
Spring data jpa缓存机制使用总结
Spring data jpa缓存机制
Spring data jpa 的使用让我们操作数据库变得非常简单,开发人员只需要编写repository接口,Spring将自动提供实现,尤其是基础的的CURD 操作,为我们封装好的同时也做了一些性能上的优化。
但也正因为如此,这些基础的操作的背后并不是那么简单,稍有不慎就会得到我们意料之外的结果,接下来列举一些工作中遇到的问题。
一、案例
项目中遇到过这样一个问题,repository继承了CrudRepository接口,直接使用save(S entity) 方法进行数据保存,但是因为某个字段的唯一约束冲突了,导致保存失败并抛出了异常,但是save方法后的代码逻辑却执行了,将数据保存到redis,这导致了数据库和redis数据不一致。
代码代码大概是这样子:
@Override
@Transactional
public void save(SomeThingVo vo){
SomeThingEntity entity = new SomeThingEntity();
BeanUtils.copyProperties(vo,entity);
//保存至数据库
someThingRepository.save(entity);
//缓存
cacheSomeThing(entity);
//做一些其他事
doSomeThingElse();
}然后对这个操作进行了debug,发现到save方法结束,是没有抛出异常的,然后继续进行保存redis等操作,直到方法结束才抛出了异常。
这时注意到了@Transactional注解加在了这个方法之上,那就是事务提交时才会报出 唯一约束冲突的异常,再联想到Spring data Jpa的是用Hibernate实现的 , Hibernate是有缓存机制的,猜想不使用jpa自带的save方法,就可以在保存时直接抛异常,而不执行之后的代码,然后进行尝试,的确如此;还有一种解决方式是使用saveAndFlush方法,立马将缓存中的实体bean刷入数据库。
二、分析
Hibernate缓存包括两大类:一级缓存和二级缓存。
一级缓存又称为“Session的缓存”,它是内置的,不能被卸载(不能被卸载的意思就是这种缓存不具有可选性,必须有的功能,不可以取消session缓存)。由于Session对象的生命周期通常对应一个数据库事务或者一个应用事务,因此它的缓存是事务范围的缓存在第一级缓存中,持久化类的每个实例都具有唯一的OID。我们使用@Transactional 注解时,JpaTransactionManager会在开启事务前打开一个session,将事务绑定在这个session上,事务结束session关闭,所以后续内容将以粗略以事务作为一级缓存的生存时段。
二级缓存又称为“SessionFactory的缓存”,由于SessionFactory对象的生命周期和应用程序的整个过程对应,因此二级缓存是进程范围或者集群范围的缓存,有可能出现并发问题,因此需要采用适当的并发访问策略。第二级缓存是可选的,是一个可配置的插件,在默认情况下,SessionFactory不会启用这个插件,二级缓存应用场景局限性比较大,适用于数据要求的实时性和准确性不高、变动很少的情况,此次我们仅针对一级缓存进行详细说明。
我们使用CrudRepository.save() 方法保存或更新对象的流程如下
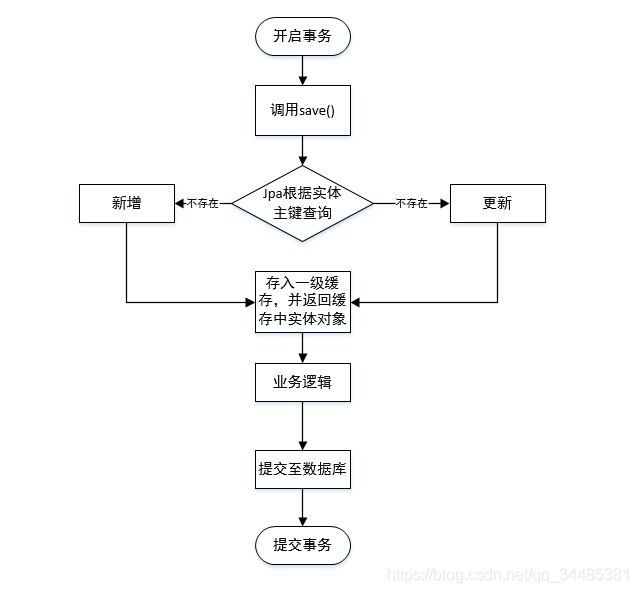
从上图可以看出每次save方法执行时都会用主键向数据库发起一次查询,来判断是更新还是插入,此时spring data jpa 不会立马向数据库发送命令,而是将这条数据保存在一级缓存之中,然后返回缓存中实体对象,接下来继续执行后续的代码。
如果想更新这条数据的值,可以直接修改这个实体对象,jpa会在事前提交之前的某个点(具体后面会说明)自动将这些变更的数据保存至数据库,并且在事务期间查询这条数据都是优先从缓存中获取数据。
一级缓存的作用还是很明显的,在整个事务中,在对同一条数据进行了保存更新查询操作都会以尽量少地请求数据库的方式进行优化,降低了网络io开销。
三、联想
有利就有弊,就像第一部分描述的,因为延迟提交 ,数据的正确性验证(数据库限制方面,比如约束)并没有立马执行,有时候完全是我们不能承受的,我们想要的效果并不是这样。
接下来设想一下其他场景:
1、何时会将数据提交至数据库?
