
ChatGPT平替-ChatGLM环境搭建与部署运行效果
ChatGLM-6B 是清华大学团队推出的一个开源的、支持中英双语的对话语言模型,基于General Language Model (GLM) 架构,具有62亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需6GB 显存)。ChatGLM-6B使用了与ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约1T标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62亿参数的ChatGLM-6B已经能生成相当符合人类偏好的回答。
本节将介绍环境搭建与基本部署效果,后续博文将介绍多用户调用部署和模型微调方法。具体更新请参考《Python从零开始进行AIGC大模型训练与推理》,地址为“参考资料”。
1 环境搭建
显卡驱动、CUDA、CUDNN、Docker、Python等环境搭建请参考本专栏另一篇博文《Docker AIGC等大模型深度学习环境搭建(完整详细版)》,地址为“https://www.jb51.net/article/283300.htm”。
1.1 Git lfs安装
相比于常规Git,Git Large File Storage (LFS) 主要是用于大文件操作。GitHub的工程一般会有存储容量限制,因而很多模型文件由于超出容量限制而被作者存储在类似百度网盘和谷歌网盘上。很多自然语言处理(NLP)、人工智能生成内容(AIGC)、计算机视觉(CV)等大模型可在huggingface网站进行下载,其工程比较完整,同时包括模型文件和程序。ChatGLM-6B的Huggingface网站地址为“https://huggingface.co/THUDM/chatglm-6b”。Git lfs更适合这类大文件的上传更新与下载。
Git lfs安装命令如下所示:
apt-get update apt-get install git curl -y#如果已安装curl,这一步可跳过。 curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash apt-get install git-lfs
安装完成之后,输入“git lfs env”查看安装结果,如果提示错误“Error: Failed to call git rev-parse --git-dir: exit status 128”,那么需要输入如下命令。
git init git lfs install
输入“git lfs env”的结果如下图所示。
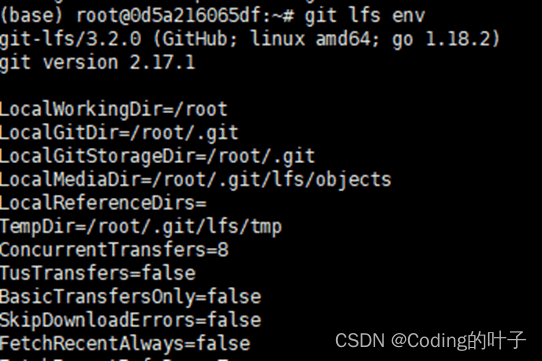
图1 git lfs安装环境查看结果
1.2 创建Python环境
这里使用conda创建一个Python 3.9环境,命令如下所示。
conda create -n chatglm python=3.9 -y conda activate chatglm
如果conda命令提示错误“CommandNotFoundError: Your shell has not been properly configured to use 'conda activate'.”,完整错误如下所示,那么可尝试输入指令“/bin/bash”解决。这种错误主要出现在使用Jupyter Notebook终端。
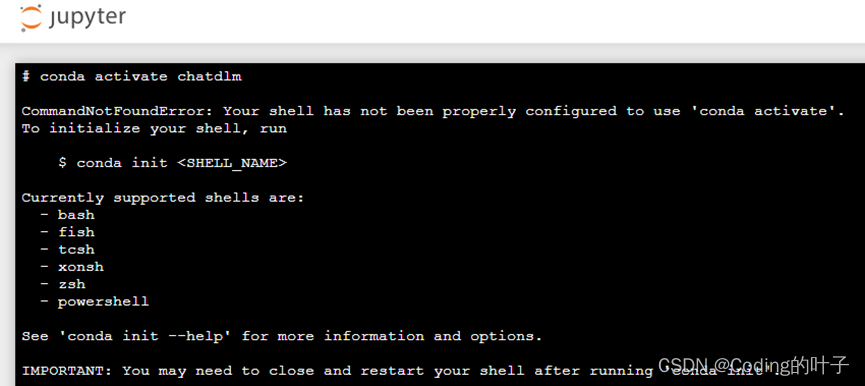
图2 conda环境激活错误
1.3 ChatGLM-6B环境安装
ChatGLM-6B的Github官方工程地址为“https://github.com/THUDM/ChatGLM-6B”。其环境安装命令如下所示:
git clone https://github.com/THUDM/ChatGLM-6B.git cd ChatGLM-6B conda activate chatglm pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
