
node+experss实现爬取电影天堂爬虫
上周写了一个node+experss的爬虫小入门。今天继续来学习一下,写一个爬虫2.0版本。
这次我们不再爬博客园了,咋玩点新的,爬爬电影天堂。因为每个周末都会在电影天堂下载一部电影来看看。
talk is cheap,show me the code!
抓取页面分析
我们的目标:
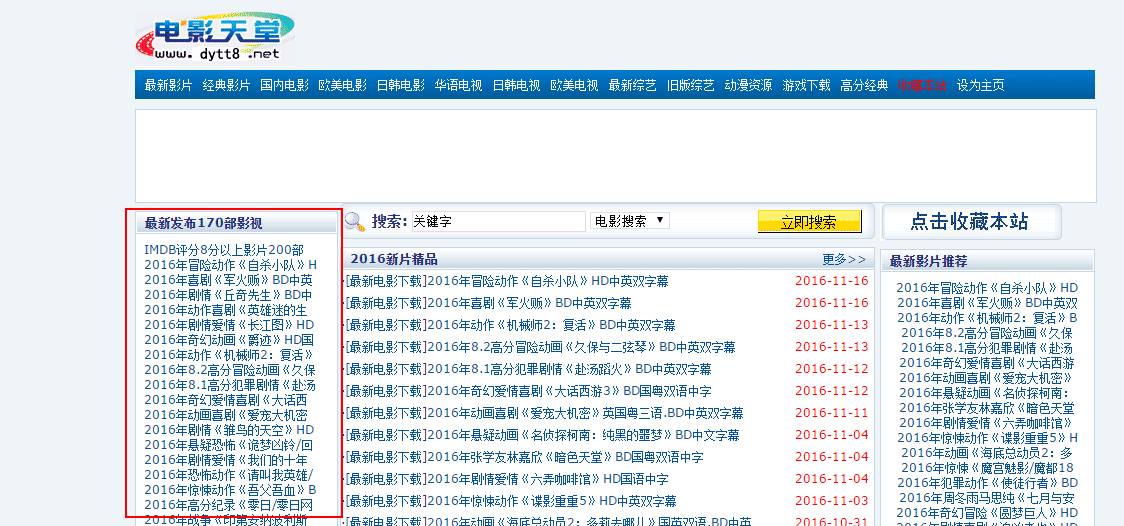
1、抓取电影天堂首页,获取左侧最新电影的169条链接
2、抓取169部新电影的迅雷下载链接,并且并发异步抓取。
具体分析如下:
1、我们不需要抓取迅雷的所有东西,只需要下载最新发布的电影即可,比如下面的左侧栏。一共有170个,除去第一个(因为第一个里面有200部电影),一共有169部电影。
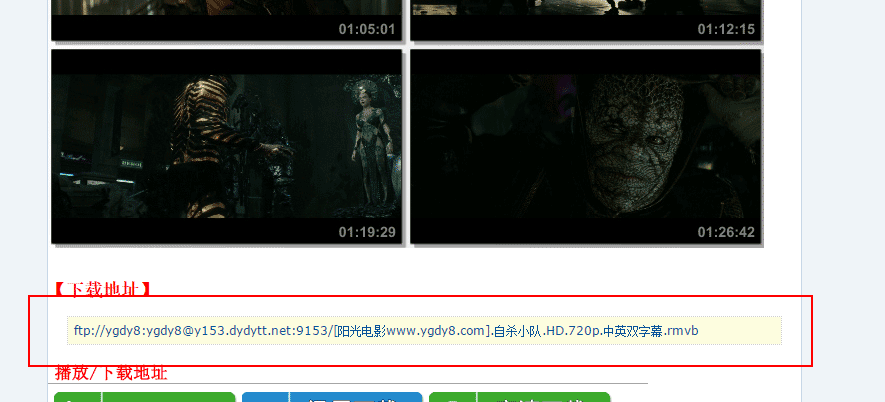
2、除了抓取首页的东西,我们还要抓取点进去之后,每部电影的迅雷下载链接
环境搭建
1、需要的东西:node环境、express、cherrio 这三个都是上一篇文章有介绍的,所以这里不再做介绍:点击查看
2、需要安装的新东西:
superagent:
作用:跟request差不多,我们可以用它来获取get/post等请求,并且可以设置相关的请求头信息,相比较使用内置的模块,要简单很多。
用法:
var superagent = require('superagent');
superagent
.get('/some-url')
.end(function(err, res){
// Do something
});
superagent-charset:
作用:解决编码问题,因为电影天堂的编码是gb2312,爬取下来的中文会乱码掉。
用法:
var superagent = require('superagent');
var charset = require('superagent-charset');
charset(superagent);
superagent
.get('/some-url')
.charset('gb2312') //这里设置编码
.end(function(err, res){
// Do something
});
async:
作用:Async是一个流程控制工具包,提供了直接而强大的异步功能,在这里作为处理并发来调用。
用法:这里需要用到的是:async.mapLimit(arr, limit, iterator, callback)
mapLimit可以同时发起多个异步操作,然后一起等待callback的返回,返回一个就再发起下一个。
arr是一个数组,limit并发数,将arr中的每一项依次拿给iterator去执行,执行结果传给最后的callback
eventproxy:
作用:eventproxy 起到了计数器的作用,它来帮你管理到底异步操作是否完成,完成之后,它会自动调用你提供的处理函数,并将抓取到的数据当参数传过来。
例如我首先抓取到电影天堂首页侧栏的链接,才可以接着抓取链接里面的内容。具体作用可以点这里
用法:
var ep = new EventProxy();
ep.after('got_file', files.length, function (list) {
// 在所有文件的异步执行结束后将被执行
// 所有文件的内容都存在list数组中
});
for (var i = 0; i < files.length; i++) {
fs.readFile(files[i], 'utf-8', function (err, content) {
