
Java中的LinkedHashMap详解
1. 前言
1.1 浅谈一下
- 第一次真正意义上地接触LinkedHashMap,来自工作中的一个需求:
- SQL查询计划的生成,依赖于Hive的元数据
- 原始的做法是,通过try-with-resource语句,每次访问元数据都新建一个client并立即回收
- 这样的client连接属于短连接,如果每次建立、释放连接的时间占比很高,短连接的做法并不可行
- 因此,想使用长连接,例如连接池,来改造访问逻辑,提高元数据的访问效率
- 既然使用连接池,那就需要及时关闭长时间空间的连接,避免占用资源
- 因此,如何实现空闲连接自动释放成为问题
- 作为菜鸟:我希望在连接中增加一个accessTime字段,然后遍历池中的连接,如果发现距上一次使用超过一定时间,就可以释放连接
- 这其实就跟LRU缓存很像,最近最少使用的连接排位逐渐靠前,达到阈值就被释放
- 同事推荐使用LinkedHashMap实现LRU缓存,及时清理空闲连接
- 通过简单的学习,自己了解到:LinkedHashMap实现LRU缓存,最重要的是重写removeEldestEntry()方法,实现清理空闲连接的逻辑
1.2 按照某种顺序连接哈希表中的所有entry
- 单从类名上看,LinkedHashMap应该是具有链表特性的哈希表
- 回想一下链表的特性:
- 相对数组,链表不需要连续的存储空间,节点(元素)之间通过next引用连接
- 链表中的元素,只能顺序访问,不支持随机访问(顺着next引用查找元素)
- 支持快速地插入或删除元素:一旦确认位置,只需要修改节点之间的引用即可,不存在元素的移位
- 那具有链表特性的哈希表,链接的不可能是桶,更可能的是entry
- 问题1: 是桶中的entry使用链表连接,还是整个哈希表中的entry使用链表连接?
- 分析一下
- HashMap中,同一个桶中的entry已经使用链表连接了
- 这里的链表更有可能是针对哈希表中的所有entry
- 问题2: 将所有entry连接起来,有啥用?
- 学习HashMap和TreeMap时,提到过一个关于entry是否有序的区别
- TreeMap实现了SortedMap,支持按key的自然顺序或自定义比较器的顺序访问entry
- HashMap既不保证entry的顺序,还可能因为扩容导致entry的顺序在一段时间内发生变化
- 如果按照entry的插入顺序,将哈希表中的所有entry连接起来,那就可以实现支持插入顺序的哈希表
- 其实,LinkedHashMap不仅支持按照插入顺序组织entry,还支持按照访问顺序(LRU)组织entry:头部是最近最少访问的entry
- 这也是为啥,同事推荐我使用LinkedHashMap实现LRU
1.3 LinkedHashMap的特性
