
redis分布式锁解决缓存双写一致性
如何解决缓存双写问题
只要涉及到缓存,那么缓存双写的问题就避免不了,每一种情况下使用的方案也不相同,对于数据一致性要求不高的场景,我们可以使用延时双删等方案来实现,而对于一致性要求很高的场景,在之前查找的资料都是基于队列来实现,也就是所有的请求都进入一个队列,但是实现起来相对来说比较复杂。今天就使用分布式锁来实现
业务背景-美食分享
1: 现在有一个很火的美食博主分享了一篇美食,此刻是很多人都会来查看,对于美食分享是典型的读多写少的场景,可以利用缓存
//根据id查询美食信息
public GoodsVO loadGoodsInfoById(Long id) {
//从redis中拿用户信息
Object obj = redisTemplate.opsForValue().get(GOODS_KEY + id);
if(obj == null) {
//如果redis中不存在,就从数据库中获取
GoodsVO goods = loadGoodsFromDb(id);
//将结果保存到redis中
redisTemplate.opsForValue().set(GOODS_KEY+id,JSONUtil.toJsonPrettyStr(goods));
return fileUser;
}
return JSONUtil.toBean(obj.toString(), GoodsVO.class);
}//编辑美食信息
public void modifyGoodsById(GoodsVO goodsVO) throws Exception{
//删除缓存
redisTemplate.delete(GOODS_KEY + goodsVO.getId());
//更新用户信息
goodsMapper.updateById(goodsVO);
//删除缓存
Thread.sleep(1000);
redisTemplate.delete(GOODS_KEY + goodsVO.getId());
}而对于更新数据的时候是先更新缓存还是先更新数据库呢?
1:先更新缓存再更新数据库
- 如果更新缓存成功,更新数据库失败,那么缓存中的数据就是脏数据,与数据库数据不一致
2:先更新数据库再更新缓存
- 更新数据库成功,但是此时更新缓存失败,那么缓存中的还是脏数据,与数据库数据不一致
3:延时双删 - 先删除缓存,再更新数据库,最后再删除缓存
- 即使第一次删除缓存失败了,后续的更新数据库操作也不会执行,此时来读取的线程发现缓存中没有数据,从数据库读取最新的。
- 第一次删除缓存成功,更新数据库失败,此时来读取的线程发现缓存中没有数据,从数据库读取最新的。
- 第一次删除缓存成功,更新数据库成功,第二次删除缓存成功,那么来读取的线程发现缓存中没有数据,从数据库读取最新的。
- 第一次删除除缓存成功,更新数据库成功,第二次删除缓存失败,这时候就会有问题了
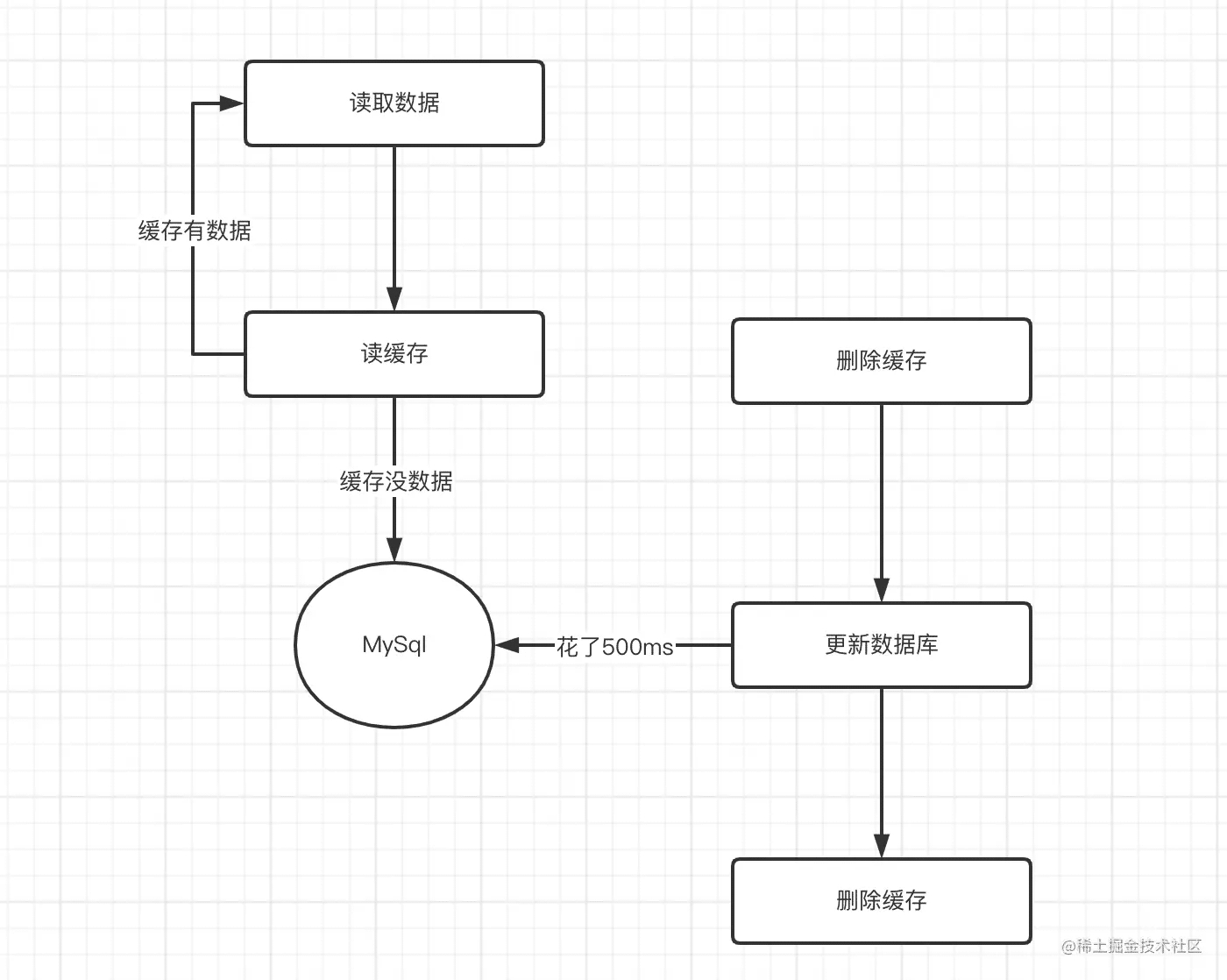
问题一:Thread-A第一次删除缓存成功,然后更新数据,但是这时候不知道怎么了,可能是线程阻塞了或者其它原因,导致还没有开始更新数据库,这时候另外一个线程Thread-B来读取数据了,读取到数据之后将数据放到缓存中,这时候Thread-A才开始更新数据库,但是Thread-A在第二次删除缓存的时候失败了,此时就导致缓存中的数据是之前的旧数据,与数据库的数据不一致
问题二:假设修改的时候都没问题,第二次删除的缓存的时候都正常,这时候读取数据的时候缓存里面肯定就没有了,这时候就要从数据库读取,如果这时候一下子并发量很高,那么这些线程都要从数据库中查询,这时候数据库都有可能直接挂掉
分布式锁
查询
//根据id查询美食信息
public GoodsVO loadGoodsInfoById(Long id) {
//从redis中拿用户信息
Object obj = redisTemplate.opsForValue().get(GOODS_KEY + id);
if(obj == null) {