// 触发结果事件
ep.emit('got_file', content);
});
}
//注意got_file这两个名字必须对应
开始爬虫
主要的程序在app.js这里,所以看的话可以主要看app.js即可
1、首先定义一些全局变量,该引入的库引进来
var cheerio = require('cheerio'); //可以像jquer一样操作界面
var charset = require('superagent-charset'); //解决乱码问题:
var superagent = require('superagent'); //发起请求
charset(superagent);
var async = require('async'); //异步抓取
var express = require('express');
var eventproxy = require('eventproxy'); //流程控制
var ep = eventproxy();
var app = express();
var baseUrl = 'http://www.dytt8.net'; //迅雷首页链接
var newMovieLinkArr=[]; //存放新电影的url
var errLength=[]; //统计出错的链接数
var highScoreMovieArr=[] //高评分电影
2、开始爬取首页迅雷首页:
//先抓取迅雷首页
(function (page) {
superagent
.get(page)
.charset('gb2312')
.end(function (err, sres) {
// 常规的错误处理
if (err) {
console.log('抓取'+page+'这条信息的时候出错了')
return next(err);
}
var $ = cheerio.load(sres.text);
// 170条电影链接,注意去重
getAllMovieLink($);
highScoreMovie($);
/*
*流程控制语句
*当首页左侧的链接爬取完毕之后,我们就开始爬取里面的详情页
*/
ep.emit('get_topic_html', 'get '+page+' successful');
});
})(baseUrl);
在这里,我们先抓取首页的东西,把首页抓取到的页面内容传给 getAllMovieLink和highScoreMovie这两个函数来处理,
getAllMovieLink获取到了左侧栏除了第1部的电影的169电影。
highScoreMovie为左侧栏第一个链接,里面的都是评分比较高的电影。
上面的代码中,我们弄了一个计数器,当它执行完之后,我们就可以执行与‘get_topic_html‘名字对应的流程了,从而可以保证在执行完首页的抓取工作之后,再执行次级页面的抓取工作。
ep.emit('get_topic_html', 'get '+page+' successful');
highScoreMovie方法如下,其实我们这里的作用不大,只是我统计一下高评分电影首页的信息,懒的继续抓取了
//评分8分以上影片 200余部!,这里只是统计数据,不再进行抓取
function highScoreMovie($){
var url='http://www.dytt8.net'+$('.co_content2 ul a').eq(0).attr('href');
console.log(url);
superagent
.get(url)
.charset('gb2312')
