
SpringBoot+Mybatis-plus+shardingsphere实现分库分表的方案
更新时间:2024年03月05日 12:11:42 作者:烟火缠过客
实现亿级数据量分库分表的项目是一个挑战性很高的任务,下面是一个基于Spring Boot的简单实现方案,感兴趣的朋友一起看看吧
SpringBoot+Mybatis-plus+shardingsphere实现分库分表
介绍
实现亿级数据量分库分表的项目是一个挑战性很高的任务,下面是一个基于Spring Boot的简单实现方案:
- 数据库选择:使用MySQL数据库,因为MySQL在分库分表方面有较成熟的解决方案。
- 分库分表策略:可以采用水平分库分表的策略,根据一定的规则将数据分散存储在不同的数据库和表中,例如可以根据用户ID、订单ID等进行分片。
- 数据分片策略:可以采用基于雪花算法的分布式ID生成器来生成全局唯一的ID,确保数据在不同数据库和表中的唯一性。
- 数据同步:考虑到数据分散存储在不同的数据库和表中,需要实现数据同步机制来保证数据的一致性,可以使用Canal等开源工具来实现MySQL数据的实时同步。
- 连接池优化:在处理大量数据时,连接池的配置尤为重要,可以使用Druid等高性能的连接池来提升数据库连接的效率。
- 缓存机制:考虑使用Redis等缓存工具来缓存热点数据,减轻数据库的压力,提升系统性能。
- 分布式事务:在分库分表的场景下,涉及到跨库事务,可以考虑使用分布式事务框架,如Seata等来保证事务的一致性。
监控与调优:实时监控数据库的性能指标,及时调整分片策略和数据库配置,保证系统的稳定性和性能。
引入依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.3</version>
</dependency>
<!--分库分表-->
<!-- Sharding-JDBC -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.2.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>yaml配置
server:
port: 10086
spring:
shardingsphere:
# 数据源配置
datasource:
# 数据源名称,多数据源以逗号分隔
names: db0,db1
db0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/ds0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: root
db1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/ds1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: root
# 分片规则配置
rules:
sharding:
# 分片算法配置
sharding-algorithms:
database-inline:
# 分片算法类型
type: INLINE
props:
# 分片算法的行表达式(算法自行定义,此处为方便演示效果)
algorithm-expression: db$->{age % 2}
table-inline:
# 分片算法类型
type: INLINE
props:
# 分片算法的行表达式
algorithm-expression: user_$->{age % 3}
tables:
# 逻辑表名称
user:
# 行表达式标识符可以使用 ${...} 或 $->{...},但前者与 Spring 本身的属性文件占位符冲突,因此在 Spring 环境中使用行表达式标识符建议使用 $->{...}
actual-data-nodes: db${0..1}.user_${0..2}
# 分库策略
database-strategy:
standard:
# 分片列名称
sharding-column: age
