

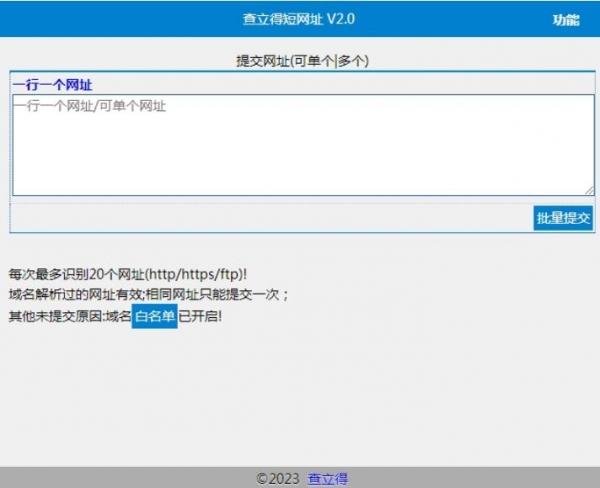
 查立得短网址源码 v2.0
查立得短网址源码 v2.031KB / 12-16
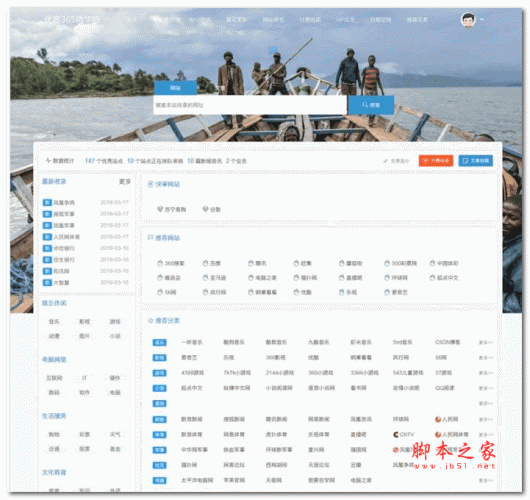 优客365精华版商业版 v1.1.6
优客365精华版商业版 v1.1.615MB / 11-22
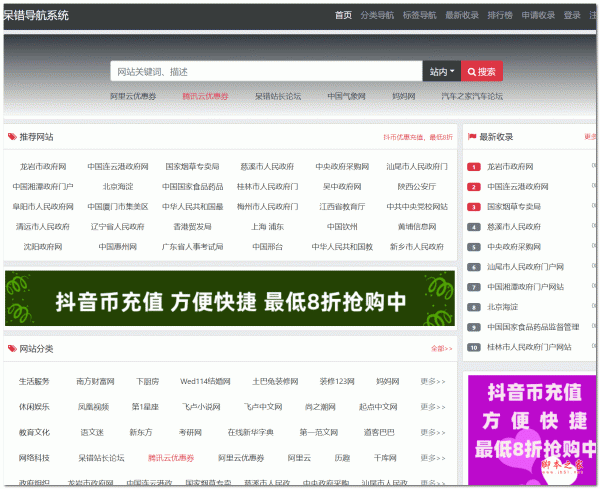 PHP呆错分类导航系统源码 v1.9.8
PHP呆错分类导航系统源码 v1.9.82.97MB / 09-07
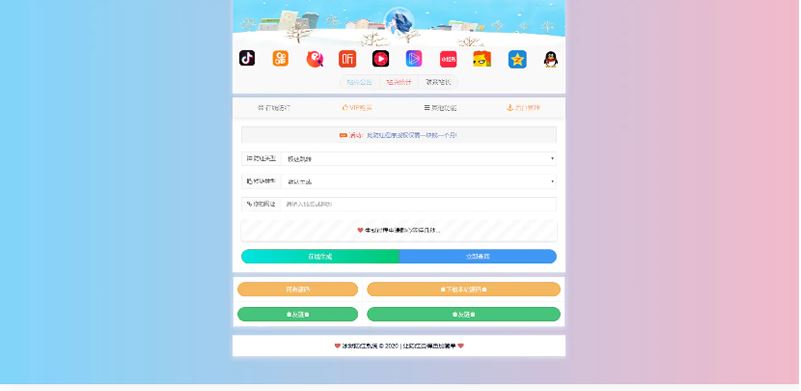 冰狱防红系统解密去授权版PHP源码(码支付+易支付接口正常)
冰狱防红系统解密去授权版PHP源码(码支付+易支付接口正常)5.28MB / 03-18
 魔众短链接系统 v4.9.0
魔众短链接系统 v4.9.012.3MB / 08-14
 彩虹网盘外链程序PHP源码 V5.1
彩虹网盘外链程序PHP源码 V5.1312KB / 09-04
 Sphinx全文检索引擎 for Mac v3.3.1
Sphinx全文检索引擎 for Mac v3.3.18.3MB / 08-21
 莲花单页PHP导航网站源码 v2.0
莲花单页PHP导航网站源码 v2.0928KB / 05-26
 全新国际网址导航源码 v5.8
全新国际网址导航源码 v5.85.9MB / 05-09
 要搜聚合搜索源码 V1.0
要搜聚合搜索源码 V1.016.5MB / 10-16










