
Unicode编码大揭秘
如果你是一个生活在2003年的程序员,却不了解字符、字符集、编码和Unicode这些基础知识。那你可要小心了,要是被我抓到你,我会让你在潜水艇里剥六个月洋葱来惩罚你。
这个邪恶的恐吓是Joel Spolsky在十年前首次发出的。不幸的是,很多人认为他只是在开玩笑,因此,现在仍有许多人不能完全理解Unicode,以及Unicode、UTF-8、UTF-16之间的区别。这就是我写这篇文章的原因。
言归正传,设想在一个晴朗的下午,你收到一封电子邮件,它来自一个你高中之后就失去联系的朋友,并带有一个txt格式(也称为纯文本格式)的附件。这个附件包含下面这样一串二进制bits:
0100100001000101010011000100110001001111
Email的正文是空的,这使它更加神秘。在你启动常用的文本编辑器打开这个附件之前,你有没有想过,文本编辑器是怎么将二进制形式翻译成字符的?这其中有两个关键问题:
1.字节是怎样分组的?(例如1个字节的字符和2个字节的字符)
2.一个或多个字节是怎么映射到字符上的?
这些问题的答案就在这篇文档(Character Encoding)中,大致说来,编码定义了两件事:
1.字节是怎么分组的,如8 bits或16 bits一组,这也被称作编码单元。
2.编码单元和字符之间的映射关系。例如,在ASCII码中,十进制65映射到字母A上
字符编码和字符集之间有微小的区别。不过通常它和你无关,除非你在设计一个底层的库。
ASCII码是上个世纪最流行的编码体系之一,至少在西方是这样。下图显示了ASCII码中编码单元是怎么映射到字符上的。
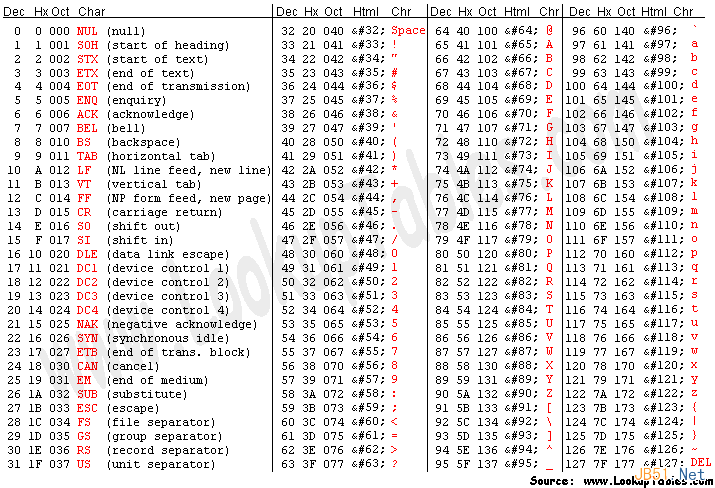 有一个即使在经验丰富的程序员中也非常常见的误解就是,纯文本使用ASCII码并且每个字符都是8 bits。
有一个即使在经验丰富的程序员中也非常常见的误解就是,纯文本使用ASCII码并且每个字符都是8 bits。
事实是,没有这样的「纯文本」。如果在内存或者硬盘中有一个你不知道编码的字符串,那你就无法翻译或者显示它。这绝对没有第二条路可选。
那么当你刚刚收到的附件没有指定编码格式的时候,计算机会如何翻译它呢?这是否意味着你就永远也读不到失去联系的老朋友想跟你说的话了呢?在我们找到答案之前,我们首先回到那个年代————那个用钱能买到的最大硬盘是29MB的时代。
历史回顾
很久以前,计算机制造商有自己的表示字符的方式。他们并不需要担心如何和其它计算机交流,并提出了各自的方式来将字形渲染到屏幕上。随着计算机越来越流行,厂商之间的竞争更加激烈,在不同的计算机体系间转换数据变得十分蛋疼,人们厌烦了这种自定义造成的混乱。
最终,计算机制造商一起制定了一个标准的方法来描述字符。他们定义使用一个字节的低7位来表示字符,并且制作了如上图所示的对照表来映射七个比特的值到一个字符上。例如,字母A是65,c是99,~是126等等, ASCII码就这样诞生了。原始的ASCII标准定义了从0到127 的字符,这样正好能用七个比特表示。不过好景不长……
为什么选择了7个比特而不是8个来表示一个字符呢?我并不关心。但是一个字节是8个比特,这意味着1个比特并没有被使用,也就是从128到255的编码并没有被制定ASCII标准的人所规定,这些美国人对世界的其它地方一无所知甚至完全不关心。
其它国家的人趁这个机会开始使用128到255范围内的编码来表达自己语言中的字符。例如,144在阿拉伯人的ASCII码中是گ,而在俄罗斯的ASCII码中是ђ。即使在美国,对于未使用区域也有各种各样的利用。IBM PC就出现了“OEM 字体”或”扩展ASCII码”,为用户提供漂亮的图形文字来绘制文本框并支持一些欧洲字符,例如英镑(£)符号。
再强调一遍,ASCII码的问题在于尽管所有人都在0-127号字符的使用上达成了一致,但对于128-255号字符却有很多很多不同的解释。你必须告诉计算机使用哪种风格的ASCII码才能正确显示128-255号的字符。