- 学习一个类之前,如果有完善的类注释,阅读类注释肯定是一个不错的选择
根据类注释,LinkedHashMap的特性如下
- LinkedHashMap使用双向链表,维护了元素的顺序
- LinkedHashMap不仅支持entry的插入顺序,还支持entry的访问顺序
- 默认为entry的插入顺序,通过LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)构造函数,可以创支持于访问顺序的LinkedHashMap
- 整个双向链表分为head和tail,head指向最近最少访问的entry,tail指向最近刚访问的entry。
- 一旦插入或访问entry,会引起entry的顺序变化(被移动得到末尾)
- LinkedHashMap还提供removeEldestEntry()方法,通过重写该方法,可以在新增entry时,删除老旧的entry(位于头部)
注意:
- 如果基于插入顺序,put时更新key已映射的value,不会引起顺序变化;
- 如果基于访问顺序,任何访问操作(如put、get)都将导致顺序的变化。例外: 通过iterator或for-each遍历entry,不影响entry的顺序
- LinkedHashMap的优势:不仅解决了HashMap或HashTable中entry无序的情况,还相对TreeMap的有序实现更节约成本
本人猜测是实现成本,LinkedHashMap是基于HashMap实现的,真正需要编写的代码较少
- LinkedHashMap是非同步的,即非线程安全的
- LinkedHashMap没有对应的线程安全的替代类,只能通过Collections.synchronizedMap()将其转为线程安全的map
- LinkHashMap继承了HashMap,同样也允许null值:只允许一个key为null,允许多个value为null
关于性能
- 与HashMap一样,在hash散列均匀的情况下,LinkedHashMap可以提供常数级的访问效率
- 由于需要维护entry中的双向链表,LinkedHashMap的性能稍逊于HashMap
- 同时,对LinkedHashMap的遍历直接基于双向链表,而非基于桶(遍历特指iterator或for-each遍历,并非确定entry位置时的遍历)
- 因此,LinkHashMap的遍历时间,与entry的数目成正比
LinkedHashMap使用fail-fast迭代器
- 如果使用插入顺序,查询和更新操作不属于结构改变,新增、删除、rehash属于结构改变
- 如果使用访问顺序,任何寻址(查、新增、更新和rehash)或删除操作都属于结构改变
- 迭代器一旦创建,除了迭代器自身的remove方法,任何引起map结构改变的操作,都将使迭代器抛出ConcurrentModificationException