# 分片算法名称
sharding-algorithm-name: database-inline
# 分表策略
table-strategy:
standard:
# 分片列名称
sharding-column: age
# 分片算法名称
sharding-algorithm-name: table-inline
# 属性配置
props:
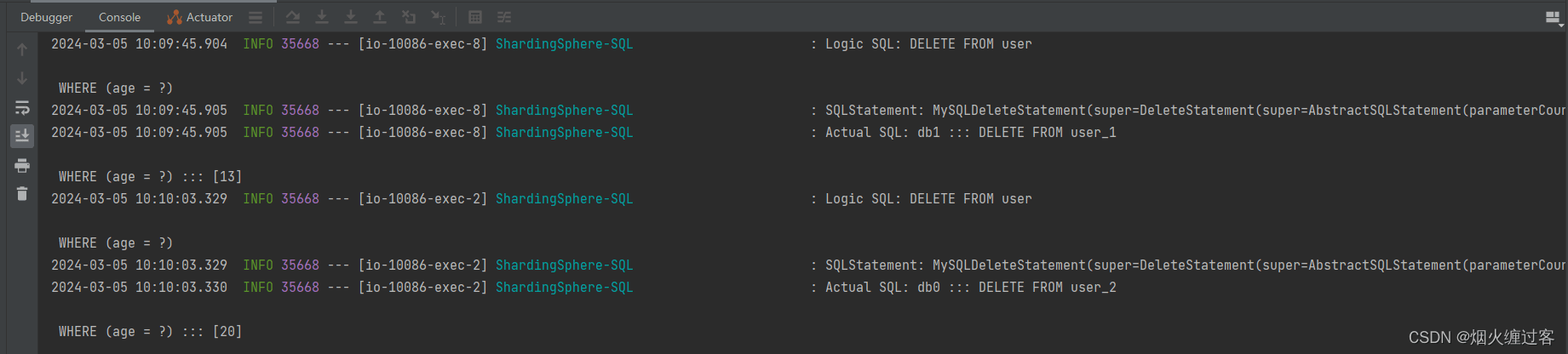
# 展示修改以后的sql语句
sql-show: trueDDL准备
数据库ds0
-- ds0.user_0 definition CREATE TABLE `user_0` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(32) NOT NULL COMMENT '姓名', `age` int NOT NULL COMMENT '年龄', PRIMARY KEY (`id`) ) ENGINE=InnoDB COMMENT='用户表';
-- ds0.user_1 definition CREATE TABLE `user_1` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(32) NOT NULL COMMENT '姓名', `age` int NOT NULL COMMENT '年龄', PRIMARY KEY (`id`) ) ENGINE=InnoDB COMMENT='用户表';
-- ds0.user_2 definition CREATE TABLE `user_2` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(32) NOT NULL COMMENT '姓名', `age` int NOT NULL COMMENT '年龄', PRIMARY KEY (`id`) ) ENGINE=InnoDB COMMENT='用户表';
数据库ds1
-- ds1.user_0 definition CREATE TABLE `user_0` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(32) NOT NULL COMMENT '姓名', `age` int NOT NULL COMMENT '年龄', PRIMARY KEY (`id`) ) ENGINE=InnoDB COMMENT='用户表';
-- ds1.user_1 definition CREATE TABLE `user_1` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(32) NOT NULL COMMENT '姓名', `age` int NOT NULL COMMENT '年龄', PRIMARY KEY (`id`) ) ENGINE=InnoDB COMMENT='用户表';
-- ds1.user_2 definition CREATE TABLE `user_2` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(32) NOT NULL COMMENT '姓名', `age` int NOT NULL COMMENT '年龄', PRIMARY KEY (`id`) ) ENGINE=InnoDB COMMENT='用户表';
entity
package com.kang.sharding.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@Data
@TableName("user")
public class User {
@TableId(value = "id",type = IdType.AUTO)
private Long id;
private String name;
private Integer age;
// getter, setter, toString...