实际上这中情况是不存在的。
测试代码和结果如下:
@Transactional(rollbackFor = {Exception.class})
public SomeThingEntity save(SomeThingVo vo) {
SomeThingEntity entity = new SomeThingEntity();
BeanUtils.copyProperties(vo,entity);
SomeThingEntity someThingEntity = someThingRepository.save(entity);
log.info("保存方法结束");
String code = "GOODS_" + someThingEntity.getCode() ;
someThingEntity.setCode(code);
log.info("开始查找");
SomeThingEntity searchThing = someThingRepository.searchByCode(code);
log.info("查找结果:{}" , searchThing);
SomeThingEntity getThing = someThingRepository.getOne(someThingEntity.getId());
log.info("执行了一次JPA查询\n\r" +
"someThingEntity == getThing : {}\n\r" +
"searchThing == getThing :{}" , someThingEntity == getThing , searchThing == getThing );
return someThingEntity;
}
打印日志:
1 Hibernate: select somethinge0_.id as id1_3_0_, somethinge0_.code as code2_3_0_, somethinge0_.description as descript3_3_0_, somethinge0_.price as price4_3_0_ from tb_something somethinge0_ where somethinge0_.id=?
2 保存方法结束
3 开始查找
4 Hibernate: insert into tb_something (code, description, price, id) values (?, ?, ?, ?)
5 Hibernate: update tb_something set code=?, description=?, price=? where id=?
6 Hibernate: select somethinge0_.id as id1_3_, somethinge0_.code as code2_3_, somethinge0_.description as descript3_3_, somethinge0_.price as price4_3_ from tb_something somethinge0_ where somethinge0_.code=?
7 查找结果:SomeThingEntity(id=5, code=GOODS_005, price=100, description=书包)
8 执行了一次JPA查询
9 someThingEntity == getThing : true
10 searchThing == getThing :true
11 Hibernate: update tb_something set code=?, description=?, price=? where id=?
从日志可见:
- save()方法执行时只打印了一个查询sql
- someThingRepository.searchByCode()方法执行前各打印了一条插入sql和更新sql
- someThingRepository.searchByCode() 进行了查询
- getOne()并没有打印sql,直接获取缓存中的对象
最后比对这些实体都是同一个对象,即缓存中的对象。
将代码中someThingRepository.searchByCode方法改为其他读写语句,尝试多次,得出以下结论:
(1)未提交至数据库的操作会在下次请求到数据库时一起提交至数据库执行
(2)在事务提交前存在未提交的数据,会提交至数据库执行
2、实体对象加入缓存后
我们写sql更新数据,再用自己的sql获取这条数据,得到的是缓存中的数据还是更新后的数据
这次测试代码和结果如下:
@Transactional(rollbackFor = {Exception.class})
public SomeThingEntity save(SomeThingVo vo) {
SomeThingEntity entity = new SomeThingEntity();
BeanUtils.copyProperties(vo,entity);
SomeThingEntity someThingEntity = someThingRepository.save(entity);
log.info("开始更新");
Integer fenPrice = entity.getPrice() * 100;
someThingRepository.updatePriceByCode(someThingEntity.getCode(),fenPrice);
//Session session = (Session) entityManger.getDelegate();
//session.clear();
SomeThingEntity searchThing = someThingRepository.searchByCode(someThingEntity.getCode());
log.info("searchThing = {}",searchThing);
log.info("searchThing == someThingEntity {}",searchThing == someThingEntity);
//someThingEntity.setDescription("");
return someThingEntity;
}传入参数:{id=20,code='GOODS_020",price=100,description="书包"}
打印日志:
1Hibernate: select somethinge0_.id as id1_3_0_, somethinge0_.code as code2_3_0_, somethinge0_.description as descript3_3_0_, somethinge0_.price as price4_3_0_ from tb_something somethinge0_ where somethinge0_.id=?