总结一下
- LinkedHashMap使用双向链表维护了entry的顺序:插入顺序或访问顺序
- LinkedHashMap允许null值
- LinkedHashMap是非线程安全的
- LinkedHashMap使用fail-fast迭代器
- 由于需要维护双向链表,LinkedHashMap的性能稍逊于其父类HashMap
- LinkedHashMap的优势:entry有序,且实现成本较低
2. LinkedHashMap概述
2.1 类图
LinkedHashMap类的声明如下
public class LinkedHashMap<K,V> extends HashMap<K,V>
implements Map<K,V>类图,如下图所示
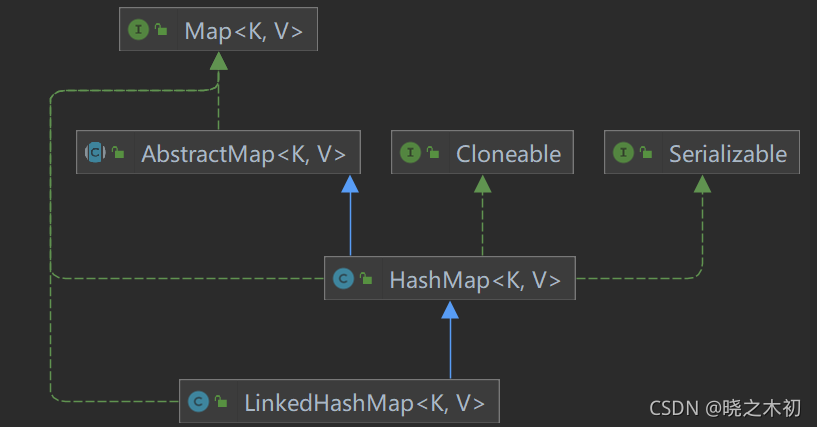
从类图来看
- LinkedHashMap继承了HashMap,说明它具有HashMap的特性(桶数组+ 链表 + 红黑树)
- LinkedHashMap实现了Map接口,额,暂且认为和HashMap一样吧,这个作者的一个小失误,且一直没被源代码的维护人员校正
2.2 成员变量及数据结构
- LinkedHashMap继承了HashMap,那HashMap所特有的桶数组+ 链表 + 红黑树的结构LinkedHashMap也一样具有
- 那是如何在所有的entry中维护一个双向链表的呢?从成员变量就可以解释这个问题
- 新增了三个成员变量
// 双向链表的头部:插入顺序时,是最先插入的entry;访问顺序时,是最近最少访问的entry transient LinkedHashMap.Entry<K,V> head; // 双向链表的尾部:插入顺序时,是最后插入的entry;访问顺序时,是最近刚访问的entry transient LinkedHashMap.Entry<K,V> tail; // 是否使用访问顺序,true表示使用 final boolean accessOrder;
- 其中,Entry的定义如下:增加了 before 和 after 引用,是实现双向链表的关键
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}回忆之前学习HashMap时,关于数据结构的讲解
HashMap中,链表对应的是Node、红黑树对应的是TreeNode
TreeNode继承了LinkedHashMap.Entry,LinkedHashMap.Entry又继承了HashMap.Node
到现在,作者都还有疑问:TreeNode为啥不直接继承HashMap.Node?因为TreeNode的实际使用中,好像没有用到 LinkedHashMap.Entry 中的新增属性
