
自增长键列统计信息的处理方法
这篇文章通过文字代码的形式讲解了如何处理用自增长键列的统计信息。我们都知道,在SQL Server里每个统计信息对象都有关联的直方图。直方图用多个步长描述指定列数据分布情况。在一个直方图里,SQL Server最大支持200的步长,但当你查询的数据范围在直方图最后步长后,这是个问题。我们来看下面的代码,重现这个情形:
-- Create a simple orders table
CREATE TABLE Orders
(
OrderDate DATE NOT NULL,
Col2 INT NOT NULL,
Col3 INT NOT NULL
)
GO
-- Create a Non-Unique Clustered Index on the table
CREATE CLUSTERED INDEX idx_CI ON Orders(OrderDate)
GO
-- Insert 31465 rows from the AdventureWorks2008r2 database
INSERT INTO Orders (OrderDate, Col2, Col3) SELECT OrderDate, CustomerID, TerritoryID FROM AdventureWorks2008R2.Sales.SalesOrderHeader
GO
-- Rebuild the Clustered Index, so that we get fresh statistics.
-- The last value in the Histogram is 2008-07-31.
ALTER INDEX idx_CI ON Orders REBUILD
GO
-- Insert 200 additional rows *after* the last step in the Histogram
INSERT INTO Orders (OrderDate, Col2, Col3)
VALUES ('20100101', 1, 1)
GO 200
在索引重建后,我们再看下直方图,我们发现最后步进的值是2008-07-31。
DBCC SHOW_STATISTICS('dbo.Orders', 'idx_CI') WITH HISTOGRAM

你已经看到,在最后步进到表里后,我们插入了200条额外记录。这样的话,直方图并没有真实反馈实际的数据分布情况,但SQL Server还是要进行基数计算。我们现在来看看在不同版本里SQL Server是如何处理这个问题的。
SQL Server 2005 SP1- SQL Server 2012
在SQL Server 2014之前,基数计算对此问题的处理非常简单:SQL Server估计行数为1,你可以从下面的图片里看到。
点击工具栏的显示包含实际的执行计划,并执行如下查询:
SELECT * FROM dbo.Orders WHERE OrderDate='2010-01-01'

自SQL Server 2005 SP1起,查询优化器可以标记1列为自增长(Ascending)来克服刚才介绍的限制。如果你用自增长列值更新了统计信息对象3次,那列就会被标记为自增长列。为了看有没有列标记为自增长,你可以使用跟踪标记2388。当你启用这个跟踪标记,DBCC SHOW_STATISTICS的输出就改变了,有额外列返回。
DBCC TRACEON(2388)
DBCC SHOW_STATISTICS('dbo.Orders', 'idx_CI')

现在下面的代码更新统计信息3次,每次用自增长键列值在我们聚集索引末尾插入行。
-- => 1st update the Statistics on the table with a FULLSCAN
UPDATE STATISTICS Orders WITH FULLSCAN
GO
-- Insert 200 additional rows *after* the last step in the Histogram
INSERT INTO Orders (OrderDate, Col2, Col3)
VALUES ('20100201', 1, 1)
GO 200
-- => 2nd update the Statistics on the table with a FULLSCAN
UPDATE STATISTICS Orders WITH FULLSCAN
GO
-- Insert 200 additional rows *after* the last step in the Histogram
INSERT INTO Orders (OrderDate, Col2, Col3)
VALUES ('20100301', 1, 1)
GO 200
-- => 3rd update the Statistics on the table with a FULLSCAN
UPDATE STATISTICS Orders WITH FULLSCAN
GO
然后,当我们执行DBCC SHOW_STATISTICS命令,你会看到SQL Server已讲那列标记为Ascending。
DBCC TRACEON(2388)
DBCC SHOW_STATISTICS('dbo.Orders', 'idx_CI')

现在当你再次执行查询不是直方图范围的数据时,没有任何改变。为了使用标记为自增长键列,你要启用另外一个跟踪标记-2389。如果你启用这个跟踪标记,查询优化器就是密度向量(Density Vector)来进行基数计算。
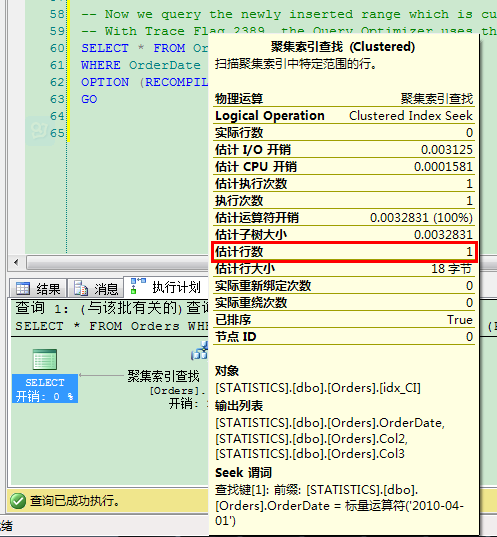
-- Now we query the newly inserted range which is currently not present in the Histogram. -- With Trace Flag 2389, the Query Optimizer uses the Density Vector to make the Cardinality Estimation. SELECT * FROM Orders WHERE OrderDate = '20100401' OPTION (RECOMPILE, QUERYTRACEON 2389) GO
来看下现在的表密度:
DBCC TRACEOFF(2388)
DBCC SHOW_STATISTICS('dbo.Orders', 'idx_CI')

