
浅谈Mysql使用B+树来实现索引的原因
从实际场景出发
任何数据结构都是为了解决特定问题而产生的,那么如果一个用户使用Mysql,通常会有哪些需求呢?我们可以很容易的想到最简单的需求:
- 通过id或者其他列值进行匹配查询
- 通过id进行范围查询
用户肯定希望查询的性能越高越好,对于一个表来说,如果能直接通过索引来查询到数据,不必进行全表扫描,那就再好不过了.
选择合适的数据结构
这个时候,Mysql的开发人员就会为了解决用户的查询性能问题,开始选择合适的数据结构.能想到的备选方案可能有Hash,B Tree,B+ Tree这三种数据结构.
如果使用Hash作为索引的数据结构
Hash能提供O(1)的查询复杂度,对于类似于select * from t where id = 3这种等值匹配来说,性能相当的高,可以说无人能及.但是对于范围查询来说,Hash就有点捉襟见肘了,Hash没办法做到用O(1)的复杂度来进行范围查询,因为这点,Hash是不适合作为底层索引的实现的.
使用B Tree还是B+ Tree
那么可选的方案现在只剩下B Tree和B+ Tree.因为这两者的数据结构有点相似,所以在这两个数据结构之间进行选择时,最好是将两者放在一起对比,才能更清楚的知道哪种才是更好的数据结构,.
首先我们应该清楚B树是如何存储数据的.这里给出一张图片:
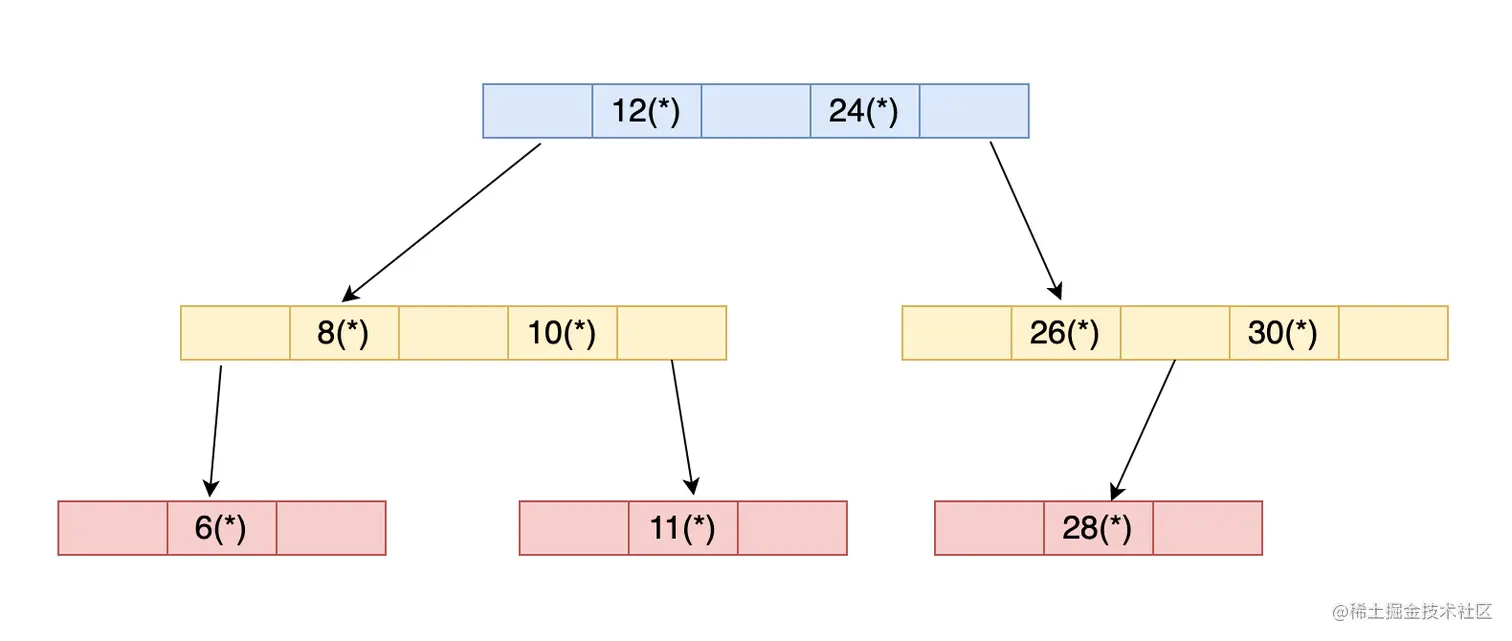
我们现在以聚簇索引来举例,图中的数字代表主键值,后面的*代表该位置是存放实际的行数据的.每个节点的左指针指向下一级的节点,并且左边指向的节点的主键值大小比上一级的小,右边指向的节点的主键值比上一级的大.B Tree的一个重要特点是在每一个节点都存储了完整的行数据.