.end(function (err, sres) {
// 常规的错误处理
if (err) {
console.log('抓取'+url+'这条信息的时候出错了')
}
var $ = cheerio.load(sres.text);
var elemP=$('#Zoom p');
var elemA=$('#Zoom a');
for (var k = 1; k < elemP.length; k++) {
var Hurl=elemP.eq(k).find('a').text();
if(highScoreMovieArr.indexOf(Hurl) ==-1){
highScoreMovieArr.push(Hurl);
};
}
});
}
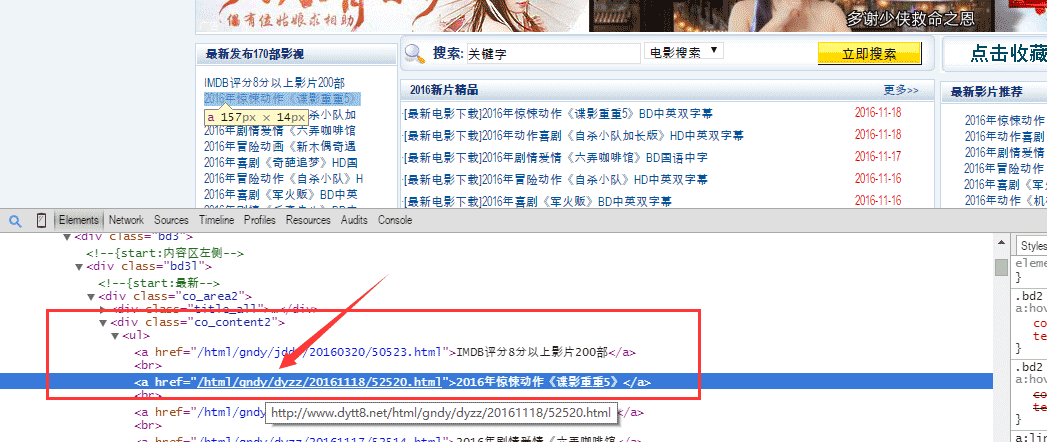
3、分离出左侧栏的信息,
如下图,首页中,详情页的链接都在这里$('.co_content2 ul a')。
因此我们将左侧栏这里的详情页链接都遍历出来,保存在一个newMovieLinkArr这个数组里面。
getAllMovieLink方法如下:
// 获取首页中左侧栏的所有链接
function getAllMovieLink($){
var linkElem=$('.co_content2 ul a');
for(var i=1;i<170;i++){
var url='http://www.dytt8.net'+linkElem.eq(i).attr('href');
// 注意去重
if(newMovieLinkArr.indexOf(url) ==-1){
newMovieLinkArr.push(url);
};
}
}
4、对获取到的电影详情页进行爬虫,提取有用信息,比如电影的下载链接,这个是我们所关心的。
// 命令 ep 重复监听 emit事件(get_topic_html),当get_topic_html爬取完毕之后执行
ep.after('get_topic_html', 1, function (eps) {
var concurrencyCount = 0;
var num=-4; //因为是5个并发,所以需要减4
// 利用callback函数将结果返回去,然后在结果中取出整个结果数组。
var fetchUrl = function (myurl, callback) {
var fetchStart = new Date().getTime();
concurrencyCount++;
num+=1
console.log('现在的并发数是', concurrencyCount, ',正在抓取的是', myurl);
superagent
.get(myurl)
.charset('gb2312') //解决编码问题
.end(function (err, ssres) {
if (err) {
callback(err, myurl + ' error happened!');
errLength.push(myurl);
return next(err);
}
var time = new Date().getTime() - fetchStart;
console.log('抓取 ' + myurl + ' 成功', ',耗时' + time + '毫秒');
concurrencyCount--;
var $ = cheerio.load(ssres.text);
// 对获取的结果进行处理函数
getDownloadLink($,function(obj){
res.write('<br/>');