现在的表密度是0.0008873115,因此查询优化器的估计行数是28.4516:0.0008873115*(32265-200)。

这虽然不是最好的结果,但比估计行数1好很多!
(这里有问题,我本地是SQL Server 2008r2,测试估计行数还是1,不知原因,望知道的朋友解释下,多谢!)
SQL Server 2014
在SQL Server 2014引入的一个新功能是新基数计算。新基数计算对于自增长键问题的处理非常简单:默认不使用任何跟踪标记,来使用统计信息对象的密度向量来进行基数计算。下面查询启用2312跟踪标记的基数计算来运行同个查询。
1 -- With the new Cardinality Estimator SQL Server estimates 28.4516 rows at the Clustered Index Seek operator. 2 SELECT * FROM Orders 3 WHERE OrderDate = '20100401' 4 OPTION (RECOMPILE, QUERYTRACEON 2312) 5 GO
我们来看这里的基数计算,你会看到查询优化器再次估计行数是28.4516,但这一次没表上自增长。这是SQL Server 2014的自带功能。
(SQL Server 2014测试失败,估计行数也是1……)
在这篇文章,我向你展示了SQL Server的查询优化器如何处理自增长键问题。在SQL Server 2014之前,你需要启用2389跟踪标记来获得更好的基数计算——这样的话那列会标记为自增长(ascending)。SQL Server 2014,查询优化器默认就使用密度向量来进行基数计算,这样就方便很多。我希望你对此有所收获,在SQL Server里如何处理自增长键列问题你会有更好的想法。
希望对大家有所启迪,谢谢。
相关文章

SQL语句过滤条件放在on与where子句中的区别和联系浅析
在写SQL语句的时候,我们经常会用到各种表连接,还有各种分组聚合函数,下面这篇文章主要给大家介绍了关于SQL语句过滤条件放在on与where子句中的区别和联系,需要的朋友可以参考下2022-09-09 这篇文章主要介绍了图书管理系统的sqlserver数据库设计示例,文中通过E_R图、数据字典、数据库脚本代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-08-08
这篇文章主要介绍了图书管理系统的sqlserver数据库设计示例,文中通过E_R图、数据字典、数据库脚本代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-08-08 这篇文章主要探讨Sql Server中的declare基本知识,实战探讨主要来源于触发器的Demo,本文给大家介绍的非常详细,感兴趣的朋友跟随小编一起看看吧2024-07-07
这篇文章主要探讨Sql Server中的declare基本知识,实战探讨主要来源于触发器的Demo,本文给大家介绍的非常详细,感兴趣的朋友跟随小编一起看看吧2024-07-07
CentOS安装SQL Server vNext CTP1教程
这篇文章主要为大家详细介绍了CentOS上安装SQL Server vNext CTP1的相关过程,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2016-11-11 在SQL中,模糊查询是一种通过匹配字符串中的一部分或关键字来查询数据的方法,本文主要介绍了SQL实现模糊查询的四种方法小结,具有一定的参考价值,感兴趣的可以了解一下2024-03-03
在SQL中,模糊查询是一种通过匹配字符串中的一部分或关键字来查询数据的方法,本文主要介绍了SQL实现模糊查询的四种方法小结,具有一定的参考价值,感兴趣的可以了解一下2024-03-03 最近处理数据的时候遇到了个问题,需要利用sql删除表格的前1000行数据,尝试过后这里给大家分享下过程,所以下面这篇文章主要给大家介绍了关于sql server删除前1000行数据的相关资料,需要的朋友可以参考下2021-08-08
最近处理数据的时候遇到了个问题,需要利用sql删除表格的前1000行数据,尝试过后这里给大家分享下过程,所以下面这篇文章主要给大家介绍了关于sql server删除前1000行数据的相关资料,需要的朋友可以参考下2021-08-08 本文详细讲解了SQL Server中的排名函数与分析函数,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-05-05
本文详细讲解了SQL Server中的排名函数与分析函数,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-05-05 这篇文章主要介绍了Sql Server中的视图介绍,本文讲解了视图的定义、视图的作用、创建视图实例、删除修改视图等内容,需要的朋友可以参考下2015-01-01
这篇文章主要介绍了Sql Server中的视图介绍,本文讲解了视图的定义、视图的作用、创建视图实例、删除修改视图等内容,需要的朋友可以参考下2015-01-01 在使用SQL server新建数据库后,接下来我们就需要新建表了,下面这篇文章主要给大家介绍了关于在sqlserver中创建表的相关资料,文中通过示例代码介绍的非常详细,需要的朋友可以参考下2022-04-04
在使用SQL server新建数据库后,接下来我们就需要新建表了,下面这篇文章主要给大家介绍了关于在sqlserver中创建表的相关资料,文中通过示例代码介绍的非常详细,需要的朋友可以参考下2022-04-04 18456是因密码或用户名错误而使身份验证失败,如果用户名密码正确,则该登录名没有连接数据库引擎权限,本文就来介绍一下解决方法,具有一定的参考价值,感兴趣的可以了解一下2023-10-10
18456是因密码或用户名错误而使身份验证失败,如果用户名密码正确,则该登录名没有连接数据库引擎权限,本文就来介绍一下解决方法,具有一定的参考价值,感兴趣的可以了解一下2023-10-10










最新评论