}cotroller
package com.kang.sharding.controller;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.conditions.update.LambdaUpdateWrapper;
import com.kang.sharding.entity.User;
import com.kang.sharding.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
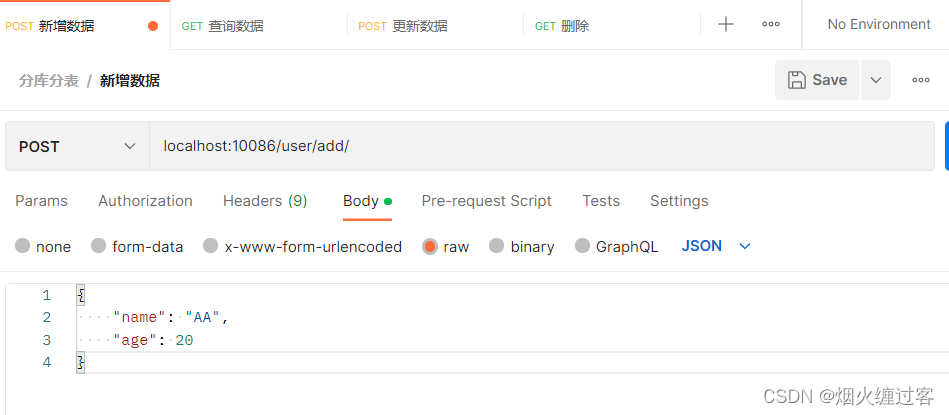
@PostMapping ("add")
public boolean createUser(@RequestBody User user) {
return userService.save(user);
}
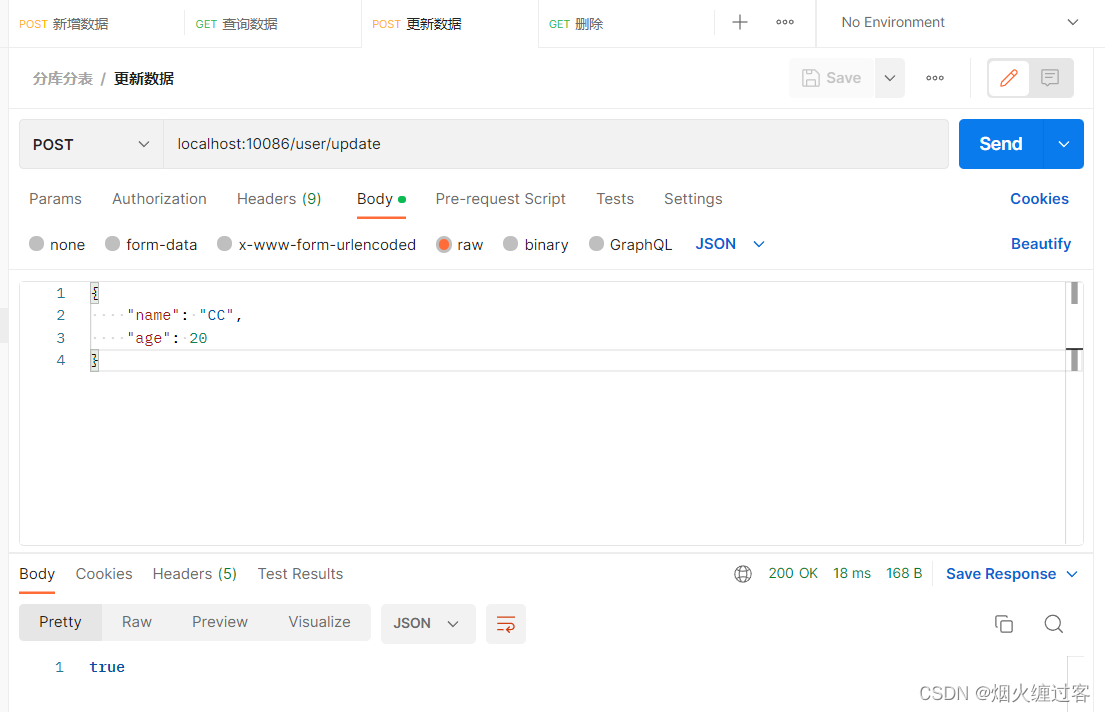
@PostMapping ("update")
public boolean updateByAge(@RequestBody User user){
LambdaUpdateWrapper<User> updateWrapper = new LambdaUpdateWrapper<>();
// 分片数据不允许更新,否则会报错
updateWrapper.eq(User::getAge,user.getAge()).set(User::getName,user.getName());
return userService.update(updateWrapper);
}
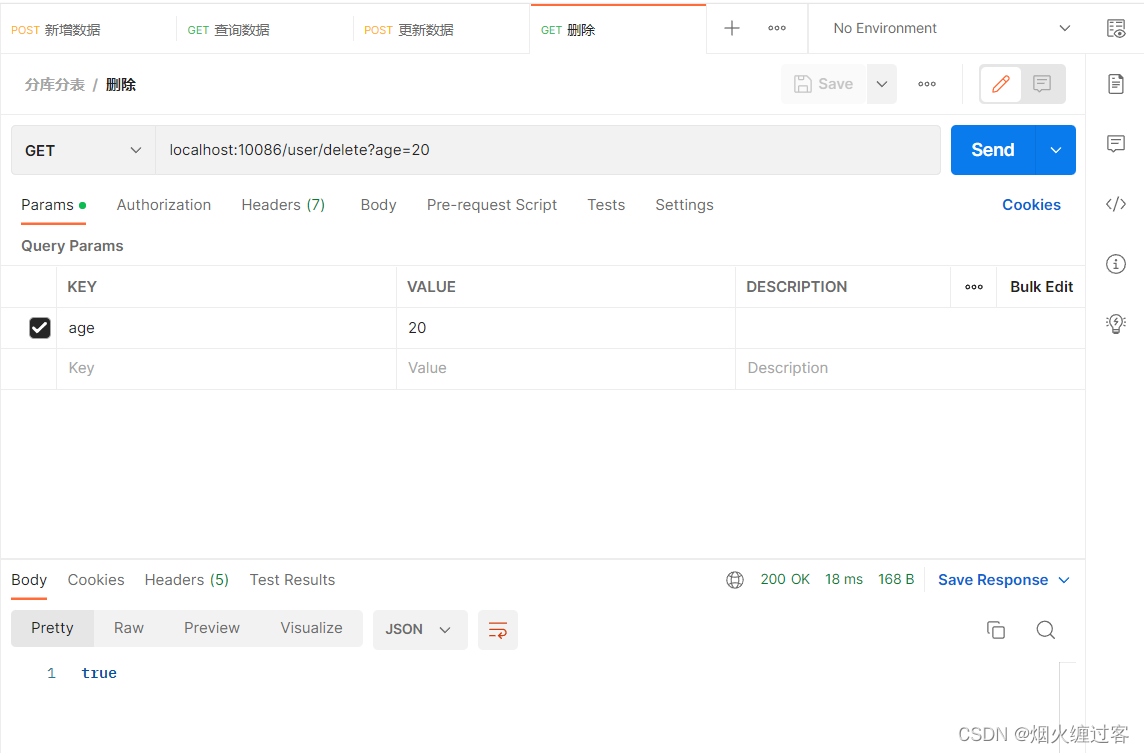
@GetMapping ("delete")
public boolean deleteUserByAge(@RequestParam("age") Integer age) {
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(User::getAge,age);
return userService.remove(queryWrapper);
}
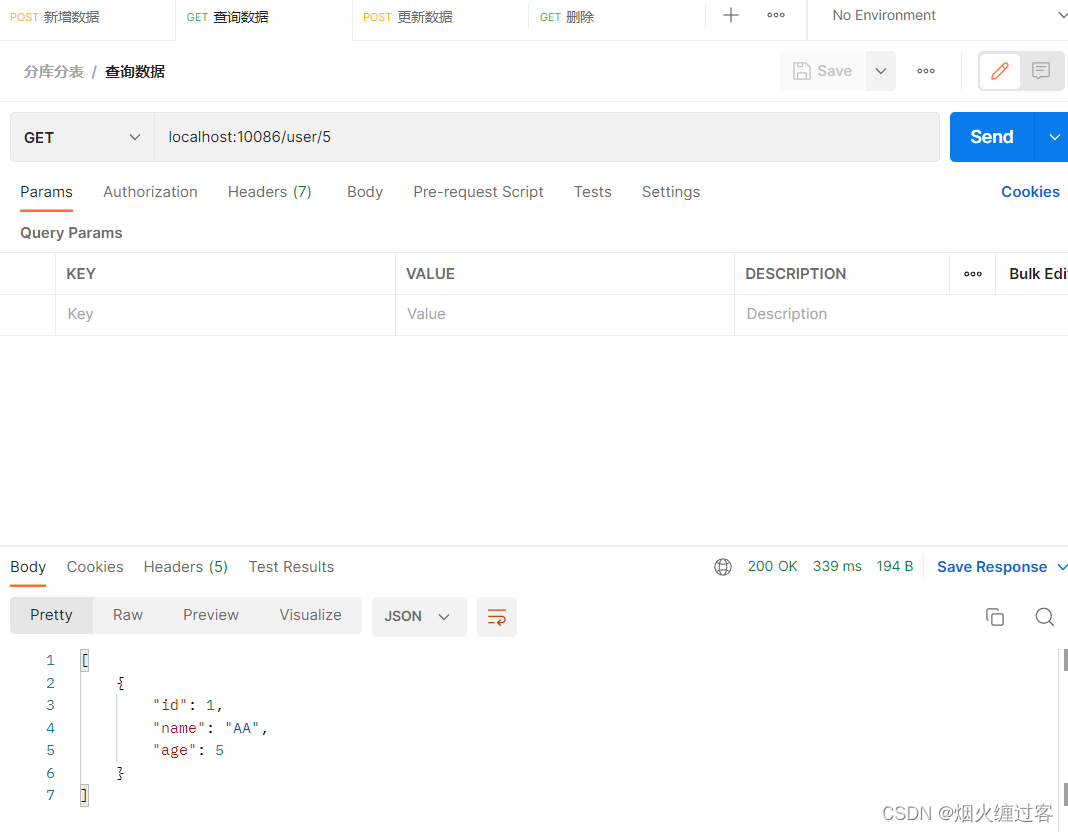