-

162100 网址导航3号 v9.5 搜索链接 / 12.7MB
-
查立得短网址源码 v2.0 搜索链接 / 31KB
-
魔众短链接系统 v4.9.0 搜索链接 / 12.3MB
-
PHP呆错分类导航系统源码 v1.9.8 搜索链接 / 2.97MB
-
莲花单页PHP导航网站源码 v2.0 搜索链接 / 928KB
-
全新国际网址导航源码 v5.8 搜索链接 / 5.9MB
-
优客365网站导航源码 开源版 v1.5.6 搜索链接 / 7MB
-
火端搜索源码 谷歌版 V2.1 搜索链接 / 255KB
-
优客365精华版商业版 v1.1.6 搜索链接 / 15MB
-
冰狱防红系统解密去授权版PHP源码(码支付+易支付接口正常) 搜索链接 / 5.28MB



详情介绍
分词系统是基于字符串匹配的分词方法 ,这种方法又叫做机械分词方法,它是按照一定的策略将待分析的汉字串与 一个“充分大的”机器词典中的词条进行配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。按照扫描方向的不同,串匹配分词方法可以分为正向匹配 和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与 标注相结合的一体化方法。常用的几种机械分词方法如下:
1)正向最大匹配法(由左到右的方向);
2)逆向最大匹配法(由右到左的方向);
3)最少切分(使每一句中切出的词数最小)。
还可以将上述各种方法相互组合,例如,可以将正向最大匹配方法和逆向最大匹配方法结合起来构成双向匹配法。由于汉语单字成词的特点,正向最小匹配和逆向 最小匹配一般很少使用。一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。统计结果表明,单纯使用正向最大匹配的错误率为1/169, 单纯使用逆向最大匹配的错误率为1/245。但这种精度还远远不能满足实际的需要。实际使用的分词系统,都是把机械分词作为一种初分手段,还需通过利用各 种其它的语言信息来进一步提高切分的准确率。
一种方法是改进扫描方式,称为特征扫描或标志切分,优先在待分析字符串中识别和切分出一些带有明 显特征的词,以这些词作为断点,可将原字符串分为较小的串再来进机械分词,从而减少匹配的错误率。另一种方法是将分词和词类标注结合起来,利用丰富的词类 信息对分词决策提供帮助,并且在标注过程中又反过来对分词结果进行检验、调整,从而极大地提高切分的准确率。
下载地址
人气源码

 v1.3 免费版")

")
")
) v10.0 PHP版")



相关文章
-
查立得短网址源码 v2.0
33KB代码(PHP+MYSQL)实现短网址功能前后端都登陆,相对第一版代码已重构,欢迎需要的朋友下载使用...
-
优客365精华版商业版 v1.1.6
优客365精华版商业版功能很强大,可以说应该是目前网上非常强大的导航程序之一。欢迎需要的朋友下载使用...
-
PHP呆错分类导航系统源码 v1.9.8
呆错导航系统是一款真正免费、开源的PHP分类导航程序,无任何加密代码、源代码完全公开、安全有保障、无后门隐患,欢迎下载使用...
-
冰狱防红系统解密去授权版PHP源码(码支付+易支付接口正常)
防红短链接,冰狱防红系统解密去授权版本源码[码支付+易支付接口正常],数据库无需手动配置访问下面地址配置即可,需要的朋友快来下载使用吧...
-
魔众短链接系统 v4.9.0
魔众短链接系统采用PHP+Mysql架构,是一款对SEO非常友好、功能全面、安全稳定、支持多终端展示,帮您快速创建现代化的企业形象...
-
彩虹网盘外链程序PHP源码 V5.1
彩虹网盘外链是一款PHP网盘与外链分享程序,支持所有格式文件的上传,这不仅仅是一个网盘,更是一个图床或是音乐在线试听网站,需要的朋友快来下载吧...
-
Sphinx全文检索引擎 for Mac v3.3.1
Sphinx是一个基于SQL的全文检索引擎,可以结合MySQL,PostgreSQL做全文搜索,它可以提供比数据库本身更专业的搜索功能。欢迎下载使用...
-
莲花单页PHP导航网站源码 v2.0
莲花单页导航是一个以PHP+MySQL进行开发的PHP导航网站源码。欢迎下载使用...
-
全新国际网址导航源码 v5.8
国际网址导航系统是一个以PHP+MySQL进行开发的导航类网站源.采用国内做好用的thinkphp5框架融合二次.欢迎下载使用...
-
要搜聚合搜索源码 V1.0
要搜聚合搜索源码全站随意修改无任何加密,本程序没有后台...
下载声明
☉ 解压密码:www.jb51.net 就是本站主域名,希望大家看清楚,[ 分享码的获取方法 ]可以参考这篇文章
☉ 推荐使用 [ 迅雷 ] 下载,使用 [ WinRAR v5 ] 以上版本解压本站软件。
☉ 如果这个软件总是不能下载的请在评论中留言,我们会尽快修复,谢谢!
☉ 下载本站资源,如果服务器暂不能下载请过一段时间重试!或者多试试几个下载地址
☉ 如果遇到什么问题,请评论留言,我们定会解决问题,谢谢大家支持!
☉ 本站提供的一些商业软件是供学习研究之用,如用于商业用途,请购买正版。
☉ 本站提供的PHP中文分词代码 v1.0 UTF-8 资源来源互联网,版权归该下载资源的合法拥有者所有。