
NVIDIA RTX 3080显卡怎么样 NVIDIA RTX 3080显卡详细评测
在9月2日的发布会中,黄仁勋先生不止一次强调了“这是有史以来最伟大性能提升”。而从发布会展示的效果来看,RTX 30系显卡用双倍加量不加价来形容都不为过。并且第二代RTX的Ampere架构所带来最直接的变化就是在性能方面暴涨,所以发布会前的种种烟雾弹也就显而易见了,下面笔者就给大家带来NVIDIA GeForce RTX 3080的首发评测。
01 NVIDIA GeForce RTX 3080 外观
下面我们先来看看这次NVIDIA RTX 3080 显卡的外观,首先在外包装上,一向是NV的极简风格,方方正正的硬纸盒子,主色调以黑色为主,辅以玫瑰金色纹路,而这次NVIDIA也罕见的没有用绿色,整体看起来有点像Tesla V100。

外包装与显卡
入手显卡之后,给人的第一感觉就是质感极强,堪称工业设计典范。在发布会当中我们也看到此次的RTX 30系显卡在外观方面做了极大改变,卡身大面积被散热鳍片覆盖。
而在拿到显卡后,我居然发现所有散热鳍片上都有哑光涂层,所以触感更偏温润。而显卡的外壳部分,采用了大面积的金属包裹,表面为磨砂材质。

散热鳍片全部采用了哑光涂层
NVIDIA这款RTX 3080拿在手里给人的第一感觉就是——完美。这绝对是件艺术品,虽然以往在公版评测的时候我们都会惊叹其做工精致,但像这次如此巧妙地将大面积的金属融合在一起,形成刚柔并济,绝对在设计之初下了很大功夫,而这种效果弄不好就会成为一个“铁疙瘩”。

GeForce RTX 3080外观展示
之所以RTX 30系显卡的外观需要大改,是因为在散热方面同样做了颠覆性的设计。它采用了双轴流式设计,RTX 3080主动散热的风扇为一前一后,根据官方数据,空气流量相较于之前的设计增加55%,散热效率提升30%,静音效果提升至3倍。

散热系统示意
具体的工作原理如上图所示,这也是NVIDIA显卡第一次将散热系统与机箱整体散热结合,形成协同工作。

散热系统工作原理
新的散热系统,可以吸入外部的冷空气,流经GPU,并将热空气直接从机箱背部排出。另一个背面拉动式风扇同样吸入冷空气,但流经热管上的散热鳍片,并通过机箱整体的散热系统引导至机箱背部排出。

PCB版对比
在显卡内部的PCB板上NVIDIA也做了非常大的调整,为了搭配新的散热系统,此次采用了超高密度的PCB板设计,前端为“V”字造型,体积较之前缩小了50%。
从图中可以看到板子上密密麻麻的元件排布,中间为RTX 3080的核心,四周分布10颗显存颗粒,同时还有两个空焊位置。

GeForce RTX 3080 PCB大图
18相供电依次排列在芯片左右两侧,钽电容分布在边边角角的位置。另外供电接口可以看到位于整块板子的右上方,其空间也真的只能容纳下单接口了,可以说整块PCB板几乎没有任何富裕位置。

内附的供电转接线
由于本次公版显卡采用了单12pin的供电接口,为了方便适配玩家现有的电源,包装内还附带了一根转接线,可以将单12pin专为8+8pin,不过由于接口的方向设计,会正好挡住“GeForce RTX”的信仰logo,略微有些瑕疵。
02 NVIDIA Ampere架构带来的变化
下面我们就来看看,“有史以来最伟大性能提升”相比第一代的RTX Turing架构,NVIDIA Ampere会有哪些变化吧。
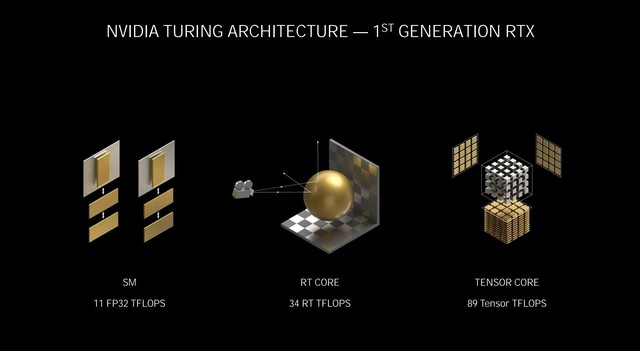
第一代RTX架构 Turing