B+ Tree存储数据的方式是这样的:
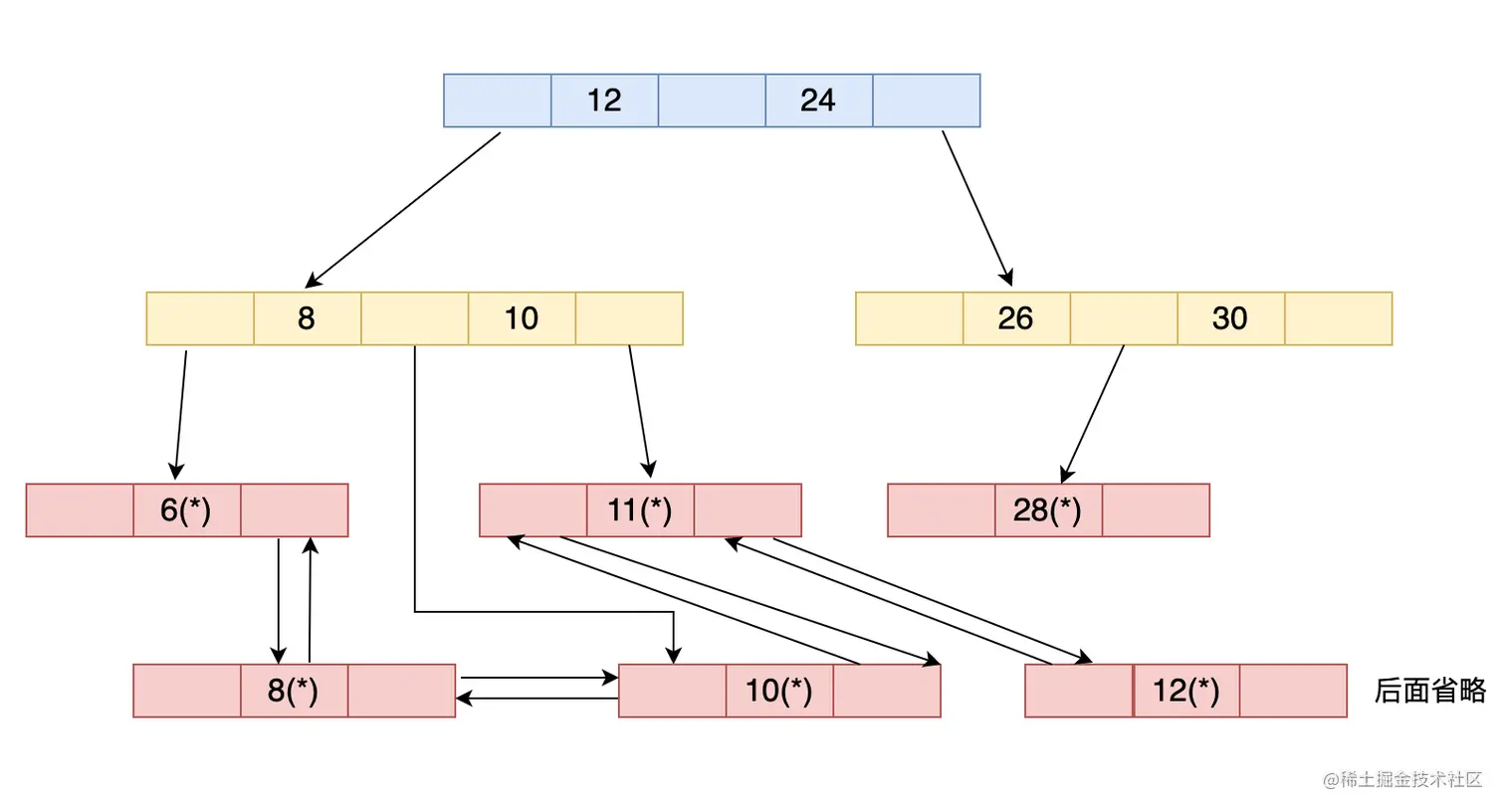
B+ Tree的重要特点是:
只有叶子节点才会存放整行数据,而非叶子节点只存储主键值,用于向下搜索
叶子节点冗余了所有的主键值,并存储行数据,并且每个节点之间用双向链表进行连接
在图中的12这个节点中,后面是指向24这个节点的,在图中被省略了.