2 模型运行
2.1 cli_demo.py
在步骤1.3安装完成之后,可直接运行cli_demo.py启动对话程序(python cli_demo.py),如下所示。

图3 cli_demo.py运行示意图
2.2 api.py
该文件基于fastapi.py编写了一个http接口,默认端口号为8000。在服务器上运行该程序后(python api.py),我们即可通过http post调用模型接口。post数据包含prompt和history两个参数。Prompt是输入的问题内容。History是历史问答组成的列表,主要用于进行连续对话。模型占用显存大小与prompt和history的字数之和直接相关。因而,使用时最好对history的内容长度进行控制。
Linux可直接用curl进行http请求,格式如下所示。
curl -X POST "http://127.0.0.1:8000" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'我们也可以通过Python程序进行http post请求,如下所示。
import json
import requests
headers = {'Content-Type': 'application/json'}
url = 'http://127.0.0.1:8000'
data = {'prompt': '你好', 'history': []}
data = json.dumps(data)
reponse = requests.post(url=url, data=data, headers=headers)
print(reponse .text)http请求返回的内容包括response、history、status和time,其中response存储了直接结果,如下所示。
{"response":"你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。","history":[["你好","你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。"]],"status":200,"time":"2023-04-25 00:10:40"}
目前,多个用户调用该api时,将排队获取结果,即模型一次只能处理一个请求,多用户将根据调用先后顺序来获取结果。另一方面,api接口当前不支持流式输出,回答内容较多时等待时间较长。下一篇博文将介绍如何实现多用户同时调用以及采用流式输出,预计本周更新。
2.3 web_demo.py
该程序是基于gradio编写的web服务器,并提供前端访问页面,可通过浏览器进行访问。程序第一次运行前需要通过pip安装gradio,即“pip install gradio”。
程序会运行(python web_demo.py)一个Web Server,并输出地址,默认端口号为7860,如“http://127.0.0.1:7860”。在浏览器中打开输出的地址即可使用。最新版Demo实现了打字机效果,速度体验大大提升。注意,由于国内Gradio的网络访问较为缓慢,启用demo.queue().launch(share=True, inbrowser=True) 时所有网络会经过Gradio服务器转发,导致打字机体验大幅下降,现在默认启动方式已经改为share=False,如有需要公网访问的需求,可以重新修改为share=True 启动。该程序说明来源于ChatGLM-6B官方介绍。
改变端口号的方法为:
demo.queue().launch(share=False, inbrowser=True, server_name='0.0.0.0', server_port=8900)
同样地,该程序不支持多用户同时访问。下一篇博文将介绍如何实现多用户同时调用,预计本周更新。
运行后页面如下图所示。页面中的temperature主要用于设置答案的随机程度。如果其设置为1,那么相同问题每次得到答案都是完全一样的。