res.write(num+'、电影名称--> '+obj.movieName);
res.write('<br/>');
res.write('迅雷下载链接--> '+obj.downLink);
res.write('<br/>');
res.write('详情链接--> <a href='+myurl+' target="_blank">'+myurl+'<a/>');
res.write('<br/>');
res.write('<br/>');
});
var result = {
movieLink: myurl
};
callback(null, result);
});
};
// 控制最大并发数为5,在结果中取出callback返回来的整个结果数组。
// mapLimit(arr, limit, iterator, [callback])
async.mapLimit(newMovieLinkArr, 5, function (myurl, callback) {
fetchUrl(myurl, callback);
}, function (err, result) {
// 爬虫结束后的回调,可以做一些统计结果
console.log('抓包结束,一共抓取了-->'+newMovieLinkArr.length+'条数据');
console.log('出错-->'+errLength.length+'条数据');
console.log('高评分电影:==》'+highScoreMovieArr.length);
return false;
});
});
首先是async.mapLimit对所有详情页做了一个并发,并发数为5,然后再爬取详情页,爬详情页的过程其实和爬首页的过程是一样的,所以这里不做过多的介绍,然后将有用的信息打印到页面上。
5、执行命令之后的图如下所示:
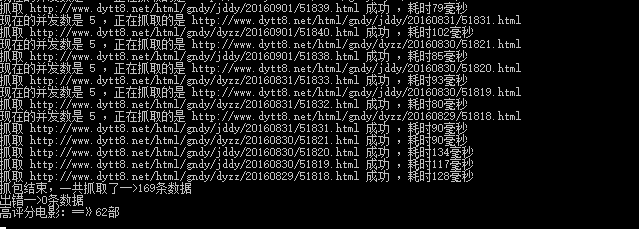
浏览器界面:
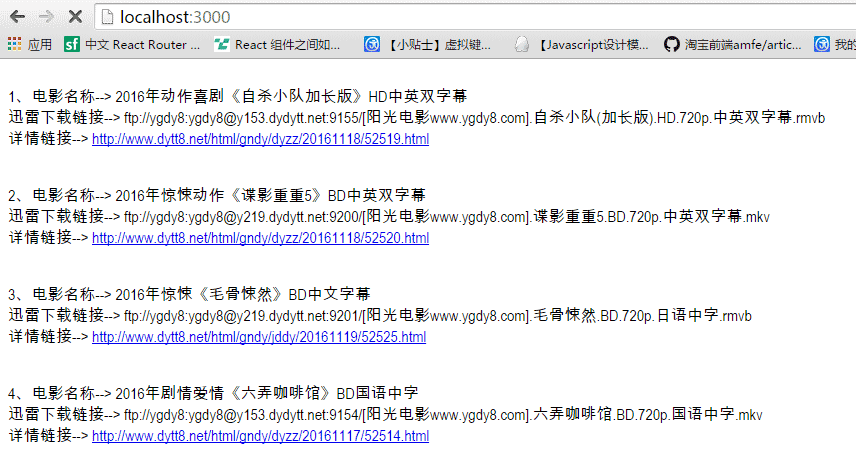
这样,我们爬虫的稍微升级版就就完成啦。可能文章写的不是很清楚,我已经把代码上传到了github上,可以将代码运行一遍,这样的话比较容易理解。后面如果有时间,可能会再搞一个爬虫的升级版本,比如将爬到的信息存入mongodb,然后再在另一个页面展示。而爬虫的程序加个定时器,定时去抓取。
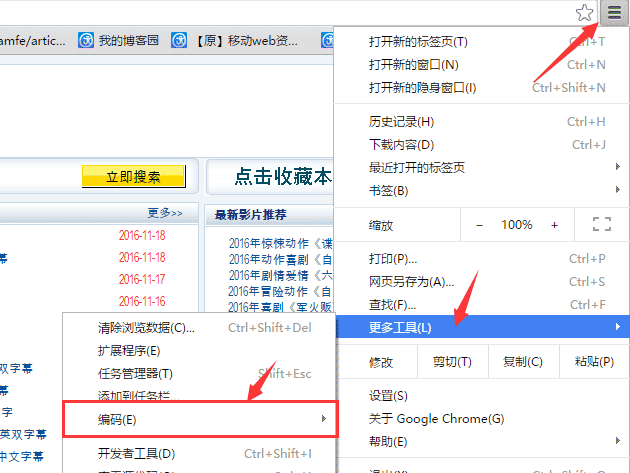
备注:如果运行在浏览器中的中文乱码的话,可以将谷歌的编码设置为utf-8来解决;
代码地址:https://github.com/xianyulaodi/mySpider2
有误之处,欢迎指出
相关文章
 这篇文章主要介绍了使用Node.js构建微服务,将介绍微服务架构、优势以及如何使用Node.js开发微服务,需要的朋友可以参考下2022-08-08
这篇文章主要介绍了使用Node.js构建微服务,将介绍微服务架构、优势以及如何使用Node.js开发微服务,需要的朋友可以参考下2022-08-08 本篇文章主要介绍了mac下的nodejs环境安装的步骤,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-05-05
本篇文章主要介绍了mac下的nodejs环境安装的步骤,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-05-05 这篇文章主要介绍了express+multer上传图片打开乱码问题及解决方案,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-09-09