@GetMapping("/{age}")
public List<User> getUserByAge(@PathVariable Integer age) {
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(User::getAge,age);
return userService.list(queryWrapper);
}
// 其他方法...
}service
package com.kang.sharding.service;
import com.kang.sharding.entity.User;
import com.kang.sharding.mapper.UserMapper;
import org.springframework.stereotype.Service;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
@Service
public class UserService extends ServiceImpl<UserMapper, User> {
}Mapper
package com.kang.sharding.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.kang.sharding.entity.User;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface UserMapper extends BaseMapper<User> {
}启动类
package com.kang.sharding;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ShardingJdbcProjectApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingJdbcProjectApplication.class, args);
}
}测试
添加

修改
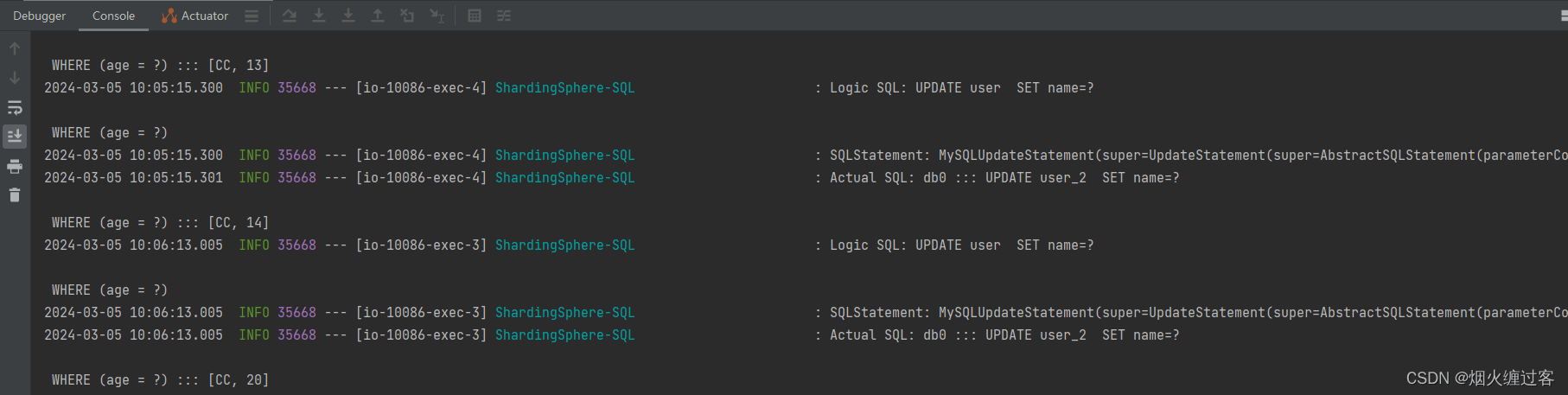
查询

删除
总结