在后面的学习中,通过newNode()、newTreeNode()、afterNodeAccess()、afterNodeRemoval()方法,自己体会到了这样设计的原因
在HashMap中,节点无非是链表节点 Node 或红黑树节点TreeNode
为了实现双向链表,LinkedHashMap中的链表节点 Entry 相对父类 Node 增加了before和after引用
接着,红黑树节点TreeNode继承 LinkedHashMap.Entry,这样LinkHashMap中的节点(链表节点或红黑树节点)具有before和after引用,使得双向链表连接所有entry成为可能
除此之外,TreeNode可以向上转型为 LinkedHashMap.Entry,这样所有节点都当做LinkedHashMap.Entry进行处理,而无需关注是链表节点还是红黑树节点
总结
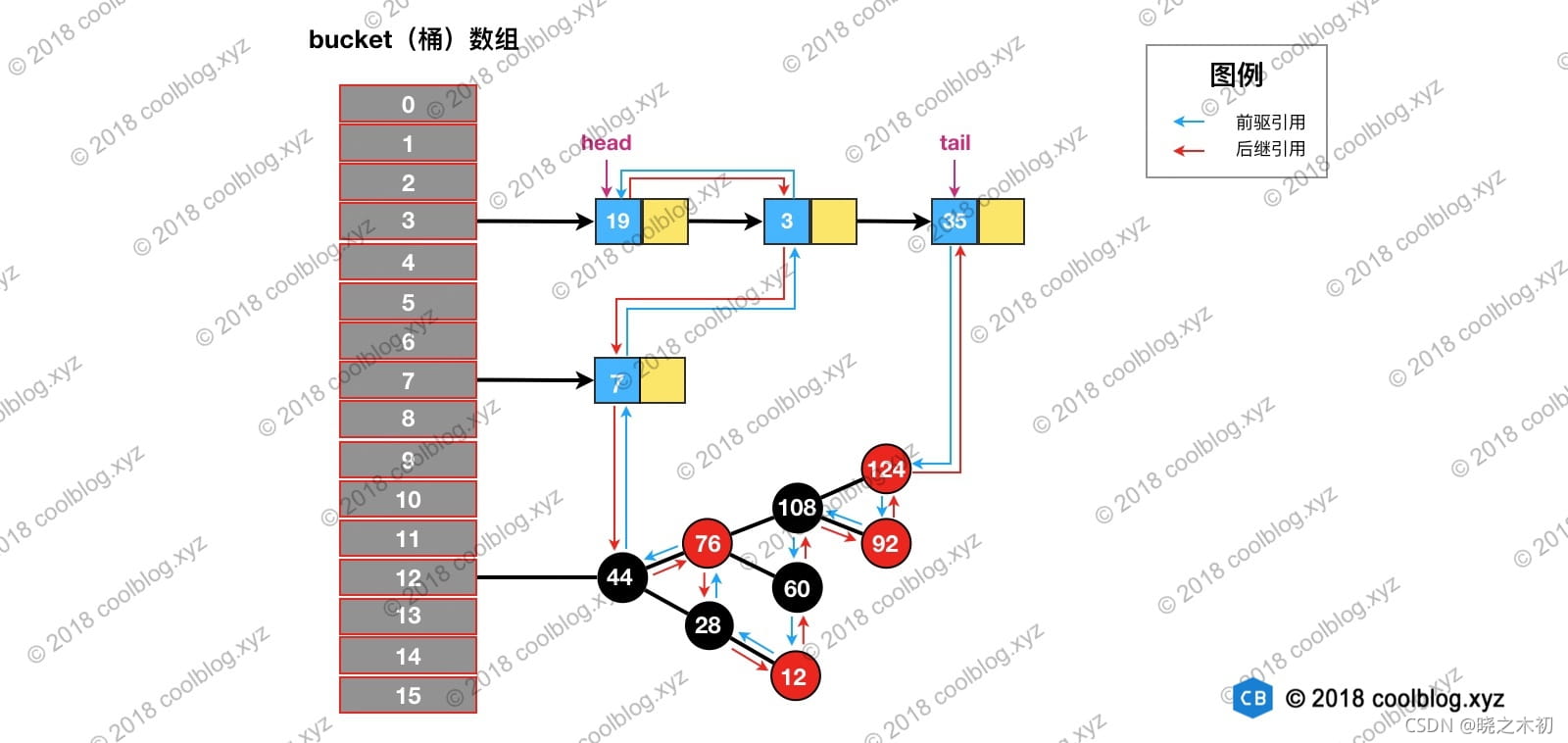
LinkedHashMap依靠Entry的 before 和 after 引用构建双向链表
同时,LinkedHashMap类中的head和tail指出了双向链表的头尾,有助于双向链表的构建及顺序的维护(尾部插入、最近刚访问位于尾部等)
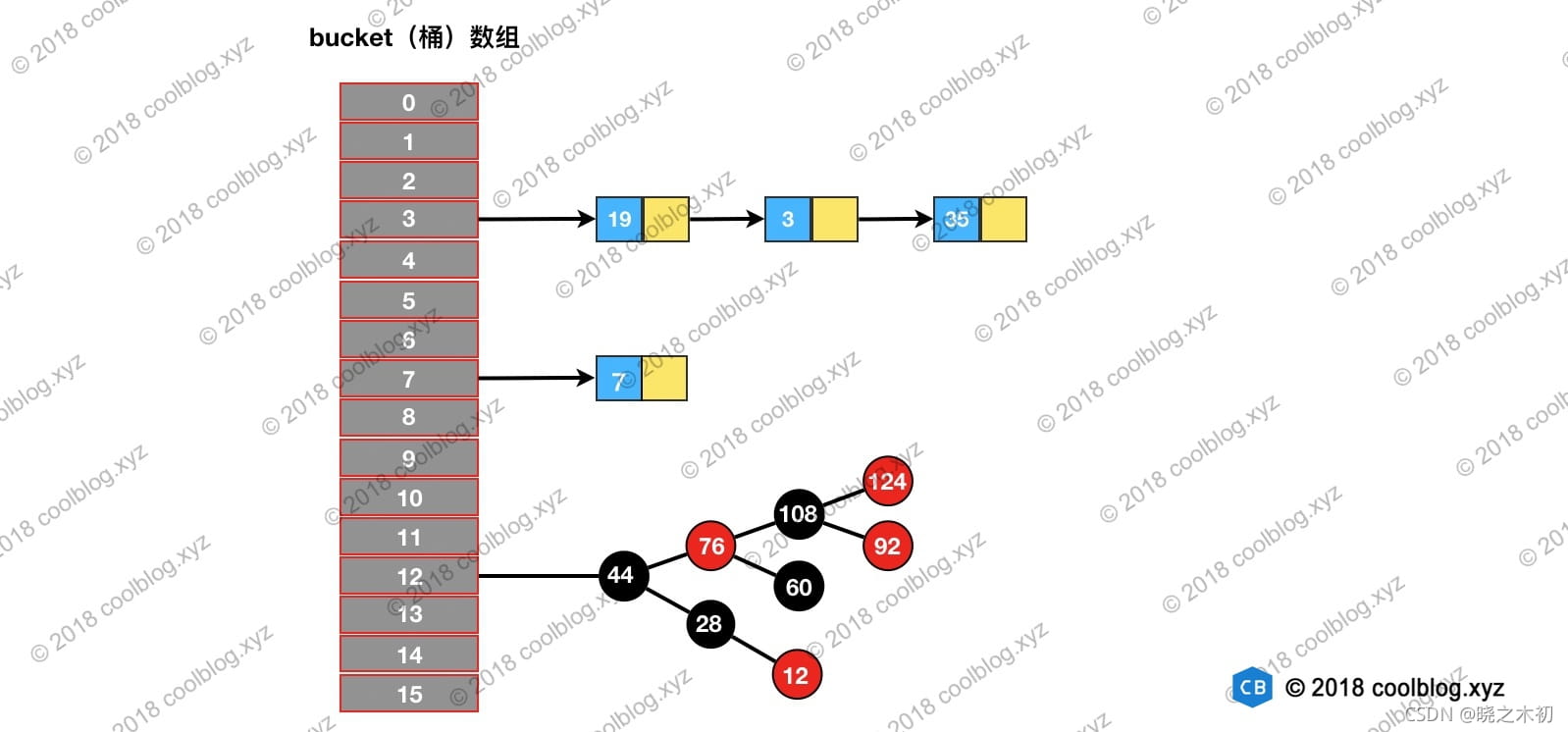
如果,一个HashMap的示意图如下
使用LinkedHashMap后,示意图如下
2.3 构造函数
LinkedHashMap提供如下构造函数
// 创建一个指定了初始化容量和loadFactor的、基于插入顺序的LinkedHashMap
// 对应HashMap的public HashMap(int initialCapacity, float loadFactor)
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
// 创建一个指定了初始化容量的、基于插入顺序的LinkedHashMap
// 对应HashMap的public HashMap(int initialCapacity)
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
// 创建一个基于插入顺序的LinkedHashMap,容量和loadFactor使用默认值
// 对应HashMap的public HashMap()
public LinkedHashMap() {
super();
accessOrder = false;
}
// 基于已有的map,创建一个基于插入顺序的LinkedHashMap,容量和loadFactor使用默认值
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
