
深入探究ChatGPT的工作原理
这篇文章主要探讨了ChatGPT的工作原理。ChatGPT是基于OpenAI开发的GPT-4架构的大型语言模型。首先,文章介绍了GPT的基本概念,即生成预测性网络模型。GPT模型利用大量的文本数据进行训练,从而学会在各种情境中生成连贯的文本。
接着,文章详细阐述了训练过程,分为预训练和微调两个阶段。在预训练阶段,模型学习理解文本数据,包括词汇、语法、事实等;在微调阶段,模型使用具有限制性任务的数据集来调整,以获得更准确的输出。作者还提到了训练数据的来源,强调了在大量网络文本数据中获取知识的重要性。
在解释输出生成时,文章提到了一个关键技术:集束搜索(Beam Search)。这是一种启发式搜索策略,用于选择最优文本序列。此外,作者强调了解决生成内容问题的策略,包括设置过滤器和调整温度参数。
最后,文章讨论了ChatGPT的局限性,例如处理输入数据时可能会产生偏见,或无法回答一些问题。尽管如此,作者指出ChatGPT是一个强大的工具,能够在各种任务中提供有价值的帮助。
像ChatGPT这样的大型语言模型实际上是如何工作的?嗯,它们既非常简单又极其复杂。

你可以将模型视为根据某些输入计算输出概率的工具。在语言模型中,这意味着给定一系列单词,它们会计算出序列中下一个单词的概率,就像高级自动完成一样。

要理解这些概率的来源,我们需要谈论一些叫做神经网络的东西。这是一个类似网络的结构,数字被输入到一侧,概率被输出到另一侧。它们比你想象的要简单。

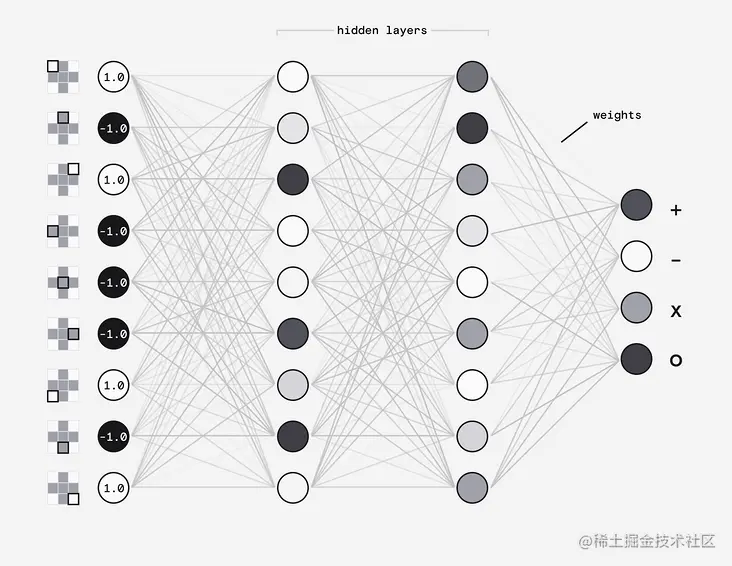
想象一下,我们想要训练一台计算机来解决在3x3像素显示器上识别符号的简单问题。我们需要像这样的神经网络:
- 一个输入层
- 两个隐藏层
- 一个输出层。

我们的输入层由9个称为神经元的节点组成,每个像素一个。每个神经元将保存从1(白色)到-1(黑色)的数字。我们的输出层由4个神经元组成,每个神经元代表可能的符号之一。它们的值最终将是0到1之间的概率。

