
Pandas之数据追加df.append方式
更新时间:2023年08月15日 09:49:23 作者:山茶花开时。
这篇文章主要介绍了Pandas之数据追加df.append方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教
Pandas 数据追加df.append
df.append()可以将其他DataFrame附加到调用方的末尾,并返回一个新对象
它是最简单、最常用的数据合并方式
语法
df.append(other, ignore_index=False, verify_integrity=False, sort=False)
参数
other:调用方要追加的其他DataFrame或者类似序列内容。可以放入一个由DataFrame组成的列表,将所有DataFrame追加起来ignore_index:如果为True,则重新进行自然索引verify_integrity:如果为True,则遇到重复索引内容时报错sort:进行排序
1.相同结构
如果数据的字段相同,直接使用第一个DataFrame的append()方法,传入第二个DataFrame。
如果需要追加多个DataFrame,可以将它们组成一个列表再传入
import pandas as pd
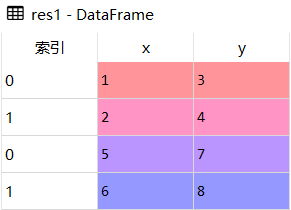
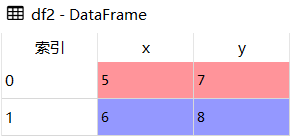
df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
df2 = pd.DataFrame({'x':[5,6],'y':[7,8]})
res1 = df1.append(df2)
# 追加多个数据
res2 = df1.append([df2,df2,df2])结果展示
df1

df2

res1
res2

2.不同结构
对于不同结构的追加,一方有而另一方没有的列会增加,没有内容的位置用NaN填充
import pandas as pd
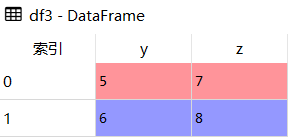
df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
df3 = pd.DataFrame({'y':[5,6],'z':[7,8]})
# 追加合并
res = df1.append(df3)结果展示
df1

df3
res

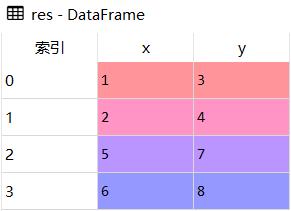
3.忽略索引
追加操作索引默认为原数据的,不会改变,如果需要忽略,可以传入ignore_index = True
import pandas as pd
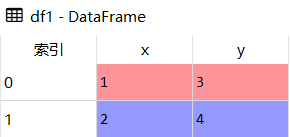
df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
df2 = pd.DataFrame({'x':[5,6],'y':[7,8]})
# 忽略索引
res = df1.append(df2, ignore_index=True)结果展示
df1
df2
res
4.重复内容
重复内容默认是可以追加的,如果传入verify_integrity = True参数和值,则会检测追加内容是否重复,如有重复会报错
import pandas as pd
df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
df2 = pd.DataFrame({'x':[5,6],'y':[7,8]})
# 合并两个相同的内容(报错)
df1.append([df2,df2], verify_integrity=True)结果展示
df1

df2

5.追加序列
append()除了追加DataFrame外,还可以追加一个Series,经常用于数据添加更新场景
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# 定义新同学的信息
lily = pd.Series(['lily','C',55,56,57,58],
index=['name','team','Q1','Q2','Q3','Q4'])
# 追加
df = df.append(lily, ignore_index=True)结果展示
原df
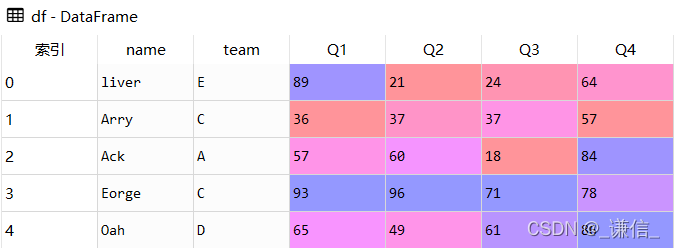
lily
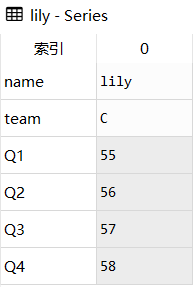
新df

