
Mysql架构图解读
Mysql服务端架构分为Server层和存储引擎层(可插拔式),Server层主要包含了连接器、缓存模块、分析器、优化器、执行器;可插拔的存储引擎主要有InnoDB、MyISAM、Memory。
当一个请求进入后的执行流程如下图的箭头所示:
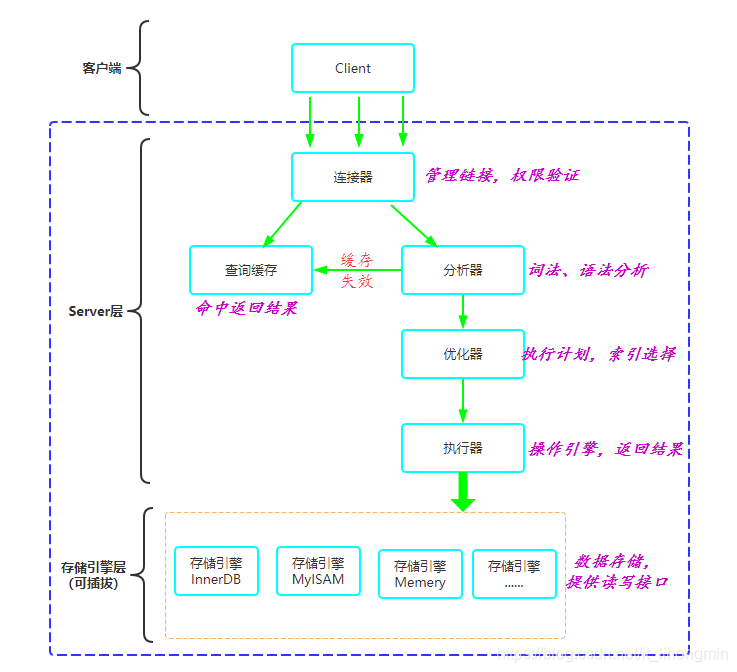
一、Server层
1、连接器
连接器主要负责与Mysql客户端建立连接,权限认证,维持和管理链接。
当开始连接服务器时需要使用账号、密码登录服务器,执行命令:
mysql -h $ip -P $port -u $root -p $password
如果用户名验证不通过则会报错:Access denied for user;成功则继续调用权限表,获取用户权限信息,存储到类似本地线程变量中,后续分析器、优化器中会使用。当给当前用户权限进行修改后,自己需要重新登录才能获取新的权限信息,类似我们自己写权限相关代码时,会将权限、角色等相关信息存储到线程本地变量 ThreadLocal 中。
当与服务器建立链接后,我们可以使用 show processlist; 命令查看当前链接到服务器的客户端链接信息,如果status为sleep等状态表示处于空闲状态。记得自己刚开始开发项目时,客户端没有配置好,服务器请求量很低,特别是晚上,第二天来就会看到报错:Lost connection to MySQL server during query。就是在连接器模块报错的,服务端配置 wait_timeout 可以设置客户端再次请求时,判断是否超时,为8小时。
与服务器端的链接分为长链接和短连接。短连接本身每次都会执行TCP的三次握手和四次挥手,并且建立链接后会进行认证和权限相关的操作,我们需要防止客户端并发量递增时对服务器端的短连接风暴。现在开发项目Mysql客户端基本都基于线程池实现,线程本身是复用的长链接,长链接的弊端是会在服务端线程内部存储大量的查询缓存等信息,只有断开链接时才会释放。所以最好是使用长链接的同时,当执行了比较大的事务之后,手动断开链接,释放资源。在 5.7版本之后,mysql增加了mysql_reset_connection参数可以将链接初始化到刚刚创建链接时的状态,我们可以在长事务或者定时执行该操作。
2、缓存模块
缓存模块是一直比较弊病的模块,在 Mysql 8之后已经废弃掉了。由于查询时根据整个sql进行hash计算,我们知道hash计算哪怕原字符有一个标点不同那么hash值也完全不同,所以一定要sql一模一样才能匹配缓存。
但是整个表只要有一点修改操作就会将所有缓存进行删除,即可能费了很大的力气进行缓存,但是还没执行缓存查询就被删除了。
所以缓存只适用于配置表等基本不会变动的数据,但是个人理解,随着redis等旁路缓存的普及,基于所有的项目都有缓存,那么数据库的缓存弊病多使用。
- query_cache_type 设置为 off/on 缓存是否开启;
- query_cache_size = 0:缓存大小,可以设置如:128M;
- 也可以将 query_cache_type 设置为 :DEMAND, 在需要缓存时显示调用,如: select SQL_CAHCE * from table where id = 100;
3、分析器(分析需要做什么)
读执行的sql进行词法和语法分析,词法分析需要解析如select是一个查询语句,查询的具体表名,查询的条件等;语法分析如 sql字符串 是否符合sql规范,是否符合Mysql 自己的sql规范等。
一般遇到的
you have an error in your SQL syntax use near...