在这些之间,我们有一些神经元的排列,称为**“隐藏”层**。对于我们简单的用例,我们只需要两个。每个神经元都通过一个权重与相邻层中的神经元相连,该权重的值可以在-1和1之间。
当一个值从输入神经元传递到下一层时,它会乘以权重。然后,该神经元简单地将其接收到的所有值相加,将该值压缩在-1和1之间,并将其传递给下一层中的每个神经元。
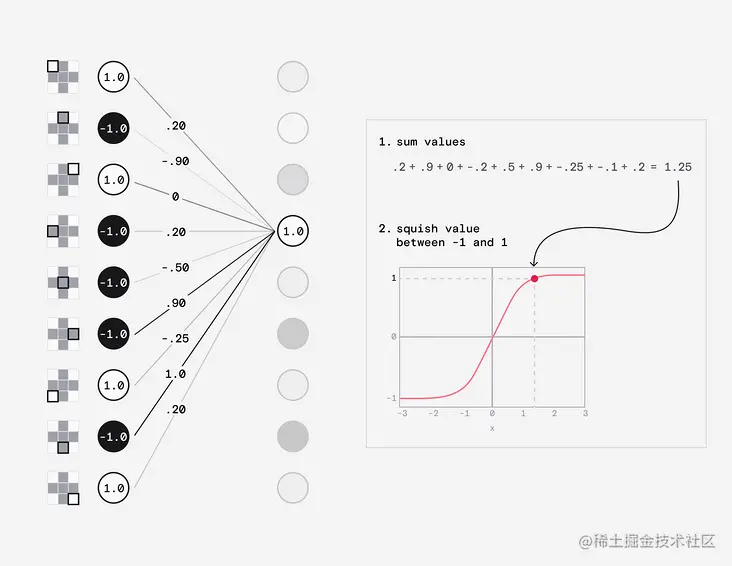
最后一个隐藏层中的神经元执行相同的操作,但将值压缩在0和1之间,并将其传递到输出层。输出层中的每个神经元都保存一个概率,最高的数字是最可能的结果。

当我们训练这个网络时,我们向它提供一个我们知道答案的图像,并计算答案与网络计算的概率之间的差异。然后我们调整权重以接近预期结果。但是我们如何知道如何调整权重呢?

我们使用称为梯度下降和反向传播的巧妙数学技术来确定每个权重的哪个值会给我们最低的误差。我们不断重复这个过程,直到我们对模型的准确性感到满意。

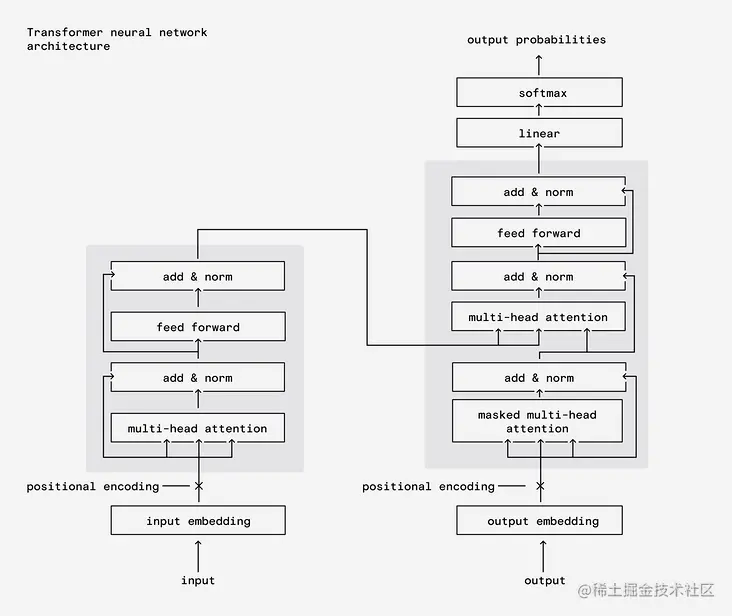
这被称为前馈神经网络 - 但这种简单的结构不足以解决自然语言处理的问题。相反,LLM倾向于使用一种称为Transformer的结构,它具有一些关键概念,可以释放出很多潜力。
首先,让我们谈谈单词。我们可以将单词分解为 token ,这些 token 可以是单词、子单词、字符或符号,而不是将每个单词作为输入。请注意,它们甚至包括空格。
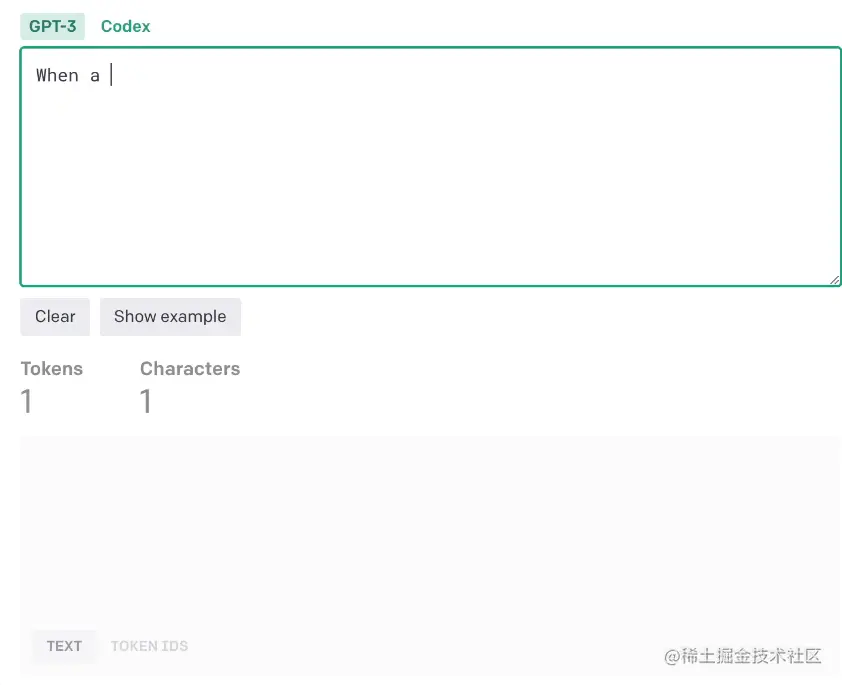
就像我们的模型中将像素值表示为0到1之间的数字一样,这些token也需要表示为数字。我们可以为每个标记分配一个唯一的数字并称之为一天,但还有另一种表示它们的方式,可以添加更多上下文。

