
Mysql中的自连接问题
Mysql自连接
1、在日常对数据库的操作中,我们很熟悉使用INNER JOIN,LEFT JOIN 把一个表和另外一个表连接起来,潜意识里会认为只有两个表才可以连接,有一个特殊情况,需要将表自身连接,这被称为自连接。
2、想将表中行与同一表中的其他行组合时,可以使用自连接。要执行自联接操作必须使用表别名来帮助MySQL在单个查询中区分左表与同一张表的右表。
DEMO
1、比如组织机构的树形的,数据会有上下级区分,当需要展示组织机构的父级机构名称时,我们可以使用自连接。
2、表结构如图所示:

3、sql
select a.id, a.party_org_name, a.parent_id,b.party_org_name as parent_name FROM sinosoft_party_org a left join sinosoft_party_org b on a.parent_id=b.id
MySQL自连接和内连接和外连接_左外连接+右外连接
自连接:将一张表看作两张表

练习:查询员工id,员工姓名及其管理者的id和姓名
select emp.employee_id, emp.last_name, mgr.employee_id, mgr.last_name from employees emp,employees mgr where emp.manager_id = mgr.employee_id;
内连接
只是把左表和右表满足连接条件的数据查出来,其它的数据都没有要!!!
select employee_id,department_name from employees e join departments d on e.`department_id`=d.`department_id`
外连接
JOIN … ON
左外连接 left join…on
左外连接,左表和右表满足条件的数据,和左表中不满足条件的数据!!!
练习:查询所有员工的last_name,department_name信息
select last_name,department_name from employees e left join departments d on e.`department_id`=d.`department_id`;
右外连接 right join … on
右外连接,右表和左表满足条件的数据,和右表中不满足条件的数据!!!
练习:查询所有员工的last_name,department_name信息
select last_name,department_name from departments d right join employees e on e.`department_id`=d.`department_id`;
七种 SQL JOINS 的实现

UNION的使用
合并查询结果
- 利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。
- 合并时,两个表对应的列数和数据类型必须相同,并且相互对应。
- 各个SELECT语句之间使用UNION或UNION ALL关键字分隔。
UNION操作符
UNION 操作符返回两个查询的结果集的并集,去除重复记录。
UNION ALL操作符
UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
注意:执行UNION ALL语句时所需要的资源比UNION语句少。
如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
1、内连接(两表只要满足条件的)

SELECT employee_id,last_name,department_name FROM employees e JOIN departments d ON e.`department_id` = d.`department_id`;
2、左外连接(左和右满足条件的,和左中不满足条件的)

SELECT employee_id,last_name,department_name FROM employees e LEFT JOIN departments d ON e.`department_id` = d.`department_id`;
3、右外连接(右和左满足条件的,和右中不满足条件的)

SELECT employee_id,last_name,department_name FROM employees e RIGHT JOIN departments d ON e.`department_id` = d.`department_id`;
4、在左外连接的基础上,右表取null值(满足条件的肯定不是null,我们不取)

SELECT employee_id,last_name,department_name FROM employees e LEFT JOIN departments d ON e.`department_id` = d.`department_id` WHERE d.`department_id` IS NULL
5、在右外连接的基础上,我们取左表的null值