第二代RTX架构 Ampere
首先来简单回顾一下在9月2日发布会的PPT上我们都看到了什么,相较于初代的Turing RTX架构,NVIDIA Ampere架构在算力上有着成倍的增长,每个时钟执行2次着色器运算,而Turing为1次,着色器性能达到30 TFLOPS单精度性能,而Turing为11 TFLOPS。
NVIDIA Ampere架构翻倍了光线与三角形的相交吞吐量,RT Core达到58 RT TFLOPS,而Turing为34 RT TFLOPS。
另外在全新的Tensor Core中,可自动识别并消除不太重要的DNN权重,处理稀疏网络的速率是Turing的两倍,算力高达238 Tensor TFLOPS,而Turing为89 Tensor TFLOPS。

芯片说明
全新的NVIDIA Ampere GPU核心拥有280亿个晶体管,628平方毫米的面积,基于三星的8nm NVIDIA定制工艺,来自美光的GDDR6X显存,以及我们上面说的,三大处理核心均为初代Turing的两倍速率,构成了有史以来性能最强大的Ampere。
而NVIDIA Ampere架构的强大性能并不是NVIDIA一蹴而就,可以说在20系显卡中所采用的Turing架构功不可没,下面我们先来看看完整的GA102核心。
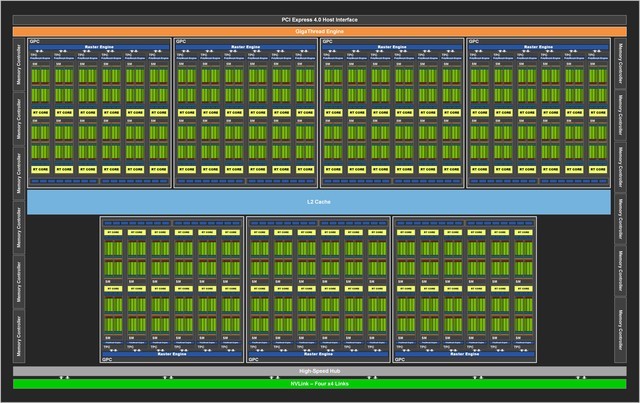
完整的GA102核心
完整的GA102 GPU包含7个GPC(图形处理集群)42个TPC(纹理处理集群)以及84个SM(流处理器)组成。GPC是占据主导地位的高级模块,拥有所有的关键图形处理单元,每个GPC包含一个专用光栅引擎。在新的NVIDIA Ampere架构中,每个GPC还包含了两个ROP分区,每个分区包含8个ROP单元。下面我们来看看每个SM单元的变化。

SM详解
在每个SM中,包含四个大的处理分区共128个CUDA核心,4个第三代Tensor Core,1个第二代RT Core,1个256 KB的缓存文件,1个128 KB的L1缓存,这个L1缓存可以根据不同的工作需求来调配缓存,工作效率发挥至最大。
另外大家都知道本次RTX 3080的CUDA数量暴增至8704个,而RTX 3090的CUDA数量更是达到了惊人的10496个,但是大家要知道专业计算卡Tesla A100的GA100核心,拥有更大的核心面积,更多的晶体管数量,理论上只有8192个CUDA,那RTX 3080又是如何达到这种效果的呢?
其实是因为本次NVIDIA Ampere的SM在Turing基础上增加了一倍的FP32运算单元,这就使得每个SM的FP32运算单元数量提高了一倍。
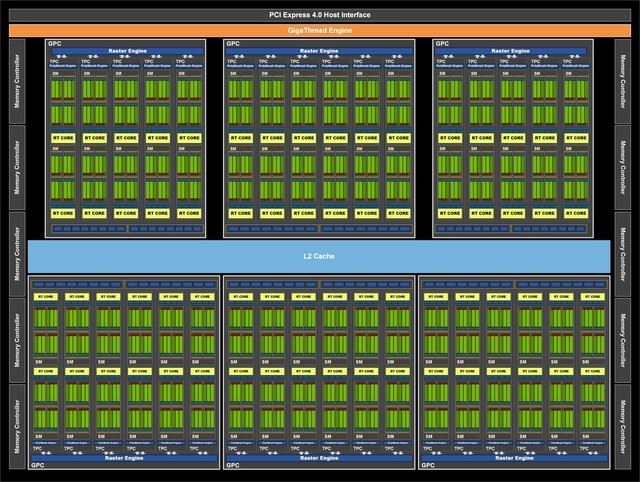
完整的GeForce RTX 3080核心
而通常我们计算显卡的CUDA数量,并不是把SM中的所有单元加起来计数,而是只统计FP32单元的数量,所以这样一来答案就显而易见了,SM中的FP32 : INT32 从 1:1 变为 2:1,如RTX 3080的8704个CUDA,其实它只有4352个INT32单元,但由于内部的FP32数量翻了一倍,所以最终实现了8704这个惊人的数字。
不过这样究竟算不算“虚标”?其实对于现在的游戏来说,浮点运算相比整数计算要常用的多,所以翻倍的FP32真的能带来性能翻倍的提升。
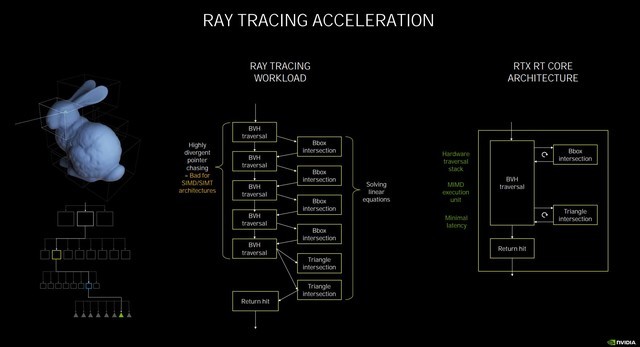
光追工作原理示意
在此次的NVIDIA Ampere架构中,NVIDIA官方宣布为第二代RT Core,它和第一代有什么不同呢。首先要知道RT Core的工作原理是,着色器发出光线追踪的请求,交给RT Core来处理,它将进行两种测试,分别为边界交叉测试(Box Intersection testing)和三角形交叉测试(Triangle Intersection testing)。基于BVH算法来判断,如果是方形,那么就返回缩小范围继续测试,如果是三角形,则反馈结果进行渲染。
而光线追踪最耗时的正是求交计算,因此,要提升光线追踪性能,主要是对两种求交(BVH/三角形求交)进行加速。