//如果redis中不存在,就从数据库中获取
GoodsVO goods = loadGoodsFromDb(id);
return fileUser;
}
return JSONUtil.toBean(obj.toString(), GoodsVO.class);
}
//查询缓存中没有,这时候就要去数据库中查询
public String getGoodInfoFromDb(Long id) {
//此时这里要加的锁和 modifyGoodsById()方法加的应该是同一把锁,这样才能保证双写一致性
boolean lock = redisLock.tryLock(GOODS_KEY+id);
if(!lock) {
//获取锁失败,尝试从缓存中获取
Object obj = redisTemplate.opsForValue().get(GOODS_KEY + id);
if(obj != null){
return JSONUtil.toBean(obj.toString(), GoodsVO.class);
}else{
//直接返回一个操作频繁的信息给前端
throw new GloableException("访问频繁,请稍后再试");
}
}
try{
//获取到锁了
//尝试从缓存中拿
Object obj = redisTemplate.opsForValue().get(GOODS_KEY + id);
if(obj != null) {
return JSONUtil.toBean(obj.toString(), GoodsVO.class);
}
//缓存中没有,从MySql中拿
GoodsVO goods = goodsMapper.selectById(id);
if(goods == null) {
//为了解决缓存穿透的问题
redisTemplate.opsForValue().set(GOODS_NULL_KEY + id);
return null;
}
//将数据库查到的数据放到缓存中
redisTemplate.opsForValue().set(GOODS_KEY+id,JSONUtil.toJsonPrettyStr(goods));
return goods;
}finally{
//释放锁
redisLock.unLock(GOODS_KEY+goodsVO.getId());
}
}修改
//编辑美食信息
public void modifyGoodsById(GoodsVO goodsVO) throws Exception{
//尝试获取锁
boolean lock = redisLock.tryLock(GOODS_KEY+goodsVO.getId());
if(!lock) {
//直接返回一个操作频繁的信息给前端
throw new GloableException("更新数据失败,请稍后再试.....");
}
try{
//获取到锁了
//更新用户信息
goodsMapper.updateById(goodsVO);
//更新完之后,将数据库最新的数据更新到缓存中
redisTemplate.opsForValue().set(GOODS_KEY+id,JSONUtil.toJsonPrettyStr(goodsVO));
}finally{
//释放锁
redisLock.unLock(GOODS_KEY+goodsVO.getId());
}
}现在第一次来访问数据,返现Redis中没有,这时候就会去MySql中查,但是只有获取到锁的线程才可以去数据库中查,所以此时只有一个线程访问数据库,这时候即使有线程要去修改数据,由于锁已经被拿走了,无法获取到锁,也就无法修改,保证了数据一致性。
假设现在修改的线程获取到锁了。由于之前Redis中已经有数据了,此时所有读取数据的线程都从Redis中拿,当修改完数据之后,重新设置缓存,此时缓存中的数据就是最新的
以上就是分布式锁解决缓存双写一致性的详细内容,更多关于分布式锁解决缓存双写一致性的资料请关注脚本之家其它相关文章!