就是在该模块报出的。
4、优化器(分析怎么做)
优化器主要负责索引的选择、多表关联时的 join 顺序,这些都具体在后面专门进行分析。
5、执行器(执行过程)
执行器负责具体调用底层的存储引擎接口,处理数据。
rows_examined调用底层引擎接口查询的条数或次数,有可能这里调用一次叠加一次,但是内部可能查询了多行数据。
二、存储引擎层
常用的存储引擎有InnoDB、MyISAM、Memory,现在很多公司的数据库规范直接规定创建表只能使用 InnoDB,不仅仅是因为支持事务,还与运维时候的数据备份等相关。
在 Mysql 5.5后,将默认的存储引擎从 MyISAM变更为 InnoDB,只是个人还是比较喜欢或者建议在创建表时,显示设置存储引擎 engine = Innodb。
Memory引擎作为临时表的默认存储引擎,当执行复杂sql或数据量比较大需要使用临时表;或者我们自己手动基于临时表实现业务时,都会用到Memory存储引擎,所以还是需要关注的。
存储引擎需要关注具体的数据结构:
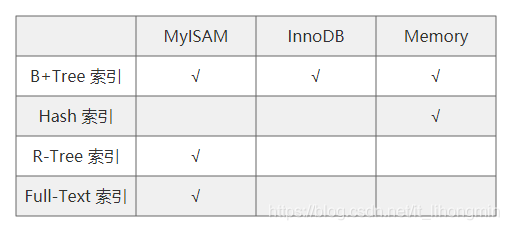
InnoDB只支持B+树的数据结构,而Memory引擎支持B+树和Hash索引。
B+树支持快速的读写,并且时间复杂度为O(logN),支持区间查询。
Hash索引读写的时间复杂度近似O(1),比较适合内存中使用,不支持区间查询。
三、查询流程
select name from table_1 where email = 'XXX'; // 比如该表使用 innoDB引擎
- 1、【连接器】先使用长链接或者短链接,使用用户名和密码进行登录操作;
- 2、【连接器】执行上面的select语句,到连接器;
- 3、【缓存模块】判断是否有开启缓存,或者要查询缓存,有查询完成后需要回执缓存;
- 4、【解析器】检查sql的词法、语法分析,是否sql有问题;
- 5、【优化器】判断是否有索引,是否需要进行优化等(这里没有join等操作);
email无索引:
- 6、【执行器】、调用innoDB引擎接口获取表的第一条数据,判断 eamil是否相等,如果是则放入结果集中,叠加器rows_examined++
- 7、【执行器】、重复执行上面的动作,一直到表的最后一行
- 8、【执行器】、将结果集返回给客户端
email有索引:(之前一直以为是innoDB直接返回了所有满足条件的结果集给执行器)
- 6、【执行器】、调用InnoDB的满足条件的第一行数据,内部查询走索引
- 7、【执行器】、获取满足条件的下一行
- 8、【执行器】、返回结果集
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章

Mysql5.7及以上版本 ONLY_FULL_GROUP_BY报错的解决方法
这篇文章主要介绍了Mysql5.7及以上版本 ONLY_FULL_GROUP_BY报错的解决方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-03-03 这篇文章主要介绍了sql distinct多个字段的使用方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08
这篇文章主要介绍了sql distinct多个字段的使用方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08 这篇文章主要介绍了结合PHP脚本添加和查询MySQL数据的基本教程,即在PHP程序中使用基本的SELECT FROM和INSERT INTO语句,需要的朋友可以参考下2015-12-12
这篇文章主要介绍了结合PHP脚本添加和查询MySQL数据的基本教程,即在PHP程序中使用基本的SELECT FROM和INSERT INTO语句,需要的朋友可以参考下2015-12-12 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,本系列将带你掌握php与mysql的基础应用,本篇带你了解数据控制2022-02-02
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,本系列将带你掌握php与mysql的基础应用,本篇带你了解数据控制2022-02-02 下面小编就为大家带来一篇MySQL一个语句查出各种整形占用字节数及最大最小值的实例。2017-03-03
下面小编就为大家带来一篇MySQL一个语句查出各种整形占用字节数及最大最小值的实例。2017-03-03 在本篇文章里小编给大家整理的是关于mysql创建表的sql语句的相关知识点,需要的朋友们可以参考下。2020-02-02
在本篇文章里小编给大家整理的是关于mysql创建表的sql语句的相关知识点,需要的朋友们可以参考下。2020-02-02 MySQL 是最流行的关系型数据库管理系统,在WEB应用方面 MySQL 是最好的。本文将为大家详细介绍一下MySQL的基础操作,需要的可以参考一下2022-03-03
MySQL 是最流行的关系型数据库管理系统,在WEB应用方面 MySQL 是最好的。本文将为大家详细介绍一下MySQL的基础操作,需要的可以参考一下2022-03-03
如何区分MySQL的innodb_flush_log_at_trx_commit和sync_binlog
这篇文章主要介绍了如何区分MySQL的innodb_flush_log_at_trx_commit和sync_binlog,帮助大家更好的理解和使用MySQL数据库,感兴趣的朋友可以了解下2021-02-02 MySQL提供了各种特殊函数,它们可以帮助管理者查询复杂的数据,资料库包括字符串函数,数学函数,日期函数,程序函数等,下面这篇文章主要给大家介绍了关于MySQL特殊函数使用技巧的相关资料,需要的朋友可以参考下2023-05-05
MySQL提供了各种特殊函数,它们可以帮助管理者查询复杂的数据,资料库包括字符串函数,数学函数,日期函数,程序函数等,下面这篇文章主要给大家介绍了关于MySQL特殊函数使用技巧的相关资料,需要的朋友可以参考下2023-05-05 在本篇文章里小编给大家分享的是一篇关于mysql事务对效率的影响分析总结内容,有需要的朋友们可以跟着学习下。2021-10-10
在本篇文章里小编给大家分享的是一篇关于mysql事务对效率的影响分析总结内容,有需要的朋友们可以跟着学习下。2021-10-10










最新评论