这只是个简单的入门示例,后续深入研究
到此这篇关于SpringBoot+Mybatis-plus+shardingsphere实现分库分表的文章就介绍到这了,更多相关SpringBoot Mybatis-plus shardingsphere分库分表内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 本文主要介绍Java 失效的private修饰符,这里整理了相关资料说明private 修饰符的作用,如何使用并与C++ 做比较,有兴趣的小伙伴可以参考下2016-08-08
本文主要介绍Java 失效的private修饰符,这里整理了相关资料说明private 修饰符的作用,如何使用并与C++ 做比较,有兴趣的小伙伴可以参考下2016-08-08 本文将结合实例代码,介绍SpringBoot中使用Redis对接口进行限流的实现,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-07-07
本文将结合实例代码,介绍SpringBoot中使用Redis对接口进行限流的实现,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-07-07 在SpringBoot项目中简单使用定时任务,不过由于要借助cron表达式且都提前定义好放在配置文件里,不能在项目运行中动态修改任务执行时间,实在不太灵活。现在我们就来实现可以动态修改cron表达式的定时任务,感兴趣的可以了解一下2022-11-11
在SpringBoot项目中简单使用定时任务,不过由于要借助cron表达式且都提前定义好放在配置文件里,不能在项目运行中动态修改任务执行时间,实在不太灵活。现在我们就来实现可以动态修改cron表达式的定时任务,感兴趣的可以了解一下2022-11-11 这篇文章主要介绍了Java 生成带Logo和文字的二维码的方法,帮助大家更好的理解和学习使用Java,感兴趣的朋友可以了解下2021-04-04
这篇文章主要介绍了Java 生成带Logo和文字的二维码的方法,帮助大家更好的理解和学习使用Java,感兴趣的朋友可以了解下2021-04-04
Java高性能新一代构建工具Maven-mvnd(实践可行版)