这对于北美人和不列颠群岛的人来说不算什么问题,因为无论使用哪种风格的ASCII码,拉丁字母的显示都是一样的。英国人还需要面对的问题是原始的ASCII码中不包含英镑符号,但是这个已经无关紧要了。
与此同时,在亚洲有更让人头疼的问题。亚洲语言有更多的字符和字形需要被存储,一个字节已经不够用了。所以他们开始使用两个字节来存储字符,这被称作DBCS(双字节编码方案)。在DBCS中,字符串操作变得很蛋疼,你应该怎么做str++或str–?
这些问题成为了系统开发者的噩梦。例如,MS DOS必须支持所有风格的ASCII码,因为他们想把软件卖到其他国家去。他们提出了「内码表」这一概念。例如,你需要告诉DOS(通过使用”chcp”命令)你想使用保加利亚语的内码表,它才能显示保加利亚字母。内码表的更换会应用到整个系统。这对使用多种语言工作的人来说是一个问题,因为他们必须频繁的在几个内码表之间来回切换。
尽管内码表是一个好主意,但是它不是一个简洁的解决方案,它只是一个hack技术或者说是简单的修正来让编码系统可以工作。
进入Unicode的世界
最终,美国人意识到他们应该提出一种标准方案来展示世界上所有语言中的所有字符,以便缓解程序员的痛苦和避免字符编码引发的第三次世界大战。出于这个目的,Unicode诞生了。
Unicode背后的想法非常简单,然而却被普遍的误解了。Unicode就像一个电话本,标记着字符和数字之间的映射关系。Joel称之为「神奇数字」,因为它们可能是随机指定的,而且不会给出任何解释。官方术语是码位(Code Point),总是用U+开头。理论上每种语言中的每种字符都被Unicode协会指定了一个神奇数字。例如希伯来文中的第一个字母א,是U+2135,字母A是U+0061。
Unicode并不涉及字符是怎么在字节中表示的,它仅仅指定了字符对应的数字,仅此而已。
关于Unicode的其它误解包括:Unicode支持的字符上限是65536个,Unicode字符必须占两个字节。告诉你这些的人应该去换换脑子了。
记住,Unicode只是一个用来映射字符和数字的标准。它对支持字符的数量没有限制,也不要求字符必须占两个、三个或者其它任意数量的字节。
Unicode字符是怎样被编码成内存中的字节这是另外的话题,它是被UTF(Unicode Transformation Formats)定义的。
Unicode编码
两个最流行的Unicode编码方案是UTF-8和UTF-16。让我们看看它们的细节。
UTF-8
UTF-8是一个非常惊艳的概念,它漂亮的实现了对ASCII码的向后兼容,以保证Unicode可以被大众接受。发明它的人至少应该得个诺贝尔和平奖。
在UTF-8中,0-127号的字符用1个字节来表示,使用和US-ASCII相同的编码。这意味着1980年代写的文档用UTF-8打开一点问题都没有。只有128号及以上的字符才用2个,3个或者4个字节来表示。因此,UTF-8被称作可变长度编码。
回到文章开始的问题,来自你老朋友的附件的字节流如下:
0100100001000101010011000100110001001111
这个字节流在ASCII和UTF-8中表示相同的字符:HELLO
UTF-16
另一个流行的可变长度编码方案是UTF-16,它使用2个或者4个字节来存储字符。然而,人们逐渐意识到UTF-16可能会浪费存储空间,但那是另一个话题了。
低字节序(Little Endian)和高字节序(Big Endian)
Endian读作End-ian或者Indian。这个术语的起源可以追溯到格列佛游记。(小说中,小人国为水煮蛋应该从大的一端(Big-End)剥开还是小的一端(Little-End)剥开而争论,争论的双方分别被称为“大端派”和“小端派”。)