在这里,我们再强调一下B Tree和B+ Tree的重要区别:
- B Tree的每个节点都存储行数据,而B+ Tree只有叶子节点存放行数据.
- B Tree因为每个节点都存储行数据,所以没有必要在非叶子节点再冗余任何数据.B+ Tree因为只有叶子节点存储行数据,所以需要在最后一层冗余所有的主键值,并存储行数据,且节点之间用链表进行连接.
理解了这两者的区别之后,我们来考虑一下针对实际场景,哪个数据结构才是更好的选择.首先,我们考虑一下等值查询,对于B Tree来说,从根节点的主键值开始进行比较,根据左小右大的特点,可以在某个层级定位到整行数据并返回.对于B+ Tree来说,也是从根节点开始进行比较,不过最终必须定位到叶子节点才能获取到需要的数据.所以在等值查询这个场景下,B Tree看起来比B+ Tree来得好.
那么考虑一下范围查询,比如B Tree来说,查询数据跟等值查询的模式差不多,只不过需要扫描到多个层级的节点.举个例子,如果在上图中寻找主键大于等于10且小于等于24的行数据.
- 首先从根节点12开始,12是满足条件的,所以获取它的行数据,12后面的同级节点24也符合要求,所以也符合要求.
- 从12的左指针找到下一个节点,第一个节点是8,不符合要求,之后向后找到它的同级节点10,符合要求,后面没有其他节点了,结束.
- 节点12的右指针(节点24的左指针)没有指向任何数据,所以无需再找到下一个节点,所有可能的节点都查询过了,查询结束.
我们可以从这个过程中看到,范围查询需要从根节点出发,然后可能要找到它的下一级节点,直到找到所有符合的数据.
对于B+ Tree来说,寻找主键大于等于10且小于等于24的行数据的流程是这样的:
- 从根节点12向左找到下一级的10这个节点,从10的左指针找到10所在的叶子节点,因为叶子节点是链表结构,那么可以从这个叶子节点的指针一直往后定位到24这个节点,然后返回这中间的所有数据.
实际上数据最终都是存储到磁盘上的,对于Mysql来说,数据是以页为单位来存储数据,通常为4KB,在上面的图中,我们可以理解成每一个大的长方形框是一个页,而每个页里面存放了很多节点,对于B Tree来说,每个页的节点都存放整行数据,对于B+ Tree来说,非叶子页的节点只存放id,也被称为索引页,而叶子节点存放整行数据.对于页的读取,就涉及到IO操作,要知道IO读取数据的速度比从内存读取数据要慢得多,通常读取页的时间在10ms左右.
以范围查询为例,我们从IO的角度来概括一下B Tree和B+ Tree的区别.对于B Tree而言,读取根节点需要一次IO操作,加载出页之后,当前页的数据可能只有部分符合要求,然后根据页的指针再进行IO操作,找到另外的页,整个过程需要更多的IO操作,并且因为每次读取的页并不是所有数据都满足要求,所以这种方式被称为随机IO.那么对于B+ Tree而言,也需要从根节点向下查询,这其中也涉及到随机IO,但定位到需要的叶子节点后,读取页时只需要根据链表来定位到下一个页,每次读取的页大概率都是符合要求的数据,这种方式被称为顺序IO.所以在范围查询中,B Tree需要更多的IO操作,这样就需要耗费更多的时间.如果对随机IO和顺序IO不是很理解,文末有个参考资料可以去看一下.
