
解析java稀疏数组如何帮助我们节省内存提升性能
什么是稀疏矩阵
稀疏矩阵是指矩阵中大部分元素为零的矩阵。在实际应用中,很多矩阵都是稀疏的,比如网络图、文本数据等。由于矩阵中存在大量的零元素,因此稀疏矩阵的存储和计算都具有一定的特殊性。
一般来说,在矩阵中,若数值为0的元素数目远远多于非0元素的数目,并且非0元素分布没有规律时,则称该矩阵为稀疏矩阵;与之相反,若非0元素数目占大多数时,则称该矩阵为稠密矩阵。下面的矩阵就是一个典型的稀疏矩阵:

优化稀疏矩阵数据存储的方法
1.直接存储为二维矩阵
使用二维矩阵作为电子表格的存储方法具有简单直接的优点,可以避免频繁地创建或删除内存段。然而,需要指出的是,这种方式在存储值时可能会有一些不太高效的方面,因为它会占用大量的存储空间来保存没有实际内容的单元格。
在实际应用中通常使用三元组表示稀疏矩阵:
三元组的表示方法是:对于一个 m×n 的稀疏矩阵 A,我们只存储矩阵中非零元素的信息,具体来说,将每个非零元素的行下标、列下标和值存储下来,得到一个三元组(i,j,Ai,j),其中 i 是行下标,j 是列下标,Ai,j 是 A 中对应位置的值。
以前面举的稀疏矩阵为例,其三元组表示如下:
(1, 4, 6)
(2, 2, 5)
(3, 3, 4)
直接存储为二维矩阵的复杂度:
- 占用空间:O(N2) 。
- 插入数据:需要破坏矩阵。
- 删除数据:需要破坏矩阵。
- 搜索数据:O(N2)。
- 访问数据:O(1)。
N是假设行和列具有相同长度并形成正方形矩阵的行/列数。
2.通过键值对(Map, Dictionary)优化
通过键值对(Map, Dictionary)来优化,主要是利用哈希表的特性来快速查找元素。具体来说,可以将需要查找的元素作为键,将存储这些元素的数据结构作为值,然后将它们存储在一个哈希表中。这样,当需要查找某个元素时,只需要使用该元素作为键,通过哈希表的查找操作即可快速找到对应的值。
在实际应用中,常见的情况包括:
- 缓存数据:在需要频繁访问数据的场景中,通过建立一个缓存,将数据存储在一个键值对的数据结构中,可以显著提高数据的访问效率。
- 字符串处理:在需要对字符串进行匹配、查找等操作的场景中,可以将字符串作为键,将相应的处理结果作为值,存储在一个键值对的数据结构中,可以大幅提高字符串处理的效率。
- 数据库操作:在需要对数据库进行访问的场景中,可以使用键值对数据结构来存储查询结果,避免重复执行查询操作,减轻数据库的负载。
在下图中,将单元格位置和对应的单元格值以键值对的形式进行了存储。

