
Go语言实现LRU算法的核心思想和实现过程
GO实现Redis的LRU例子
常见的三种缓存淘汰算法有三种:FIFO,LRU和LFU
实现LRU缓存淘汰算法
1.FIFO/LFU/LRU算法简介
缓存全部存在内存中,内存是有限的,因此不可能无限制的添加数据,假定我们能够最大使用的内存为Max,那么在一个时间点之后,添加了某一条缓存记录之后,占用内存超过了N,这个时候就需要从缓存中移除一些数据,那么该移除或者淘汰谁呢?我们肯定希望去移除没用的数据,将热点数据留在缓存中,下面几种就是对应的几种策略!
FIFO (First in First Out)
先进先出,内存满了时淘汰最老存在最久的key缓存,这种算法认为越早被添加的数据使用可能性会比新加入进来的小,但是这种也有弊端,在某些场景下比如查历史支付记录的账单,就需要查询之前的缓存记录,这类记录就不得不因为每天新的支付从而淘汰掉以前的支付记录(当然这类记录存库是最好方式)
【实现方式】维护一个队列先进先出就行了,新来的数据加到队尾
LFU (Least Frequently Used)
最少使用,也就是淘汰缓存中访问频率最低的记录。这个算法认为过去访问次数最高的使用概率也最大,但是这样就额外维护了一个访问次数,对内存其实占用也挺多的,再者访问次数最多的数据,突然不使用了,那么要淘汰它之前,需要内存其他区域的数据访问次数全部超过它才有可能,所以淘汰的缺点也非常明显。
【实现方式】LFU 的实现需要维护一个按照访问次数排序的队列,每次访问,访问次数加1,队列重新排序,淘汰时选择访问次数最少的即可
LRU (Least Recently Used)
最近最少使用,相对于只考虑使用时间和使用次数来看,LRU会相对比较平均去淘汰数据,如果数据最近被使用过,那么将来被访问的概率将提高
【实现方式】维护一个队列,如果某条记录被访问了,则移动到队尾,那么队首则是最近最少访问的数据,淘汰该条记录即可。
2.LRU算法实现
2.1核心数据结构
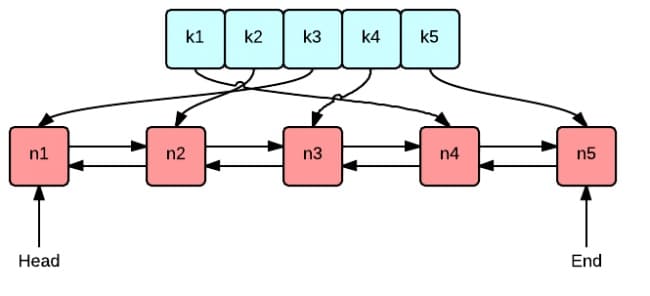
这张图很好地表示了 LRU 算法最核心的 2 个数据结构
- 绿色的是字典(map),存储键和值的映射关系。这样根据某个键(key)查找对应的值(value)的复杂是
O(1),在字典中插入一条记录的复杂度也是O(1)。 - 红色的是双向链表(double linked list)实现的队列。将所有的值放到双向链表中,这样,当访问到某个值时,将其移动到队尾的复杂度是
O(1),在队尾新增一条记录以及删除一条记录的复杂度均为O(1)。
接下来我们创建一个包含字典和双向链表的结构体类型 Cache,方便实现后续的增删查改操作。
package lru
import (
"container/list"
"log"
)
// Cache is a LRU cache. It is not safe for concurrent access.
type Cache struct {
maxBytes int64 // 允许使用的最大内存
nbytes int64 // 当前已使用的内存
ll *list.List
cache map[string]*list.Element
// optional and executed when an entry is purged.
OnEvicted func(key string, value Value) // 某条记录被移除时的回调函数
}
type entry struct {
key string
value Value
}
// Value use Len to count how many bytes it takes
type Value interface {
Len() int
}- 在这里我们直接使用 Go 语言标准库实现的双向链表
list.List。 - 字典的定义是
map[string]*list.Element,键是字符串,值是双向链表中对应节点的指针。 maxBytes是允许使用的最大内存,nbytes是当前已使用的内存,OnEvicted是某条记录被移除时的回调函数,可以为 nil。- 键值对
entry是双向链表节点的数据类型,在链表中仍保存每个值对应的 key 的好处在于,淘汰队首节点时,需要用 key 从字典中删除对应的映射。 - 为了通用性,我们允许值是实现了
Value接口的任意类型,该接口只包含了一个方法Len() int,用于返回值所占用的内存大小。
方便实例化 Cache,实现 New() 函数:
// New is the Constructor of Cache
func New(maxBytes int64, onEvicted func(string, Value)) *Cache {
return &Cache{
maxBytes: maxBytes,
ll: list.New(),
cache: make(map[string]*list.Element),
OnEvicted: onEvicted,
}
}2.2查找功能
查找主要有 2 个步骤,第一步是从字典中找到对应的双向链表的节点,第二步,将该节点移动到队尾。
func (c *Cache)Get(key string)(val Value,ok bool){
// 如果找到了节点,就将缓存移动到队尾
if ele,ok:=c.cache[key];ok{
c.ll.MoveToBack(ele)
kv:=ele.Value.(*entry)
return kv.value,true
}
return
}- 如果键对应的链表节点存在,则将对应节点移动到队尾,并返回查找到的值。
c.ll.MoveToBack(ele),即将链表中的节点ele移动到队尾
2.3删除
这里的删除,实际上是缓存淘汰。即移除最近最少访问的节点(队首)
// 移除最近最近,最少访问的的节点
func (c *Cache)RemoveOldest(){
ele:=c.ll.Front() // 取到队首节点,从链表中删除
if ele!=nil{
c.ll.Remove(ele)
kv:=ele.Value.(*entry)
delete(c.cache,kv.key)
c.nbytes-=int64(len(kv.key))+int64(kv.value.Len())
if c.OnEvicted != nil {
c.OnEvicted(kv.key, kv.value)
}
}
}c.ll.Front()取到队首节点,从链表中删除。delete(c.cache, kv.key),从字典中c.cache删除该节点的映射关系。- 更新当前所用的内存