RT Core的变化
在Turing的RT Core中,可以每个周期完成5次BVH遍历、4次BVH求交以及一次三角形求交,在第二代RT Core 里,NVIDIA增加了一个新的三角形位置插值模块以及一个的额外的三角形求交模块,这样做的目的是为了提升诸如运动模糊特效时候的光线追踪性能。

运动模糊渲染原理
第二代RT Core可以让光线追踪与着色同时进行,进行的光线追踪越多,加速就越快,它将光线相交的处理性能提升了一倍,在渲染有动态模糊的影像时,按照NVIDIA自己的实测,比Turing快8倍。
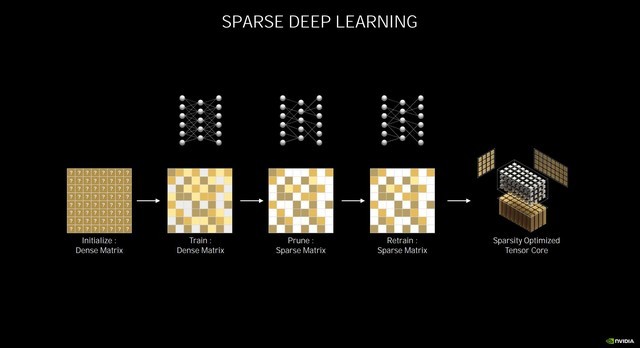
稀疏深度学习
除了光线追踪的强化,Ampere架构的Tensor Core也得到了极大地加强,在第三代Tensor Core中,NVIDIA引入了稀疏化加速,可自动识别并消除不太重要的DNN(深度神经网络)权重,同时依然能保持不错的精度。
首先原始的密集矩阵会经过训练,删除掉稀疏矩阵,再经过训练稀疏矩阵,从而实现稀疏优化,进而提高Tensor Core的性能。
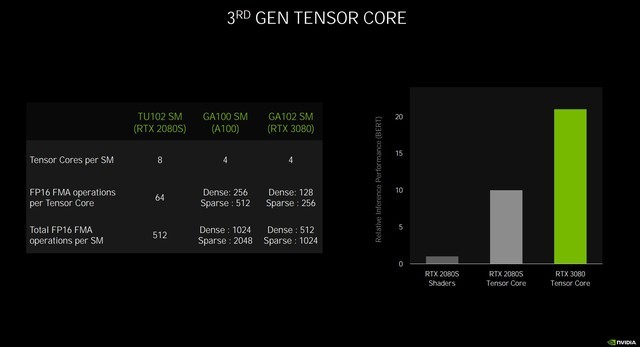
第三代Tensor Core的处理能力大大提升
所以最终的结果就是Tensor Core在处理稀疏网络的速率是Turing的两倍,算力高达238 Tensor TFLOPS,而Turing为89 Tensor TFLOPS。
同时在发布会中,黄仁勋还提到了一项新技术——RTX IO。目前很多游戏动辄几十G甚至百G的安装空间,对于存储空间的负担暂且不提,但存放在硬盘中的数据,如果显卡想要读取到,需要先由CPU从硬盘中读取压缩过的数据,经过解压缩再发送到显存中。
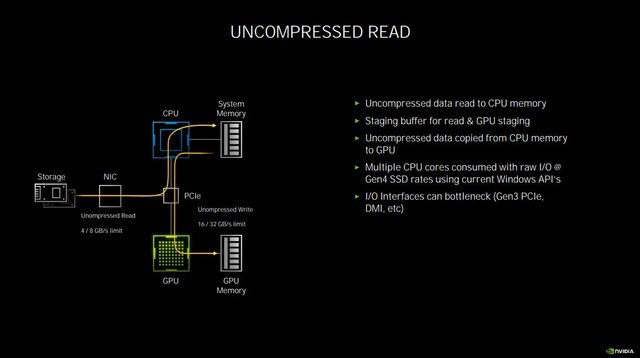
传统的数据交换
在这个过程中,会占用多个CPU核心,压力急剧增大,占用较多的内存,而此时其实GPU是处于闲置状态的。RTX IO的作用就是越过CPU解压再传输数据这一步,直接从PCIE总线读取硬盘上经过压缩的数据,并且完成解压,降低CPU占用,变向提升了性能。
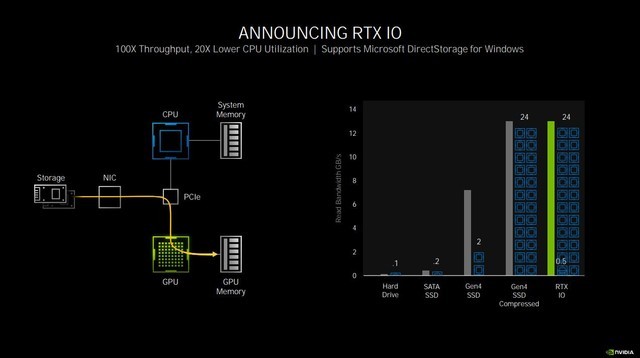
RTX IO可以极大解放CPU负担
相关文章