// 指定初始化容量、loadFactor和顺序的LinkedHashMap,accessOrder为true表示访问顺序
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}最后一个构造函数,是与父类相比,多出来的一个构函数,专为创建基于访问顺序的LinkedHashMap而准备
实现LRU缓存时,都需要使用该构造函数
new LinkedHashMap(capacity, loadFactor, true)
3. 查找方法
LinkedHashMap中,重写的方法很少,查找方法几乎都进行了重写
目的: 为了支持访问顺序,一旦通过查找方法访问了entry,entry的顺序应该发生变化
3.1 get方法
get() 方法的代码如下
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}与HashMap中的方法相比,在获取到entry后,还需要判断是否为访问顺序;如果使用访问顺序,需要通过 afterNodeAccess() 方法调整该entry的位置
3.1.1 afterNodeAccess()方法
afterNodeAccess() 方法在HashMap的 put() 方法中遇到过,但是当时说它是个空方法, LinkedHashMap 重写了该方法
按照本人的理解,afterNodeAccess 方法的作用:在LinkedHashMap使用访问顺序时,将刚访问过的entry移到双向链表末尾
如果entry本身就在末尾,则不用移动
如果entry处于双向链表的头部,则只需要断开与后继节点的关联,然后将其移到末尾
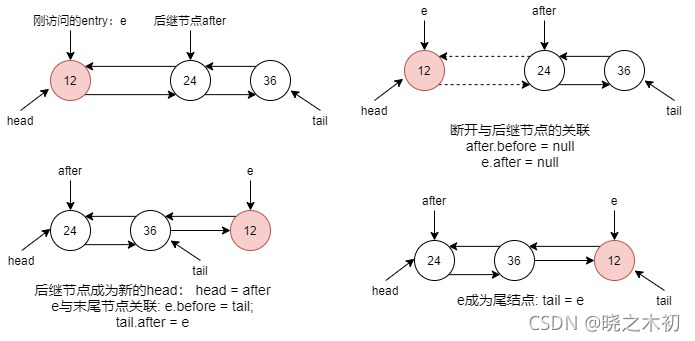
如果entry处于双向链表的中部,则需要先将前驱节点与后继节点连上,然后将其移到末尾(最后一部,需要 e.after = null )
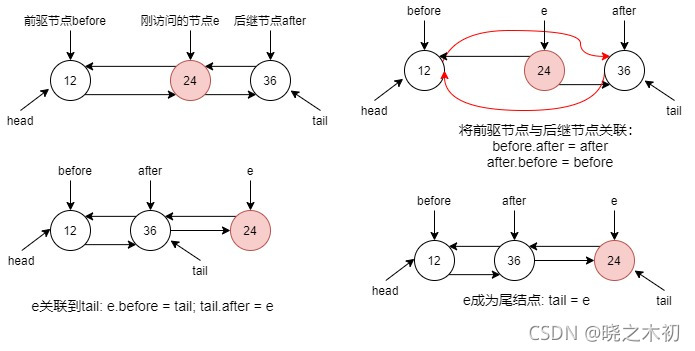
代码如下:不过自己觉得代码逻辑有点乱,貌似还有多余的部分
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) { // 访问顺序且非末尾节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null; // 首先断开与后继节点的关联,非常明智
if (b == null) // 前驱节点为空,说明p在头部,直接将head指向后继节点
head = a;
else // 否则,前驱节点指向后继节点
b.after = a;
if (a != null) // 后继节点指向前驱节点
a.before = b;
else // 这里的代码多余?如果后继节点为null,那p就是末尾了,根本进入不了if???