这篇文章主要介绍了Java高性能新一代构建工具Maven-mvnd(实践可行版),本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2023-06-06 这篇文章主要介绍了Java 实现实体类转Map、Map转实体类的操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-08-08
这篇文章主要介绍了Java 实现实体类转Map、Map转实体类的操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-08-08 这篇文章主要给大家介绍了关于Spring启动流程refresh()源码深入解析的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-09-09
这篇文章主要给大家介绍了关于Spring启动流程refresh()源码深入解析的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-09-09 这篇文章主要介绍了Java线程之死锁,死锁是这样一种情形-多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止2022-05-05
这篇文章主要介绍了Java线程之死锁,死锁是这样一种情形-多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止2022-05-05
Spring Boot系列教程之7步集成RabbitMQ的方法
RabbitMQ 即一个消息队列,主要是用来实现应用程序的异步和解耦,同时也能起到消息缓冲,消息分发的作用。下面这篇文章主要给大家介绍了关于Spring Boot之7步集成RabbitMQ的相关资料,需要的朋友可以参考下2018-11-11 Cherry-Pick可以将一个分支的某些commit,合并到另一个分支,本文给大家分享idea中cherry pick的用法,感兴趣的朋友跟随小编一起看看吧2023-08-08
Cherry-Pick可以将一个分支的某些commit,合并到另一个分支,本文给大家分享idea中cherry pick的用法,感兴趣的朋友跟随小编一起看看吧2023-08-08










最新评论