NVIDIA RTX3080值得入手吗 NVIDIA RTX3080显卡详细评测
NVIDIA RTX3080显卡怎么样?性能如何?玩游戏卡不卡?值得买吗?下面小编带来NVIDIA RTX3080显卡详细评测2020-09-17
NVIDIA 30系显卡怎么样 NVIDIA 30系显卡发布会内容详解
NVIDIA这场发布会简短精悍节奏紧凑,满打满算不过40分钟,但NVIDIA CEO黄仁勋先生的每一句话都值得细细品味,乃至反复观看,一起看看吧2020-09-02
英伟达 RTX 30 显卡值得入手吗 一文看懂英伟达 RTX 30 系显卡
英伟达 RTX 30 显卡值得入手吗?9月2日凌晨消息,英伟达在线上举行发布会,正式发布了GeForce RTX 30系显卡。下文中为大家带来了英伟达 RTX 30 系显卡详细介绍,感兴趣的朋2020-09-02
win10 2004系统显卡驱动报错怎么办 显卡驱动报错的原因和解决方法
最近很多win10 2004系统的朋友遇到了不少的问题,最为常见的就是显卡驱动总是报错,那么是什么原因造成的显卡报错呢?又该如何解决win10 2004显卡驱动报错呢?还有不知道的2020-08-07
影驰GTX 1650 Ultra骁将显卡怎么样 影驰GTX 1650 Ultra骁将评测
今天给大家带来的是带Ultra后缀的1650骁将显卡,这是一张入门甜品卡,一起看看吧2020-08-06
蓝宝石RX570白金 4G版怎么样 蓝宝石RX570白金 4G版显卡介绍
蓝宝石RX 570 4G D5白金OC显卡采用了AMD全新14nm工艺的Polaris 20 XL核心,显卡的显存规格为4GB/256-Bit,核心频率为1244-1284MHz,搭载了2048个流处理器,一起看看吧2020-07-27
AMD GPU RX-5300M显卡怎么样?AMD GPU RX-5300M显卡详细测试
外媒 Notebookcheck 现已发布了微星 Bravo 15 的评测,这款笔记本搭载了 R7 4800H 和 RX 5300M 显卡。一起来看一下这款 AMD 移动端入门级显卡表现如何吧2020-07-15
性能强大灯效炫目 七彩虹RTX 2080 SUPER显卡评测
最近,微软正式公布了DX12 Ultimate,新增对DXR 1.1光线追踪的支持,提高了光追游戏的性能,所以我就在上个月入手了七彩虹iGame GeForce RTX 2080 SUPER Vulcan X OC,一起2020-07-07
畅玩光线追踪游戏 iGame RTX 2060 SUPER显卡评测
随着3A大作游戏的不断涌进,所带来极致光效的渲染画面也是让人为之惊叹,而七彩虹iGame GeForce RTX 2060 SUPER Vulcan X OC作为热卖的甜品级显卡之一,不仅外观炫彩华丽,2020-07-01
技嘉GTX1650显卡怎么样 技嘉GTX1650 EAGLE OC-4GD DDR6显卡评测
技嘉GTX1650显卡怎么样?性能如何?适合玩游戏吗?值不值得买?下面小编带来技嘉GTX1650 EAGLE OC-4GD DDR6显卡评测2020-06-29








最新评论