低字节序和高字节序只是一个关于在内存中存储和读取一段字节(被称作words)的约定。这意味着当你让计算机用UTF-16把字母A(占两个字节)存在内存中时,使用哪种字节序方案决定了你把第一个字节放在第二个字节的前面还是后面。这么说有点不太容易懂,让我们来看一个例子:当你使用UTF-16存下来自你朋友的附件时,在不同的系统中它的后半部分可能是这样的:
00 68 00 65 00 6C 00 6C 00 6F(高字节序,高位字节被存在前面)
68 00 65 00 6C 00 6C 00 6F 00(低字节序,低位字节被存在前面)
字节序方案只是一个微处理器架构设计者的偏好问题,例如,Intel使用低字节序,Motorola使用高字节序。
字节顺序标记(BOM)
如果你经常要在高低字节序的系统间转换文档,并且希望区分字节序,还有一种奇怪的约定,被称作BOM。BOM是一个设计得很巧妙的字符,用来放在文档的开头告诉阅读器该文档的字节序。在UTF-16中,它是通过在第一个字节放置FE FF来实现的。在不同字节序的文档中,它会被显示成FF FE或者FE FF,清楚的把这篇文档的字节序告诉了解释器。
BOM尽管很有用,但并不是很简洁,因为还有一个类似的概念,称作「魔术字」(Magic Byte),很多年来一直被用来表明文件的格式。BOM和魔术字间的关系一直没有被清楚的定义过,因此有的解释器会搞混它们。
恭喜你读到这里,你一定是一个很有耐心的读者。
还记得文章开头的问题吗,既然没有「纯文本」文件这回事,那你的文本编辑器和浏览器为什么每次都能正确的显示内容呢?答案是,那些软件欺骗了你,这也是为什么那么多人对编码一无所知。当软件不能确定编码的时候,它会猜测。大部分时候,它会猜测是否是涵盖了ASCII码的UTF-8,还是ISO-8859-1,也有可能猜其他能想到的任意字符集。因为英文中使用的拉丁字母表在几乎所有的字符集中都能显示,包括UTF-8,所以即使编码猜错了,英文字母看起来也是正确的。
但是,如果你在浏览网页时看到�符号,这意味着这个网页的编码不是你的浏览器猜测的那个。这时你可以点开浏览器的查看——>字符编码菜单来尝试不同的编码。
总结
如果你没时间读整篇文章或者你仅仅是略读了一下前面的内容。那请你确保你能理解下面的几条:
这个世界上从来没有纯文本这回事,如果你想读出一个字符串,你必须知道它的编码。
Unicode是一个简单的标准,用来把字符映射到数字上。Unicode协会的人会帮你处理所有幕后的问题,包括为新字符指定编码。
Unicode并不告诉你字符是怎么编码成字节的。这是被编码方案决定的,通过UTF来指定。
还有最重要的:
永远记得通过Content-Type或者meta charset标签来显式指定你的文档的编码。这样浏览器就不需要猜测你使用的编码了,他们会准确的使用你指定的编码来渲染文档。
相关文章
 Studio 3T是一款非常不错的MongoDB数据库GUI连接工具,由原MongoChef改名升级,可以为大家更优质的网页设计、代码输入、编程管理等功能,这篇文章给大家分享关于Studio3T试用时间到期的问题,如何用脚本重新设置时间的失败问题,感兴趣的朋友一起看看吧2022-08-08
Studio 3T是一款非常不错的MongoDB数据库GUI连接工具,由原MongoChef改名升级,可以为大家更优质的网页设计、代码输入、编程管理等功能,这篇文章给大家分享关于Studio3T试用时间到期的问题,如何用脚本重新设置时间的失败问题,感兴趣的朋友一起看看吧2022-08-08 本文主要介绍微信公众平台开发群发信息,这里整理了详细的资料来说明微信公共平台群发信息的流程,有需要的小伙伴可以参考下2016-09-09
本文主要介绍微信公众平台开发群发信息,这里整理了详细的资料来说明微信公共平台群发信息的流程,有需要的小伙伴可以参考下2016-09-09 找了一个和谐工具,运行和谐工具后,看IDM关于那里,已经是全功能版本,美中不足的是,IDM运行一段时间,就会弹出neg窗口,说文件被修改,最好是去官网下载原版的提示,就这个问题怎么处理呢?对IDM 6.40.11.2 弹窗的解决思路感兴趣的朋友跟随小编一起看看吧2023-01-01