所以整体上来看,B+ Tree是更好的选择.
以上就是浅谈Mysql使用B+树来实现索引的原因的详细内容,更多关于MySQL B+树索引的资料请关注脚本之家其它相关文章!
相关文章
 这篇文章主要给大家介绍了关于MySQL磁盘碎片整理的相关资料,为什么数据库会产生碎片,以及如何清理磁盘碎片,还有一些清理磁盘碎片的注意事项,需要的朋友可以参考下2022-04-04
这篇文章主要给大家介绍了关于MySQL磁盘碎片整理的相关资料,为什么数据库会产生碎片,以及如何清理磁盘碎片,还有一些清理磁盘碎片的注意事项,需要的朋友可以参考下2022-04-04 这篇文章主要介绍了MySQL主从复制延迟原因以及解决方案,帮助大家更好的理解和使用数据库,感兴趣的朋友可以了解下2020-09-09
这篇文章主要介绍了MySQL主从复制延迟原因以及解决方案,帮助大家更好的理解和使用数据库,感兴趣的朋友可以了解下2020-09-09
linux下mysql开启远程访问权限 防火墙开放3306端口
这篇文章主要为大家详细介绍了linux下mysql开启远程访问权限,防火墙开放3306端口,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-01-01 这篇文章主要介绍了Mysql中的多级复制方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-04-04
这篇文章主要介绍了Mysql中的多级复制方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-04-04
MySQL加减间隔时间函数DATE_ADD和DATE_SUB的实现
mysql中内置函数date_add 和 date_sub能对指定的时间进行增加或减少一个指定的时间间隔,本文主要介绍了MySQLDATE_ADD和DATE_SUB的实现,感兴趣的可以了解一下2024-09-09 这篇文章主要给大家介绍了如何利用MYSQL实现每隔10分钟进行分组统计的方法,文中给出了详细的示例代码,相信对大家的理解和学习具有一定的参考借鉴价值,有需要的朋友们下面来一起看看吧。2016-12-12
这篇文章主要给大家介绍了如何利用MYSQL实现每隔10分钟进行分组统计的方法,文中给出了详细的示例代码,相信对大家的理解和学习具有一定的参考借鉴价值,有需要的朋友们下面来一起看看吧。2016-12-12 今天工作中需要对一台ubantu的系统安装mysql,因为以前一直使用的是centos,虽然它也是类unix但是和redhat或centos命令上还是有点差别。所以通过网上查阅资料,终于安装成功了,现在将步骤分享给大家,有需要的朋友们可以参考借鉴。2016-10-10
今天工作中需要对一台ubantu的系统安装mysql,因为以前一直使用的是centos,虽然它也是类unix但是和redhat或centos命令上还是有点差别。所以通过网上查阅资料,终于安装成功了,现在将步骤分享给大家,有需要的朋友们可以参考借鉴。2016-10-10 这篇文章主要介绍了Linux系统下MySQL的一些实用功能的shell脚本分享,包括启动Memcached、binlog自动清理和修复主从同步这样三个简单的实例,需要的朋友可以参考下2015-12-12
这篇文章主要介绍了Linux系统下MySQL的一些实用功能的shell脚本分享,包括启动Memcached、binlog自动清理和修复主从同步这样三个简单的实例,需要的朋友可以参考下2015-12-12 这篇文章主要介绍了MySQL的mysqldump工具用法详解,同时附带了相关Source命令的用法,详解需要的朋友可以参考下2015-07-07
这篇文章主要介绍了MySQL的mysqldump工具用法详解,同时附带了相关Source命令的用法,详解需要的朋友可以参考下2015-07-07 今天小编就为大家分享一篇关于Mysql两表联合查询的四种情况总结,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2019-01-01
今天小编就为大家分享一篇关于Mysql两表联合查询的四种情况总结,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2019-01-01










最新评论