last = b;
if (last == null) // 这里也是因为上一步导致的多余判断
head = p;
else { // 将p移到末尾
p.before = last;
last.after = p;
}
tail = p; // 更新tail引用
++modCount;
}
}3.2 getOrDefault / containsValue方法
3.2.1 getOrDefault方法
与get方法一样, getOrDefault() 方法,也增加了对 accessOrder 为true的处理
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return defaultValue;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}3.2.2 containsValue方法
查找类的方法,get、getOrDefault都重写了,按理说containsKey和containsValue也应该重写的
但LinkedHashMap只重写了containsValue方法
仔细想想也是有道理的:
- 判断是否包含key,只需要通过getNode获取到key对应entry就行了
- 判断是否包含value,需要遍历桶中的每个entry(双层循环,外层为桶,内层为桶中的元素)
- LinkedHashMap中,所有的entry使用双向链表关联,查找value直接基于双向链表顺序查找即可
containsValue的代码如下,十分简单
public boolean containsValue(Object value) {
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true;
}
return false;
}4. put方法
LinkedHashMap就没有重写put方法,因为HashMap中,put方法的核心方法 putVal() 已经未雨绸缪了
putVal() 方法中,存在对entry被访问或新增entry后,调整双向链表的空方法: afterNodeAccess() 和 afterNodeInsertion()
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// 省略一些代码
else {
// 存在key的映射,则需要更新value;如果是访问顺序,需要将entry移到末尾
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); // 将entry移到末尾
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict); // 新增节点,需要调整链表
return null;
}想要实现LinkedHashMap,只需要重写上述两个方法就可以了。
所以,这也是为啥LinkedHashMap没有重写put() 方法
4.1 afterNodeInsertion方法
一开始,自己认为 afterNodeInsertion() 方法要完成如下事情
不管是插入顺序还是访问顺序,新增的entry都应该位于双向链表的尾部,由 afterNodeInsertion() 方法完成这一操作然后根据 removeEldestEntry() 的结果,来决定是否删除最老的entry
后来一看,怎么 afterNodeInsertion() 方法的定义如下:入参都不是刚插入的entry
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// 头节点不为null,且需要删除最老的节点,则删除头结点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}其入参evict,是驱逐的意思,在 put() --> putVal() 时固定为true
也就是说,在调用 afterNodeInsertion() 方法时,evict固定为true
是否会删除最老的entry,由 removeEldestEntry() 方法决定
removeEldestEntry() 方法如下,总是返回false。
即:LinkedHashMap就算使用访问顺序,也只是让最老的entry位于头部,并不会删除这也是为什么,在使用LinkedHashMap实现LRU时,一般都需要重写 removeEldestEntry() 方法,让其在某种情况下返回true,实现过期元素的清理
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}4.2 newNode和newTreeNode方法
问题来了:既然 afterNodeInsertion() 方法只负责删除最老的元素,在哪里完成entry加入双向链表的呢?仔细阅读 putVal() 方法,发现新增entry时,通过 newNode() 和 newTreeNode() 完成节点的新建LinkedHashMap重写了这两个新建节点的方法,在这两个方法中完成了entry加入双向链表的逻辑
newNode()方法
不再是简单的 return new Node<>() ,而是新建 LinkedHashMap.Entry ,并将其加入双向链表末尾
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 将p放到链表末尾
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
// 原尾节点为null,表明p是第一个节点,head指向p
if (last == null)
head = p;
else { // 否则,将p和原尾结点关联
p.before = last;
last.after = p;
}
}newTreeNode方法
不再是简单的 return new TreeNode<>() ,而是创建一个TreeNode,并将其加入双向链表尾部