这篇文章主要介绍了express+multer上传图片打开乱码问题及解决方案,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-09-09 这篇文章主要给大家介绍了关于Mongoose实现虚拟字段查询的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面跟着小编来一起学习学习吧。2017-08-08
这篇文章主要给大家介绍了关于Mongoose实现虚拟字段查询的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面跟着小编来一起学习学习吧。2017-08-08 这篇文章主要介绍了node.js中的fs.openSync方法使用说明,本文介绍了fs.openSync方法说明、语法、接收参数、使用实例和实现源码,需要的朋友可以参考下2014-12-12
这篇文章主要介绍了node.js中的fs.openSync方法使用说明,本文介绍了fs.openSync方法说明、语法、接收参数、使用实例和实现源码,需要的朋友可以参考下2014-12-12 这篇文章主要介绍了node.js连接mysql与基本用法,结合实例形式分析了nodejs中mysql模块的安装、引入、创建连接、sql语句执行等相关操作技巧,需要的朋友可以参考下2019-01-01
这篇文章主要介绍了node.js连接mysql与基本用法,结合实例形式分析了nodejs中mysql模块的安装、引入、创建连接、sql语句执行等相关操作技巧,需要的朋友可以参考下2019-01-01 本文主要介绍了websocket结合node.js实现双向通信的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-02-02
本文主要介绍了websocket结合node.js实现双向通信的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-02-02 这篇文章主要给大家介绍了关于Windows7系统下如何安装nodejs16以上版本的相关资料,很多时候node.js的版本存在兼容,文中通过图文介绍的非常详细,需要的朋友可以参考下2023-07-07
这篇文章主要给大家介绍了关于Windows7系统下如何安装nodejs16以上版本的相关资料,很多时候node.js的版本存在兼容,文中通过图文介绍的非常详细,需要的朋友可以参考下2023-07-07 本文主题是使用node来搭建最简单的web服务器,其后可以自己根据需要深入了解,目前在开发过程中可以用来模拟与服务器进行简单的交互,比如返回的资源控制等。需要的朋友可以参考学习,下面来一起看看吧。2017-02-02
本文主题是使用node来搭建最简单的web服务器,其后可以自己根据需要深入了解,目前在开发过程中可以用来模拟与服务器进行简单的交互,比如返回的资源控制等。需要的朋友可以参考学习,下面来一起看看吧。2017-02-02 这篇文章主要介绍了node.js微信小程序配置消息推送的实现,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2019-02-02
这篇文章主要介绍了node.js微信小程序配置消息推送的实现,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2019-02-02










最新评论