找了一个和谐工具,运行和谐工具后,看IDM关于那里,已经是全功能版本,美中不足的是,IDM运行一段时间,就会弹出neg窗口,说文件被修改,最好是去官网下载原版的提示,就这个问题怎么处理呢?对IDM 6.40.11.2 弹窗的解决思路感兴趣的朋友跟随小编一起看看吧2023-01-01
superset在linux和windows下的安装和部署详细教程
Superset 是 Airbnb开源的数据探查与可视化平台,是个轻量级的BI工具,开发者可以在其开源代码上根据需要进行二次开发。这篇文章主要介绍了superset在linux和windows下的安装和部署详细教程,需要的朋友可以参考下2020-10-10 这篇文章主要介绍了使用curl命令行模拟登录WordPress的方法,本文通过图文实例相结合给大家介绍的非常详细,需要的朋友可以参考下2019-11-11
这篇文章主要介绍了使用curl命令行模拟登录WordPress的方法,本文通过图文实例相结合给大家介绍的非常详细,需要的朋友可以参考下2019-11-11
如何将服务器上的python代码通过QQ发送回传信息(附实现方法)
这篇文章主要介绍了我将服务器上的python代码通过QQ发送回传信息(附实现方法),本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-05-05 这篇文章介绍了Github创建个人访问Tokens令牌的方法,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-04-04
这篇文章介绍了Github创建个人访问Tokens令牌的方法,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-04-04 Coder是VS Code的Web IDE,分Code Server 和 Coder,Code Server安装在服务器上,通过浏览器打开地址后可以使用一个web版的VS Code,也就是Coder,但VS Code的插件无法使用。这篇文章主要介绍了VSCode Web IDE Coder 安装及使用,需要的朋友可以参考下2021-12-12
Coder是VS Code的Web IDE,分Code Server 和 Coder,Code Server安装在服务器上,通过浏览器打开地址后可以使用一个web版的VS Code,也就是Coder,但VS Code的插件无法使用。这篇文章主要介绍了VSCode Web IDE Coder 安装及使用,需要的朋友可以参考下2021-12-12 这篇文章主要介绍了Github代码常用指令(小结),小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2019-08-08
这篇文章主要介绍了Github代码常用指令(小结),小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2019-08-08 Hadoop是一个开源的可运行于大规模集群上的分布式文件系统和运行处理基础框架,Spark是UC Berkeley AMPLab开发的是一种计算框架,分布式资源工作交由集群管理软件(Mesos、YARN),本文介绍Hadoop与Spark大数据框架知识,感兴趣的朋友一起看看吧2022-04-04
Hadoop是一个开源的可运行于大规模集群上的分布式文件系统和运行处理基础框架,Spark是UC Berkeley AMPLab开发的是一种计算框架,分布式资源工作交由集群管理软件(Mesos、YARN),本文介绍Hadoop与Spark大数据框架知识,感兴趣的朋友一起看看吧2022-04-04










最新评论