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
linkNodeLast(p);
return p;
}5. remove方法(afterNodeRemoval)
在学习HashMap的remove方法时,两种remove方法的核心都是通过 removeNode() 方法实现节点的删除
removeNode() 方法的末尾,有一个空的 afterNodeRemoval() 方法
学了 afterNodeAccess 和afterNodeInsertion, 应该能触类旁通:LinkedHashMap会重写 afterNodeRemoval() 方法,实现删除entry后的双向链表调整
afterNodeRemoval() 方法,代码如下
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null; // 主动断开p与其他entry的关联
if (b == null) // p是头节点,则head指向其后继节点
head = a;
else // 否则,前驱节点指向后继节点
b.after = a;
if (a == null) // p是尾结点,tail指向前驱节点
tail = b;
else // 后继节点指向前驱节点
a.before = b;
}要是我写的话,我可能会这样实现
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 先断开p与其他节点的关联
p.before = p.after = null;
// 情况1: p是头结点也是尾节点
if (head == p && head == tail) {
head = tail = null;
} else if (head == p) { // 情况2:p是头结点
a.before = null;
head = a;
} else if (tail == p) { // 情况3:p是尾节点
b.after = null;
tail = b;
} else { // 情况4:p是中间节点
b.after = a;
a.before = b;
}
}按照我的思路,发现写源码的人,脑袋就是灵活
b为空,说明p是头结点,直接将head指向a;可以涵盖情况1( head = a = null )、情况2( head = a, a != null )否则,将 b.after 指向a;可以涵盖情况3( b.after = a = null )、情况4( b.after = a, a != null )a为空,说明p是尾结点,直接将tail指向b;可以涵盖情况1( tail = b = null )、情况3( tail = b, b! = null )否则,将 a.before 指向b;可以涵盖情况2( a.before = b = null )、情况4( a.before = b, b! = null )
这里就不画图展示了,读者可以先画出四种情况的图,再结合图阅读源代码
6. 总结
6.1 基于LinkedHashMap实现LRU缓存
在不考虑线程安全的情况下,基于LinkedHashMap实现LRU缓存,是最简单快捷的方式
只需要重写 removeEldestEntry() 方法,使其在达到阈值时返回true,即可删除最近最少使用的数据
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private int maxSize;
public LRUCache(int maxSize) {
super(16, 0.75f, true);
this.maxSize = maxSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxSize;
}
public static void main(String[] args) {
LRUCache<String, Integer> cache = new LRUCache<>(5);
cache.put("张三", 21);
cache.put("lucy", 24);
cache.put("john", 30);
cache.put("jack", 25);
cache.put("李四", 20);
// 插入第6个元素,最后发现最先插入的key-value被删除
cache.put("王二", 32);
System.out.println("张三的信息已不存在: " + !cache.containsKey("张三"));
}
}6.2 LinkedHashMap如何维护顺序的?
首先,LinkedHashMap基于HashMap实现了有序的哈希表
其次,LinkedHashMap的有序是通过双向链表维护的,其在数据结构上就做了工作
节点类型为LinkedHashMap.Entry,相对父类HashMap.Node,多了 before 和 after 引用,用于在entry间构建双向链表为了更好地维护entry的顺序、更快地查找entry,LinkedHashMap类中,增加了 head 和 tail 引用LinkedHashMap类中,还增加了 accessOrder 变量,以决定是维护插入顺序还是访问顺序
然后,LinkedHashMap还通过重写以下方法,维护entry在双向链表中的顺序
void afterNodeAccess(Node<K,V> p) void afterNodeRemoval(Node<K,V> p) Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next)
除此之外,提供了删除最近最少访问entry的方法,有助于实现LRU
void afterNodeInsertion(boolean evict) // 关键需要重写removeEldestEntry()
6.3 LinkedHashMap与HashMap的联系
二者的联系:LinkedHashMap继承了HashMap,基于双向链表维护了entry的顺序
