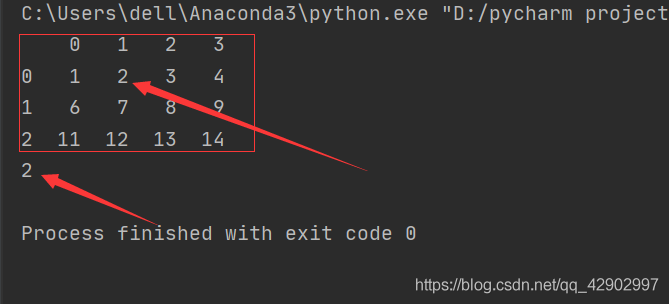
相当于第0行第1列
当然,还可以有如下操作,全部使用标签来作为行索引和列索引:
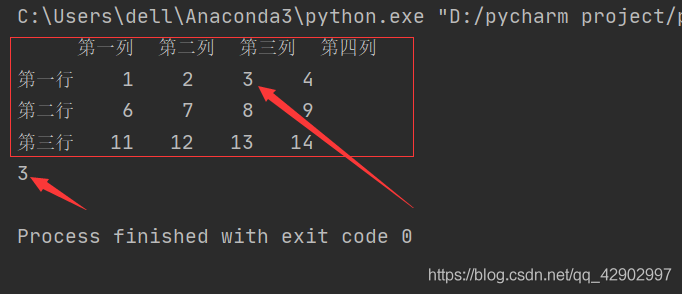
import pandas as pd data = pd.DataFrame([range(1,5),range(6,10),range(11,15)],['第一行','第二行','第三行'],['第一列','第二列','第三列','第四列']) print(data) dt = data.loc['第一行','第三列'] print(dt)
也可以有如下情况,使用数字作为行索引,标签作为列索引:
import pandas as pd data = pd.DataFrame([range(1,5),range(6,10),range(11,15)],[0,1,2],['第一列','第二列','第三列','第四列']) print(data) dt = data.loc[0,'第三列'] print(dt)
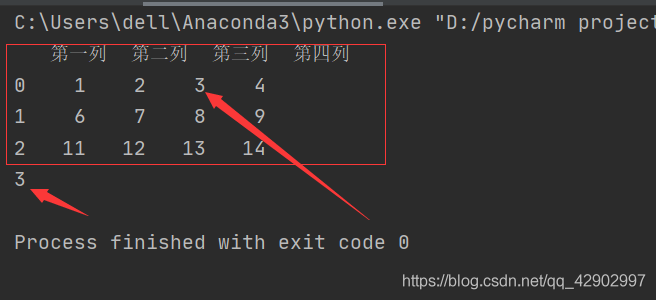
2. data[column][index]
这里与上面不同,使用两个方括号的索引方式,列标签的优先级更高一些,是列在前行在后。
import pandas as pd data = pd.DataFrame([range(1,5),range(6,10),range(11,15)]) print(data,'\n') print(data[2][0])

即使是在产生dataframe的时候把行列标签列的毫无歧义,也同样要满足列在前、行在后。
import pandas as pd data = pd.DataFrame([range(1,5),range(6,10),range(11,15)],[0,1,2],['第一列','第二列','第三列','第四列']) print(data,'\n') print(data['第二列'][0])
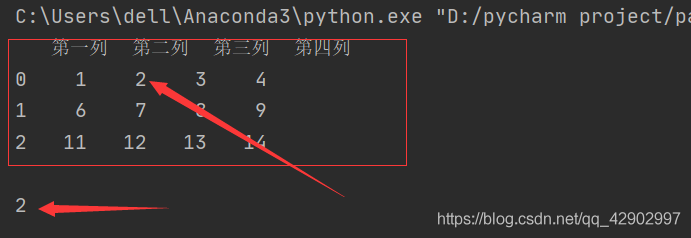
切记!!!!任何情况下如果直接使用data[][]的索引方式,第一个代表的都是列标签,如果行标签放在前面一定会出错。
到此这篇关于Python pandas 的索引方式 data.loc[], data[][]的文章就介绍到这了,更多相关Python pandas索引方式内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 今天小编就为大家分享一篇关于Python并发:多线程与多进程的详解,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2019-01-01
今天小编就为大家分享一篇关于Python并发:多线程与多进程的详解,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2019-01-01 这篇文章主要介绍了Idea安装python显示无SDK问题解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-08-08
这篇文章主要介绍了Idea安装python显示无SDK问题解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-08-08 今天小编就为大家分享一篇python实现对任意大小图片均匀切割的示例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12
今天小编就为大家分享一篇python实现对任意大小图片均匀切割的示例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12
Python Tkinter Gui运行不卡顿(解决多线程解决界面卡死问题)
最近写的Python代码不知为何,总是执行到一半卡住不动,所以下面这篇文章主要给大家介绍了关于Python Tkinter Gui运行不卡顿,解决多线程解决界面卡死问题的相关资料,需要的朋友可以参考下2023-02-02
Pycharm代码无法复制,无法选中删除,无法编辑的解决方法
今天小编就为大家分享一篇Pycharm代码无法复制,无法选中删除,无法编辑的解决方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-10-10 这篇文章主要介绍了Python实现简单的"导弹" 自动追踪原理解析,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-03-03
这篇文章主要介绍了Python实现简单的"导弹" 自动追踪原理解析,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-03-03
Python网络编程之socket与socketserver
这篇文章介绍了Python网络编程之socket与socketserver,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-05-05 这篇文章主要为大家介绍了Pytest初学者快速上手的高效Python测试指南,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2024-01-01
这篇文章主要为大家介绍了Pytest初学者快速上手的高效Python测试指南,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2024-01-01 本文主要介绍了浅谈Python实时检测CPU和GPU的功耗,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-01-01
本文主要介绍了浅谈Python实时检测CPU和GPU的功耗,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-01-01 这篇文章主要介绍了vscode搭建之python Django环境配置方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-01-01
这篇文章主要介绍了vscode搭建之python Django环境配置方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-01-01










最新评论