SELECT employee_id,last_name,department_name FROM employees e RIGHT JOIN departments d ON e.`department_id` = d.`department_id` WHERE e.`department_id` IS NULL
6、右外连接取左表null值,和左外连接合并UNION ALL
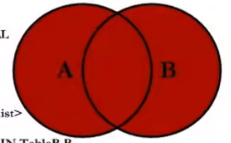
SELECT employee_id,last_name,department_name FROM employees e LEFT JOIN departments d ON e.`department_id` = d.`department_id` WHERE d.`department_id` IS NULL UNION ALL #没有去重操作,效率高 SELECT employee_id,last_name,department_name FROM employees e RIGHT JOIN departments d ON e.`department_id` = d.`department_id`;
7、
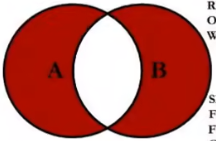
SELECT employee_id,last_name,department_name FROM employees e LEFT JOIN departments d ON e.`department_id` = d.`department_id` WHERE d.`department_id` IS NULL UNION ALL SELECT employee_id,last_name,department_name FROM employees e RIGHT JOIN departments d ON e.`department_id` = d.`department_id` WHERE e.`department_id` IS NULL
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 索引是一种数据结构,为了应对不同的场景会有多种实现,下面这篇文章主要给大家介绍了关于MySQL数据库索引以及失效场景的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-01-01
索引是一种数据结构,为了应对不同的场景会有多种实现,下面这篇文章主要给大家介绍了关于MySQL数据库索引以及失效场景的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-01-01 在日常工作中,会简单的使用一下mysql,故对常见命令操作总结一下,常用方式如下2010-02-02
在日常工作中,会简单的使用一下mysql,故对常见命令操作总结一下,常用方式如下2010-02-02 这篇文章主要介绍了MySQL MyISAM默认存储引擎实现原理,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-03-03
这篇文章主要介绍了MySQL MyISAM默认存储引擎实现原理,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-03-03
使用mysql的disctinct group by查询不重复记录
非常不错的方法,用mysql的group by解决不重复记录的问题,看来我需要学习的地方太多了2008-08-08 原先数据配置文件中有bind-address=127.0.0.1,注释掉此配置后,原数据库中默认带%root的权限,现在需要通过脚本实现白名单列表中的ip添加权限允许访问数据库,本文给大家介绍了使用Shell脚本进行MySql权限修改的实现教程,需要的朋友可以参考下2024-03-03
原先数据配置文件中有bind-address=127.0.0.1,注释掉此配置后,原数据库中默认带%root的权限,现在需要通过脚本实现白名单列表中的ip添加权限允许访问数据库,本文给大家介绍了使用Shell脚本进行MySql权限修改的实现教程,需要的朋友可以参考下2024-03-03 数据库备份是在数据丢失的情况下能及时恢复重要数据,防止数据丢失的一种重要手段,下面这篇文章主要给大家介绍了关于Mysql数据库备份与恢复的相关资料,需要的朋友可以参考下2022-05-05
数据库备份是在数据丢失的情况下能及时恢复重要数据,防止数据丢失的一种重要手段,下面这篇文章主要给大家介绍了关于Mysql数据库备份与恢复的相关资料,需要的朋友可以参考下2022-05-05 本篇所讲的动态SQL,是mybatis通过标签元素的形式, 如if, choose, when, otherwise, trim, where, set, foreach等标签完成对sql的拼接功能,使用起来也非常灵活方便,这篇文章主要介绍了MyBatis动态SQL、模糊查询与结果映射,需要的朋友可以参考下2023-08-08
本篇所讲的动态SQL,是mybatis通过标签元素的形式, 如if, choose, when, otherwise, trim, where, set, foreach等标签完成对sql的拼接功能,使用起来也非常灵活方便,这篇文章主要介绍了MyBatis动态SQL、模糊查询与结果映射,需要的朋友可以参考下2023-08-08
在Ubuntu或Debian系统的服务器上卸载MySQL的方法
这篇文章主要介绍了在Ubuntu或Debian系统的服务器上卸载MySQL的方法,适用于Debian系的Linux系统,需要的朋友可以参考下2015-06-06 这篇文章主要介绍了mysql中查询字段为null的数据navicat问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-12-12
这篇文章主要介绍了mysql中查询字段为null的数据navicat问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-12-12 事件(Events) 是在 MySQL 5.1后引入的,有点类似操作系统的计划任务(cron),但是周期性任务是内置在 MySQL 服务端执行的。本文讲述MySQL如何用事件完成计划任务2021-05-05
事件(Events) 是在 MySQL 5.1后引入的,有点类似操作系统的计划任务(cron),但是周期性任务是内置在 MySQL 服务端执行的。本文讲述MySQL如何用事件完成计划任务2021-05-05










最新评论