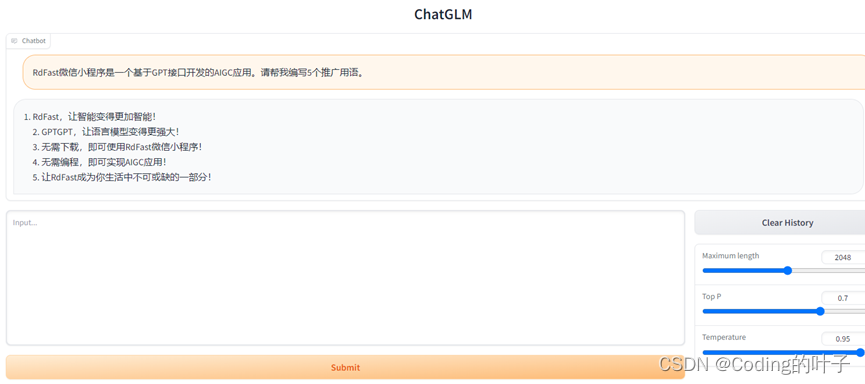
图4 web_demo.py的前端页面示意图
2.4 web_demo2.py
web_demo.py与web_demo2.py基本一样,都是运行带前端页面的web服务器。区别在于前者基于gradio开发,而后者基于streamlit开发。同样地,我们需要通过如下命令安装streamlit。
pip install streamlit -i https://pypi.tuna.tsinghua.edu.cn/simple pip install streamlit-chat -i https://pypi.tuna.tsinghua.edu.cn/simple
web_demo2.py的运行方式为“streamlit run web_demo2.py --server.port 5900”,运行后页面如下图所示。
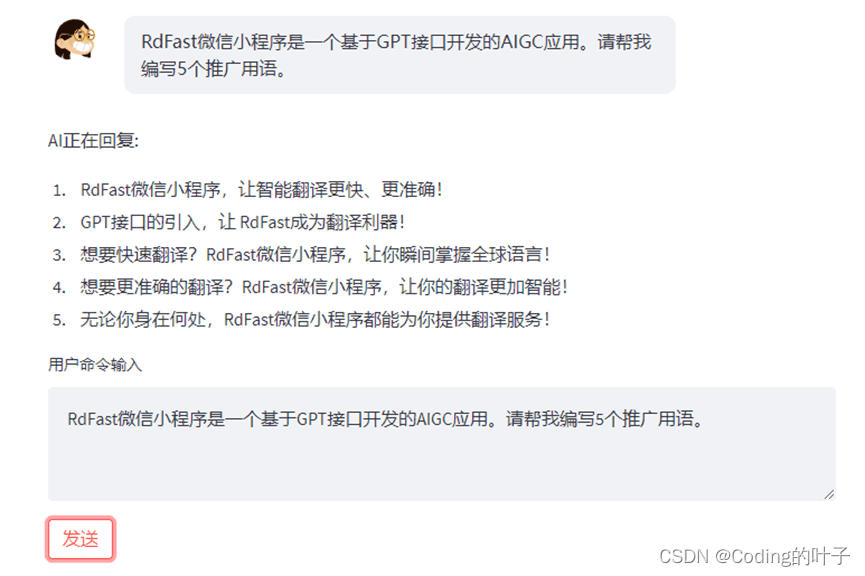
图5 web_demo2.py前端页面运行结果示意图
3 模型本地部署
以上各个程序在加载模型时的关键程序如下:
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()"THUDM/chatglm-6b"表示模型路径。程序会优先在本地搜索该路径,如果该路径不存在,那么程序将自动去huggingface网站进行搜索进行下载。这导致每次启动程序时,会花费较长时间来下载并加载模型。
我们可以通过git将模型下载到本地,下载命令为“git clone THUDM/chatglm-6b · Hugging Face”。假设我们在当前工程下执行该命令,那么文件夹下增加一个名称为chatglm-6b的文件夹,文件夹存储了下载的模型相关文件。相应地,我们需要按照如下方式替换模型加载程序中的模型路径。
tokenizer = AutoTokenizer.from_pretrained("chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm-6b", trust_remote_code=True).half().cuda()ChatGLM-6B提供多种量化精度模型,不同精度所需显存不同,如下所示。但是,在连续问答过程中,显存会随着历史信息增加而增加,因此需要注意控制程序中的history。
各个模型下载路径如下所示,使用时需要按照上述方法替换模型加载程序中的模型路径。
git clone THUDM/chatglm-6b · https://huggingface.co/THUDM/chatglm-6b git clone THUDM/chatglm-6b-int8 ·https://huggingface.co/THUDM/chatglm-6b-int8 git clone THUDM/chatglm-6b-int4 ·https://huggingface.co/THUDM/chatglm-6b-int4 git clone THUDM/chatglm-6b-int4 ·https://huggingface.co/THUDM/chatglm-6b-int4-qe
下一节将重点介绍ChatGLM的多用户调用方式,包括http、websocket和前端页面等。
到此这篇关于ChatGPT平替-ChatGLM环境搭建与部署运行的文章就介绍到这了,更多相关ChatGLM环境搭建与部署内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了各种语言、服务器301跳转代码全集,本文讲解了IIS下301设置、ASP下的301转向代码、ASP.Net下的301转向代码、PHP下的301转向代码 、CGI Perl下的301转向代码、JSP下的301转向代码等内容,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了各种语言、服务器301跳转代码全集,本文讲解了IIS下301设置、ASP下的301转向代码、ASP.Net下的301转向代码、PHP下的301转向代码 、CGI Perl下的301转向代码、JSP下的301转向代码等内容,需要的朋友可以参考下2015-04-04