c.nbytes。 - 如果回调函数
OnEvicted不为 nil,则调用回调函数
2.4新增或修改
// 新增或修改
func (c *Cache)Add(key string ,value Value){
if int64(value.Len())>c.maxBytes{
log.Printf("超过最大容量%d,插入缓存容量为%d",c.maxBytes,int64(value.Len()))
return
}
if ele,ok:=c.cache[key];ok{
c.ll.MoveToBack(ele)
kv:=ele.Value.(*entry)
c.nbytes += int64(value.Len()) - int64(kv.value.Len())
}else{
ele:=c.ll.PushFront(&entry{key: key,value: value})
c.cache[key]=ele
c.nbytes=int64(len(key))+int64(value.Len())
}
// 如果当前使用的内存>允许使用的最大内存 使用淘汰策略
for c.maxBytes !=0 && c.maxBytes < c.nbytes{
c.RemoveOldest()
}
}- 如果键存在,则更新对应节点的值,并将该节点移到队尾。
- 不存在则是新增场景,首先队尾添加新节点
&entry{key, value}, 并字典中添加 key 和节点的映射关系。 - 更新
c.nbytes,如果超过了设定的最大值c.maxBytes,则移除最少访问的节点。
到此这篇关于Go语言实现LRU算法的核心思想和实现过程的文章就介绍到这了,更多相关Go LRU算法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了goland -sync/atomic原子操作,原子操作能够保证执行期间是连续且不会被中断(变量不会被其他修改,mutex可能存在被其他修改的情况),本文给大家介绍的非常详细,需要的朋友参考下2022-08-08
这篇文章主要介绍了goland -sync/atomic原子操作,原子操作能够保证执行期间是连续且不会被中断(变量不会被其他修改,mutex可能存在被其他修改的情况),本文给大家介绍的非常详细,需要的朋友参考下2022-08-08 这篇文章主要为大家介绍了LRU LFU TinyLFU缓存算法实例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-09-09
这篇文章主要为大家介绍了LRU LFU TinyLFU缓存算法实例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-09-09 函数是基本的代码块,用于执行一个任务。本文详细讲解了Go语言中的函数,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-07-07
函数是基本的代码块,用于执行一个任务。本文详细讲解了Go语言中的函数,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-07-07 这篇文章主要为大家介绍了go语言题解LeetCode1122数组的相对排序,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-12-12
这篇文章主要为大家介绍了go语言题解LeetCode1122数组的相对排序,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-12-12 这篇文章主要介绍了Go语言io pipe源码分析详情,pipe是一个适配器,用于连接Reader和Writer,pipe的方法不多,新的写法却不少,并且结构体分两块,读写信道和结束标识,下面进入文章了解具体的内容吧2022-02-02
这篇文章主要介绍了Go语言io pipe源码分析详情,pipe是一个适配器,用于连接Reader和Writer,pipe的方法不多,新的写法却不少,并且结构体分两块,读写信道和结束标识,下面进入文章了解具体的内容吧2022-02-02 下面小编就为大家分享一篇Golang 探索对Goroutine的控制方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2017-12-12
下面小编就为大家分享一篇Golang 探索对Goroutine的控制方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2017-12-12 这篇文章主要为大家介绍了Go中的新增对模糊测试的支持,文中还包含了一些功能实验性测试分析有需要的朋友可以借鉴参考下,希望能够有所帮助2022-03-03
这篇文章主要为大家介绍了Go中的新增对模糊测试的支持,文中还包含了一些功能实验性测试分析有需要的朋友可以借鉴参考下,希望能够有所帮助2022-03-03 今天我们来聊聊golang是如何进行垃圾回收的,我们知道,目前各语言进行垃圾回收的方法有很多,如引用计数、标记清除、分代回收、三色标记等,各种方式都有其特点,文中介绍的非常详细,感兴趣的小伙伴跟着小编一起学习吧2023-07-07
今天我们来聊聊golang是如何进行垃圾回收的,我们知道,目前各语言进行垃圾回收的方法有很多,如引用计数、标记清除、分代回收、三色标记等,各种方式都有其特点,文中介绍的非常详细,感兴趣的小伙伴跟着小编一起学习吧2023-07-07 这篇文章主要为大家详细介绍了Golang如何基于泛化调用与Nacos实现Dubbo代理,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2023-04-04
这篇文章主要为大家详细介绍了Golang如何基于泛化调用与Nacos实现Dubbo代理,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2023-04-04 这篇文章主要为大家介绍了如何使用Nunu快速构建高效可靠Go应用脚手架详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-06-06
这篇文章主要为大家介绍了如何使用Nunu快速构建高效可靠Go应用脚手架详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-06-06










最新评论