我们可以将每个 token 存储在一个多维向量中,指示它与其他标记的关系。为简单起见,想象一下在二维平面上绘制单词位置。我们希望具有相似含义的单词彼此靠近。这被称为 embedding 嵌入。

embedding 有助于创建相似单词之间的关系,但它们也捕捉类比。例如,单词“dog”和“puppy”之间的距离应该与“cat”和“kitten”之间的距离相同。我们还可以为整个句子创建 embedding 。

transformer 的第一部分是将我们的输入单词编码为这些 embedding。然后将这些嵌入馈送到下一个过程,称为 attention ,它为 embedding 添加了更多的上下文。attention 在自然语言处理中非常重要。

Embedding 难以捕捉具有多重含义的单词。考虑 bank 这个词的两个含义。人类根据句子的上下文推断出正确的含义。Money 和 River 在每个句子中都是与 bank相关的重要上下文。
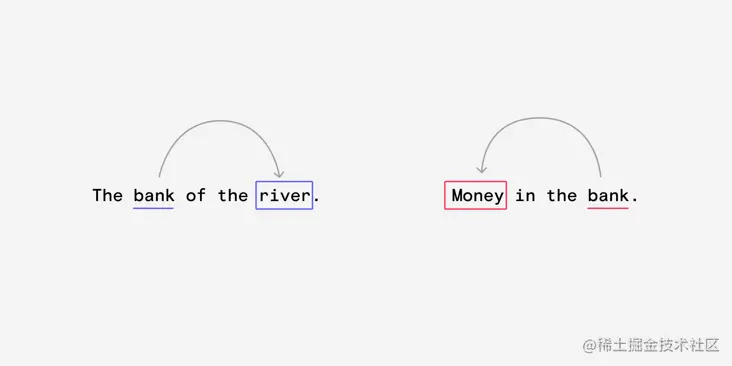
attention 的过程会回顾整个句子,寻找提供词汇背景的单词。然后重新调整 embedding 权重,使得单词“river”或“money”在语义上更接近于“word bank”。