2 开始更新
3 Hibernate: insert into tb_something (code, description, price, id) values (?, ?, ?, ?)
4 Hibernate: update tb_something set price=? where code=?
5 Hibernate: select * from tb_something where code = ?
6 searchThing = SomeThingEntity(id=20, code=GOODS_020, price=100, description=书包)
7 searchThing == someThingEntity true
数据库结果:{id=20,code='GOODS_020",price=10000,description="书包"}
从日志中可见:
someThingRepository.updatePriceByCode(someThingEntity.getCode(),fenPrice) 执行打印了相关更新sql(第4行日志),目的 将price由100 改为10000
我们的查询方法向数据库发起了查询;
打印的结果不是我们更新后的结果,price仍然为100;
查询的结果对象和缓存中的对象比较,是同一个对象;
测试说明:
执行我们的查询方法后,jpa返回给我们的仍然是缓存中的值,这样子的话我们在这个事务中怎么查询都拿不到我们变更后的值! jpa不会根据我们的update方法自动刷新缓存,后边查询出来的数据也不会覆盖缓存中的数据。
那么一些同学可能会把一个事务涵盖内容的比较多,在顶层的service就加了@Transactional ,就可能在一些操作上进入了这样的场景,在缓存存在的情况,手动update,后续有去查询使用,最终使用了错误的数据。
如果非要在当前事务中查询到正确数据的话,那就手动清除session中的缓存吧(上述代码中 10、11行)。
另外,放开上述代码中的15行,最终保存在数据库的结果为 {id=20,code='GOODS_020",price=100,description=""} ,price的值会被缓存中的覆盖。
总结
Spring data jpa 的这些操作都是简单常用而又容易忽视的,我们在使用时要考虑一下是否得当。
对于这样的缓存机制我们要做的是 将事务控制在合适的范围,将不需要在事务中执行的内容就移出去;在需要sql明确执行好的情况,就主要避开使用会延迟提交的方法。
规范的代码和设计是质量的一个重要保证之一。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要介绍了JAVA抛出异常的三种形式详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-07-07
这篇文章主要介绍了JAVA抛出异常的三种形式详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-07-07 这篇文章主要介绍了Spring Boot定时任务的使用实例代码,需要的朋友可以参考下2017-04-04
这篇文章主要介绍了Spring Boot定时任务的使用实例代码,需要的朋友可以参考下2017-04-04 AOP包括连接点(JoinPoint)、切入点(Pointcut)、增强(Advisor)、切面(Aspect)、AOP代理(AOP Proxy),具体的方法和类型下面文章会举例说明,感兴趣的小伙伴和小编一起阅读全文吧2021-09-09
AOP包括连接点(JoinPoint)、切入点(Pointcut)、增强(Advisor)、切面(Aspect)、AOP代理(AOP Proxy),具体的方法和类型下面文章会举例说明,感兴趣的小伙伴和小编一起阅读全文吧2021-09-09 观察者模式是经典设计模式中很常用的一种,平常我们看到的监听器,基本上都是采用这种设计模式实现的,这里探讨一下观察者模式的演化2014-02-02
观察者模式是经典设计模式中很常用的一种,平常我们看到的监听器,基本上都是采用这种设计模式实现的,这里探讨一下观察者模式的演化2014-02-02 这篇文章主要为大家介绍了手写简版的kedis分布式key及value服务的实现示例,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步2022-02-02
这篇文章主要为大家介绍了手写简版的kedis分布式key及value服务的实现示例,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步2022-02-02 什么是堆污染呢?是指当参数化类型变量引用的对象不是该参数化类型的对象时而发生的。我们知道在JDK5中,引入了泛型的概念,在创建集合类的时候,指定该集合类中应该存储的对象类型。如果在指定类型的集合中,引用了不同的类型,那么这种情况就叫做堆污染。2021-06-06
什么是堆污染呢?是指当参数化类型变量引用的对象不是该参数化类型的对象时而发生的。我们知道在JDK5中,引入了泛型的概念,在创建集合类的时候,指定该集合类中应该存储的对象类型。如果在指定类型的集合中,引用了不同的类型,那么这种情况就叫做堆污染。2021-06-06 本文主要介绍了MyBatis实现简单的数据表分月存储,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-03-03
本文主要介绍了MyBatis实现简单的数据表分月存储,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-03-03 这篇文章主要为大家详细介绍了java实现双人五子棋游戏,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-05-05
这篇文章主要为大家详细介绍了java实现双人五子棋游戏,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-05-05 这篇文章主要介绍了SpringBean依赖和三级缓存的案例讲解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-02-02
这篇文章主要介绍了SpringBean依赖和三级缓存的案例讲解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-02-02 这篇文章主要介绍了使用ObjectMapper实现忽略字段大小写操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-06-06
这篇文章主要介绍了使用ObjectMapper实现忽略字段大小写操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-06-06










最新评论