使用selenium自动控制浏览器找不到Chromedriver问题
这篇文章主要介绍了ChromeDriver安装与配置问题的解决方法,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2020-02-02
fastjson到底做错了什么?为什么会被频繁爆出漏洞?(推荐)
前段时间,fastjson被爆出过多次存在漏洞,很多文章报道了这件事儿,并且给出了升级建议。本文给大家分享fastjson的releaseNote以及部分源代码。感兴趣的朋友跟随小编一起看看吧2020-07-07 这篇文章主要介绍了IDEA开启Run Dashboard的配置详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-06-06
这篇文章主要介绍了IDEA开启Run Dashboard的配置详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-06-06 这篇文章主要介绍了10分钟搞定让你困惑的 Jenkins 环境变量过程详解,本文通过图文实例相结合给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-01-01
这篇文章主要介绍了10分钟搞定让你困惑的 Jenkins 环境变量过程详解,本文通过图文实例相结合给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-01-01 目前主流的数据收集方式基本都是基于javascript的。本文将简要分析这种数据收集的原理,并一步一步实际搭建一个实际的数据收集系统2013-09-09
目前主流的数据收集方式基本都是基于javascript的。本文将简要分析这种数据收集的原理,并一步一步实际搭建一个实际的数据收集系统2013-09-09 在学习编程的道路上,算法是必不可少的一门课,最近就在重温算法,所以下面这篇文章主要给各位程序员们推荐了几本关于算法的相关书籍,需要的朋友们可以下载学习,相信会对大家具有一定的参考学习价值的,下面来一起看看吧。2017-07-07
在学习编程的道路上,算法是必不可少的一门课,最近就在重温算法,所以下面这篇文章主要给各位程序员们推荐了几本关于算法的相关书籍,需要的朋友们可以下载学习,相信会对大家具有一定的参考学习价值的,下面来一起看看吧。2017-07-07 这篇文章主要介绍了chatGPT本地部署、运行和接口调用的详细步骤,文中给大家介绍了cookie 信息写入 config.json的三种方式,每种方式给大家介绍的非常详细,需要的朋友可以参考下2023-02-02
这篇文章主要介绍了chatGPT本地部署、运行和接口调用的详细步骤,文中给大家介绍了cookie 信息写入 config.json的三种方式,每种方式给大家介绍的非常详细,需要的朋友可以参考下2023-02-02
将WSL系统更换国内源的方法(固定路径+国内镜像源+详细教程)
这篇文章主要介绍了将WSL系统更换国内源的方法(固定路径+国内镜像源+详细教程),首先找到wsl镜像源,替换镜像源,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-10-10 ESLint 是一款语法检测工具而prettier 是一个代码格式化插件,今天给大家分享vscode 配置eslint和prettier正确方法,感兴趣的朋友一起看看吧2021-07-07
ESLint 是一款语法检测工具而prettier 是一个代码格式化插件,今天给大家分享vscode 配置eslint和prettier正确方法,感兴趣的朋友一起看看吧2021-07-07










最新评论