数据结构上:Entry增加before和after引用,LinkedHashMap增加head、tail引用
继承与重载上:LinkedHashMap相当于站在巨人的肩膀上做事,只实现了一些关键的方法
get() 和getOrDefault() ,增加了维护访问顺序的代码
containsValue(),不再基于桶遍历entry,而是直接基于双向链表遍历entry
putVal()中,新增节点的newNode() 和newTreeNode() 方法都重写了,实现了节点上链
同时,putVal()中,afterNodeInsertion()被重写,可以在removeEldestEntry() 返回true时,实现LRU缓存
removeNode()方法中,最后调用的afterNodeRemoval() 方法以删除双向链表中的对应节点
6.4 LinkedHashMap与HashMap的异同
相同点:
都实现了Map接口,允许null值
都是非线程安全的map类,需要通过Collections.synchronizedMap()转为安全的map类,或使用已有的、线程安全的替代类
都使用fail-fast迭代器,一旦创建好迭代器,除非使用迭代器自身的remove方法,其他任何改变map结构的方法,都将触发ConcurrentModificationException
其他的,扩容、链表转红黑树、红黑树退回链表等,LinkHashMap都和HashMap一样
不同点
最大的不同点:LinkedHashMap通过双向链表为了entry的顺序,插入顺序或访问顺序;HashMap中的entry不仅无序,迭代结果还可能在一段时间内发生变化
其他的,无非是实现上的不同,例如,containsValue(),不再基于桶遍历entry,而是直接基于双向链表遍历entry
到此这篇关于Java中的LinkedHashMap详解的文章就介绍到这了,更多相关Java的LinkedHashMap内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 因工作需求,需要根据用户的数据权限,来查询并展示相应的数据,那么就需要动态拦截sql,本文就来介绍了MyBatis的动态拦截sql并修改,感兴趣的可以了解一下2023-11-11
因工作需求,需要根据用户的数据权限,来查询并展示相应的数据,那么就需要动态拦截sql,本文就来介绍了MyBatis的动态拦截sql并修改,感兴趣的可以了解一下2023-11-11 在本文中,我们将详细介绍从BeanFactory中获取bean的多种方式。简单地说,正如方法的名称所表达的,getBean()负责从Spring IOC容器中获取bean实例,希望对大家有所帮助2023-02-02
在本文中,我们将详细介绍从BeanFactory中获取bean的多种方式。简单地说,正如方法的名称所表达的,getBean()负责从Spring IOC容器中获取bean实例,希望对大家有所帮助2023-02-02 这篇文章主要介绍了Redis六大数据类型使用方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-12-12
这篇文章主要介绍了Redis六大数据类型使用方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-12-12
SpringMVC注解@RequestParam方法原理解析
这篇文章主要介绍了SpringMVC注解@RequestParam方法原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-04-04 这篇文章主要介绍了Java多线程编程实战之模拟大量数据同步,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-02-02
这篇文章主要介绍了Java多线程编程实战之模拟大量数据同步,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-02-02 读万卷书不如行万里路,只学书上的理论是远远不够的,只有在实战中才能获得能力的提升,本篇文章手把手带你用Java 集合实现一个客户信息管理系统,大家可以在过程中查缺补漏,提升水平2021-11-11
读万卷书不如行万里路,只学书上的理论是远远不够的,只有在实战中才能获得能力的提升,本篇文章手把手带你用Java 集合实现一个客户信息管理系统,大家可以在过程中查缺补漏,提升水平2021-11-11 这篇文章主要介绍了SpringSecurity登录使用JSON格式数据的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-02-02
这篇文章主要介绍了SpringSecurity登录使用JSON格式数据的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-02-02 这篇文章主要介绍了Java数据结构之循环链表、栈的实现方法,结合实例形式分析了Java数据结构中循环链表、栈、的功能、定义及使用方法,需要的朋友可以参考下2021-08-08
这篇文章主要介绍了Java数据结构之循环链表、栈的实现方法,结合实例形式分析了Java数据结构中循环链表、栈、的功能、定义及使用方法,需要的朋友可以参考下2021-08-08 这篇文章主要介绍了java识别一篇文章中某单词出现个数的方法,涉及java字符解析操作的相关技巧,具有一定参考借鉴价值,需要的朋友可以参考下2015-10-10
这篇文章主要介绍了java识别一篇文章中某单词出现个数的方法,涉及java字符解析操作的相关技巧,具有一定参考借鉴价值,需要的朋友可以参考下2015-10-10 本文主要介绍了Java分布式锁的三种实现方案。具有一定的参考价值,下面跟着小编一起来看下吧2017-01-01
本文主要介绍了Java分布式锁的三种实现方案。具有一定的参考价值,下面跟着小编一起来看下吧2017-01-01










最新评论