6.追加字典
append()还可以追加字典
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# 将学生信息定义为一个字典
lily = {'name':'lily','team':'C','Q1':55,'Q2':56,'Q3':57,'Q4':58}
df = df.append(lily, ignore_index=True)结果展示
原df

lily

新df
扩展练习案例
import pandas as pd df_list = [] df1 = pd.DataFrame([['A',1]],columns = ['Site','number']) df_list.append(df1) df2 = pd.DataFrame([['B',2]],columns = ['Site','number']) df_list.append(df2) df_all = pd.concat([df1,df2]) df3 = pd.DataFrame([['C',3]],columns = ['Site','number']) df_list.append(df3) df_all = pd.concat(df_list) df_all = df_all.reset_index(drop=True)
df1

df2

df3

df_all

df_list

总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要介绍了python字符串替换re.sub()方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-09-09
这篇文章主要介绍了python字符串替换re.sub()方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-09-09 这篇文章主要介绍了Python入门教程之pycharm安装/基本操作/快捷键,Python是一门非常强大好用的语言,也有着易上手的特性,本文为入门教程,需要的朋友可以参考下2023-04-04
这篇文章主要介绍了Python入门教程之pycharm安装/基本操作/快捷键,Python是一门非常强大好用的语言,也有着易上手的特性,本文为入门教程,需要的朋友可以参考下2023-04-04 今天小编就为大家分享一篇对python抓取需要登录网站数据的方法详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05
今天小编就为大家分享一篇对python抓取需要登录网站数据的方法详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05 OpenCV是一个开源的计算机视觉库,它提供了一系列丰富的图像处理和计算机视觉算法,这篇文章主要给大家介绍了关于Opencv简单图像操作方法的相关资料,需要的朋友可以参考下2024-02-02
OpenCV是一个开源的计算机视觉库,它提供了一系列丰富的图像处理和计算机视觉算法,这篇文章主要给大家介绍了关于Opencv简单图像操作方法的相关资料,需要的朋友可以参考下2024-02-02 今天小编就为大家分享一篇Python之使用adb shell命令启动应用的方法详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01
今天小编就为大家分享一篇Python之使用adb shell命令启动应用的方法详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01 这篇文章主要介绍了Python txt文件如何转换成字典,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-11-11
这篇文章主要介绍了Python txt文件如何转换成字典,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-11-11 这篇文章主要介绍了Python udp网络程序实现发送、接收数据功能,结合实例形式分析了Python使用socket模块进行udp套接字创建、数据收发等相关操作技巧,需要的朋友可以参考下2019-12-12
这篇文章主要介绍了Python udp网络程序实现发送、接收数据功能,结合实例形式分析了Python使用socket模块进行udp套接字创建、数据收发等相关操作技巧,需要的朋友可以参考下2019-12-12 这篇文章主要介绍了78行Python代码实现现微信撤回消息功能,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2018-07-07
这篇文章主要介绍了78行Python代码实现现微信撤回消息功能,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2018-07-07 Python 中函数的应用非常广泛,函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段,这篇文章主要给大家介绍了关于Python函数的定义与调用的相关资料,需要的朋友可以参考下2023-06-06
Python 中函数的应用非常广泛,函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段,这篇文章主要给大家介绍了关于Python函数的定义与调用的相关资料,需要的朋友可以参考下2023-06-06 本文带大家写个小游戏,不过老是用pygame也没啥意思,这次我们换点新花样,用python自带的tkinter包写一个记忆翻牌小游戏,感兴趣的可以了解一下2022-03-03
本文带大家写个小游戏,不过老是用pygame也没啥意思,这次我们换点新花样,用python自带的tkinter包写一个记忆翻牌小游戏,感兴趣的可以了解一下2022-03-03










最新评论