这个 attention 过程会多次发生,以捕捉句子在多个维度上的上下文。在所有这些过程之后,上下文 embedding 最终被传递到神经网络中,就像我们之前提到的简单神经网络一样,产生概率。
这是一个大大简化了的LLM(像ChatGPT这样的语言模型)工作原理的版本。为了简洁起见,本文省略或略过了很多内容。
编辑中可能存在的bug没法实时知道,事后为了解决这些bug,花了大量的时间进行log 调试,这边顺便给大家推荐一个好用的BUG监控工具 Fundebug。
以上就是深入探究ChatGPT的工作原理的详细内容,更多关于ChatGPT工作原理的资料请关注脚本之家其它相关文章!
相关文章
 WebStorm 是jetbrains公司旗下一款JavaScript开发工具,这篇文章主要为大家详细介绍了WebStorm安装教程,文中安装步骤非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-11-11
WebStorm 是jetbrains公司旗下一款JavaScript开发工具,这篇文章主要为大家详细介绍了WebStorm安装教程,文中安装步骤非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-11-11 本文介绍了TF坐标变换的基本概念以及TF在ROS中的表示形式,通过古月居的乌龟跟随的例子,分析了TF树的广播器和监听器最基本的书写形式,从中展示了如何提取和应用TF变换的信息,并介绍了5种最常用的TF树及TF信息的提取工具,感兴趣的朋友一起学习下吧2023-01-01
本文介绍了TF坐标变换的基本概念以及TF在ROS中的表示形式,通过古月居的乌龟跟随的例子,分析了TF树的广播器和监听器最基本的书写形式,从中展示了如何提取和应用TF变换的信息,并介绍了5种最常用的TF树及TF信息的提取工具,感兴趣的朋友一起学习下吧2023-01-01 这篇文章主要介绍了Django 使用 cookie 实现简单的用户管理功能,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-06-06
这篇文章主要介绍了Django 使用 cookie 实现简单的用户管理功能,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-06-06 这篇文章主要介绍了Vim配置的相关资料,包括通用配置,常用插件配置,设置插件的方法,本文给大家讲解的非常详细,需要的朋友可以参考2024-01-01
这篇文章主要介绍了Vim配置的相关资料,包括通用配置,常用插件配置,设置插件的方法,本文给大家讲解的非常详细,需要的朋友可以参考2024-01-01 ChatGPT是一种语言模型,它被训练来对对话进行建模,下面这篇文章主要给大家介绍了关于ChatGpt无法访问或错误码1020的几种解决方案,文中介绍的非常详细,需要的朋友可以参考下2023-02-02
ChatGPT是一种语言模型,它被训练来对对话进行建模,下面这篇文章主要给大家介绍了关于ChatGpt无法访问或错误码1020的几种解决方案,文中介绍的非常详细,需要的朋友可以参考下2023-02-02
将来会是Python、Java、Golang三足鼎立的局面吗
python的优势在于数据处理和人工智能等方向,所以go只可能吞噬Java的份额,很难撼动Python的奶酪,所以将来会是Python、Java、Golang三足鼎立的局面吗2019-04-04 本文主要介绍了postman批量执行接口测试,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-03-03
本文主要介绍了postman批量执行接口测试,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-03-03 MobaXterm 提供丰富的自定义选项,以满足个人偏好和需求,您可以自定义外观、键盘快捷键、字体、颜色方案等,这篇文章主要介绍了MobaXterm快速入门、高级使用技巧,需要的朋友可以参考下2023-06-06
MobaXterm 提供丰富的自定义选项,以满足个人偏好和需求,您可以自定义外观、键盘快捷键、字体、颜色方案等,这篇文章主要介绍了MobaXterm快速入门、高级使用技巧,需要的朋友可以参考下2023-06-06 这篇文章主要为大家介绍了git版本库创建拓展添加文件到版本库教程,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-04-04
这篇文章主要为大家介绍了git版本库创建拓展添加文件到版本库教程,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-04-04 这篇文章主要介绍了如何申请Jetbrains系列软件无限期免费用,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-09-09
这篇文章主要介绍了如何申请Jetbrains系列软件无限期免费用,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-09-09










最新评论