通过键值对(Map, Dictionary)优化稀疏数组的复杂度:
- 空间:O(N)。
- 插入:O(1)。
- 删除:O(1)。
- 搜索:O(N)。
- 访问:O(1)。
N为所记录的条目数。
3.通过数组存储方式优化
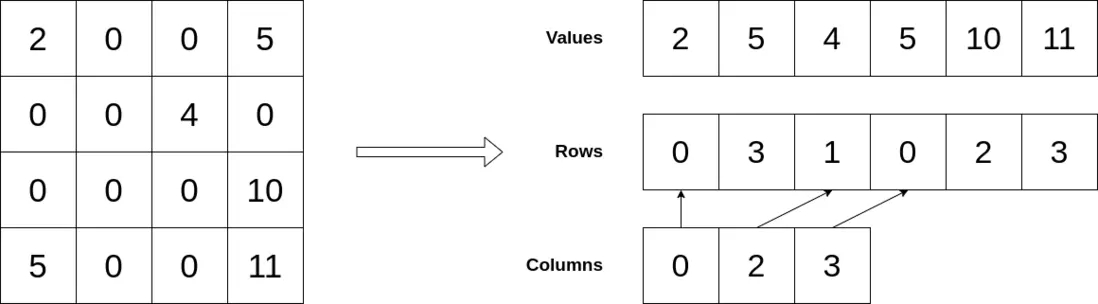
在稀疏矩阵中,我们可以使用三个不同的数组来存储行索引、列偏移、和其中的值,而不是直接在二维矩阵中存储值。
存储的三个数组:
- 值 =\>单元格中的值。
- 行索引=\>单元格的行索引。
- 列偏移=\>这里每个索引都代表列,并且该数组将行开始的索引值存储在 Row 数组中。
下图为将稀疏数组转化为数组的形式:
稀疏矩阵具体的插入,删除,搜索,访问的代码:
import java.util.HashMap;
import java.util.Map;
class SparseMatrix {
private int rows;
private int cols;
private Map<String, Integer> matrix;
public SparseMatrix(int rows, int cols) {
this.rows = rows;
this.cols = cols;
this.matrix = new HashMap<>();
}
public void insert(int row, int col, int value) {
if (row < 0 || row >= rows || col < 0 || col >= cols) {
throw new IndexOutOfBoundsException("Invalid matrix index");
}
if (value != 0) {
String key = row + "," + col;
matrix.put(key, value);
}
}
public void delete(int row, int col) {
String key = row + "," + col;
matrix.remove(key);
}
public int search(int row, int col) {
String key = row + "," + col;
return matrix.getOrDefault(key, 0);
}
public int access(int row, int col) {
if (row < 0 || row >= rows || col < 0 || col >= cols) {
throw new IndexOutOfBoundsException("Invalid matrix index");
}
String key = row + "," + col;
return matrix.getOrDefault(key, 0);
}
}在上述代码中,定义了一个 SparseMatrix 类来表示稀疏矩阵。在构造函数中,我们传入矩阵的行数和列数,并创建了一个 HashMap 对象 matrix 来存储非零元素。insert 方法用于向矩阵中插入元素,如果插入的值不为零,则将其加入 matrix 中,其中键为字符串形式的 row,col。delete 方法用于删除指定位置的元素,通过 remove 方法从 matrix 中移除对应的键值对。search 方法用于搜索指定位置的元素,通过调用 getOrDefault 方法从 matrix 中获取对应的值,如果不存在则返回默认值 0。access 方法用于访问指定位置的元素,如果超出矩阵边界则抛出异常,通过调用 getOrDefault 方法从 matrix 中获取对应的值。
通过稀疏矩阵存储方式优化的复杂度:
- 空间:O(N)。
- 插入:O(N)。
- 删除:O(N)。
- 搜索:O(N)。
- 访问:O(1)。
总结
相较于传统的数组存储或键值对存储,稀疏矩阵存储采用一种基于行索引的数据字典存储方法,这种方法在处理松散布局的表格数据时表现出色。与其他存储方式不同,稀疏矩阵只存储非空数据,无需额外开辟内存空间来存储空数据。这种特殊存储策略使得数据片段化变得容易,可以随时框取整个数据层中的一片数据进行序列化或反序列化。如果在项目开发中需要存储类似结构的数据,使用稀疏矩阵存储方式能够显著提升性能,无论从时间还是空间上都有很大的优势,葡萄城公司的纯前端表格控件——SpreadJS正是借助此功能实现了高性能渲染能力(100 毫秒内加载 10 万行数据)。
以上就是解析java稀疏数组如何帮助我们节省内存提升性能的详细内容,更多关于java稀疏数组提升内存的资料请关注脚本之家其它相关文章!
相关文章
 在本篇文章里小编给大家分享了一篇关于java的主要特性学习总结内容,有兴趣的朋友们可以参考下。2020-05-05
在本篇文章里小编给大家分享了一篇关于java的主要特性学习总结内容,有兴趣的朋友们可以参考下。2020-05-05
java文件操作报错:java.io.FileNotFoundException(拒绝访问)问题
在进行编程时,经常会遇到因疏忽小细节而导致的错误,如忘记在路径后添加文件名,本文通过一个具体的修改前后对比示例,解释了错误原因,并给出了解决方案,这类经验分享对编程学习者具有参考价值2024-10-10 SnowFlow算法是Twitter推出的分布式id生成算法,主要核心思想就是利用64bit的long类型的数字作为全局的id。本文将用Java语言实现雪花算法,感兴趣的可以学习一下2022-03-03
SnowFlow算法是Twitter推出的分布式id生成算法,主要核心思想就是利用64bit的long类型的数字作为全局的id。本文将用Java语言实现雪花算法,感兴趣的可以学习一下2022-03-03
Red Hat 安装JDK与IntelliJ IDEA的详细过程
YUM是基于Red Hat的Linux发行版的一个强大而用户友好的包管理工具,这篇文章主要介绍了Red Hat安装JDK与IntelliJ IDEA,需要的朋友可以参考下2023-08-08 这篇文章主要介绍了SpringBoot通过AOP实现对全局接口访问次数的统计,文章从相关问题展开全文内容详情,具有一定的参考价值,需要的小伙伴可以参考一下2022-06-06
这篇文章主要介绍了SpringBoot通过AOP实现对全局接口访问次数的统计,文章从相关问题展开全文内容详情,具有一定的参考价值,需要的小伙伴可以参考一下2022-06-06 本篇文章是对ServletContext中的常用方法进行了详细的分析介绍,需要的朋友参考下2013-07-07
本篇文章是对ServletContext中的常用方法进行了详细的分析介绍,需要的朋友参考下2013-07-07 OpenFeign源于Netflix的Feign,是http通信的客户端。屏蔽了网络通信的细节,直接面向接口的方式开发,让开发者感知不到网络通信细节。所有远程调用,都像调用本地方法一样完成2023-02-02
OpenFeign源于Netflix的Feign,是http通信的客户端。屏蔽了网络通信的细节,直接面向接口的方式开发,让开发者感知不到网络通信细节。所有远程调用,都像调用本地方法一样完成2023-02-02
springboot+vue实现Minio文件存储的示例代码
本文主要介绍了springboot+vue实现Minio文件存储的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2024-02-02 说到Spring Boot 单元测试主要有两个主流集成分别是Mockito,Junit,这个各有特点,在实际开发中,我想要的测试框架应该是这个框架集成者,本文给大家介绍了SpringBoot利用Junit动态代理实现Mock方法,需要的朋友可以参考下2024-04-04
说到Spring Boot 单元测试主要有两个主流集成分别是Mockito,Junit,这个各有特点,在实际开发中,我想要的测试框架应该是这个框架集成者,本文给大家介绍了SpringBoot利用Junit动态代理实现Mock方法,需要的朋友可以参考下2024-04-04 最近学习java,接触到了回调机制(CallBack)。初识时感觉比较混乱,而且在网上搜索到的相关的讲解,本文介绍了Java的回调机制,有兴趣的同学可以了解一下2016-10-10
最近学习java,接触到了回调机制(CallBack)。初识时感觉比较混乱,而且在网上搜索到的相关的讲解,本文介绍了Java的回调机制,有兴趣的同学可以了解一下2016-10-10










最新评论