相关文章
 微信抢红包已经在我们生活中很常见的场景了,特别是年底公司开年会和春节2个时间段。本文主要介绍了通过Redis实现微信抢红包功能,感兴趣的小伙伴可以了解一下2021-12-12
微信抢红包已经在我们生活中很常见的场景了,特别是年底公司开年会和春节2个时间段。本文主要介绍了通过Redis实现微信抢红包功能,感兴趣的小伙伴可以了解一下2021-12-12 这篇文章主要介绍了Redis教程(二):String数据类型,本文讲解了String数据类型概述、相关命令列表、命令使用示例三部分内容,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了Redis教程(二):String数据类型,本文讲解了String数据类型概述、相关命令列表、命令使用示例三部分内容,需要的朋友可以参考下2015-04-04 Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。2016-05-05
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。2016-05-05 这篇文章主要介绍了SpringMVC集成redis配置的多种实现方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-03-03
这篇文章主要介绍了SpringMVC集成redis配置的多种实现方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-03-03 Redis集群提供了哨兵模式和高可用集群模式两种方案,前者适合低并发,配置复杂,主从切换可能导致瞬断;后者通过多主多从结构提高可用性和性能,支持线性扩展,配置简单,搭建Redis集群至少需要三个主节点2024-10-10
Redis集群提供了哨兵模式和高可用集群模式两种方案,前者适合低并发,配置复杂,主从切换可能导致瞬断;后者通过多主多从结构提高可用性和性能,支持线性扩展,配置简单,搭建Redis集群至少需要三个主节点2024-10-10 Redis缓冲区溢出是指Redis缓冲区被写入的数据超过了它的容量,导致数据无法存储或被覆盖。造成缓冲区溢出的原因可能是快速写入大量数据、缓冲区未及时刷新或Redis服务器配置不当等。2023-04-04
Redis缓冲区溢出是指Redis缓冲区被写入的数据超过了它的容量,导致数据无法存储或被覆盖。造成缓冲区溢出的原因可能是快速写入大量数据、缓冲区未及时刷新或Redis服务器配置不当等。2023-04-04 前段时间,做了一个世界杯竞猜积分排行榜。对世界杯64场球赛胜负平进行猜测,猜对+1分,错误+0分,一人一场只能猜一次。下面通过本文给大家分享基于redis实现世界杯排行榜功能项目实战,感兴趣的朋友一起看看吧2018-10-10
前段时间,做了一个世界杯竞猜积分排行榜。对世界杯64场球赛胜负平进行猜测,猜对+1分,错误+0分,一人一场只能猜一次。下面通过本文给大家分享基于redis实现世界杯排行榜功能项目实战,感兴趣的朋友一起看看吧2018-10-10 Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 本文主要为大家介绍了Redis如何结合Lua脚本实现分布式锁,需要的可以参考下2024-02-02
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 本文主要为大家介绍了Redis如何结合Lua脚本实现分布式锁,需要的可以参考下2024-02-02 这篇文章主要介绍了redis 存储对象的方法对比分析,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-07-07
这篇文章主要介绍了redis 存储对象的方法对比分析,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-07-07 这篇文章主要介绍了redis启动流程介绍,本文更分5步,分别是准备运行环境、解析命令行参数、initServer()初始化服务、loadDataFromDisk()从rdb或aof文件加载数据、aeMain()开始事件循环,接收客户端请求,需要的朋友可以参考下2015-01-01
这篇文章主要介绍了redis启动流程介绍,本文更分5步,分别是准备运行环境、解析命令行参数、initServer()初始化服务、loadDataFromDisk()从rdb或aof文件加载数据、aeMain()开始事件循环,接收客户端请求,需要的朋友可以参考下2015-01-01










最新评论