
python使用 multiprocessing 多进程处理批量数据的示例代码
更新时间:2023年09月11日 11:20:04 作者:DexterLien
这篇文章主要介绍了使用 multiprocessing 多进程处理批量数据的示例代码,本文通过示例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
示例代码
import multiprocessing
def process_data(data):
# 这里是处理单个数据的过程
return data * 2
# 待处理的数据
data = [1, 2, 3, 4, 5]
def normal_func():
# 普通处理方式
result = []
for obj in data:
result.append(process_data(obj)
return result
def parallel_func():
# 多进程处理方式
pool = multiprocessing.Pool(multiprocessing.cpu_count())
result = pool.map(process_data, data)
pool.close()
return result
if __name__ == '__main__':
result = normal_func()
result = parallel_func()multiprocessing.Pool 创建进程池, 传入的参数是要要使用的 CPU 内核数量, 直接用 cpu_count() 可以拿到当前硬件配置所有的 CPU 内核数.
pool.map 可以直接将处理后的结果拼接成一个 list 对象
应用在实际数据处理代码的效果对比:
普通处理方式, 用时 221 秒
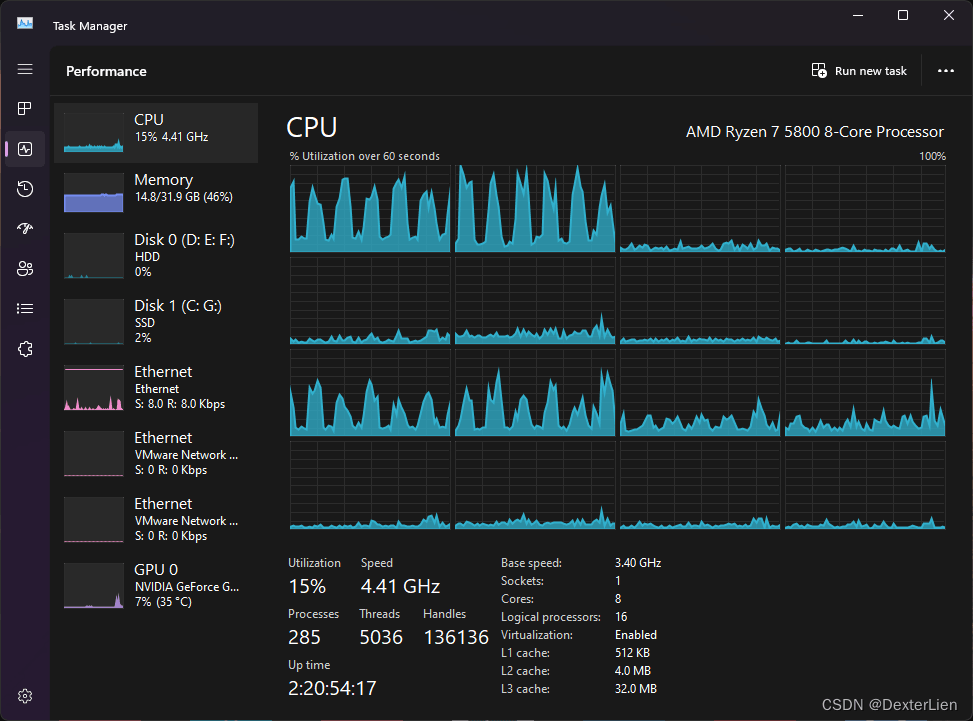
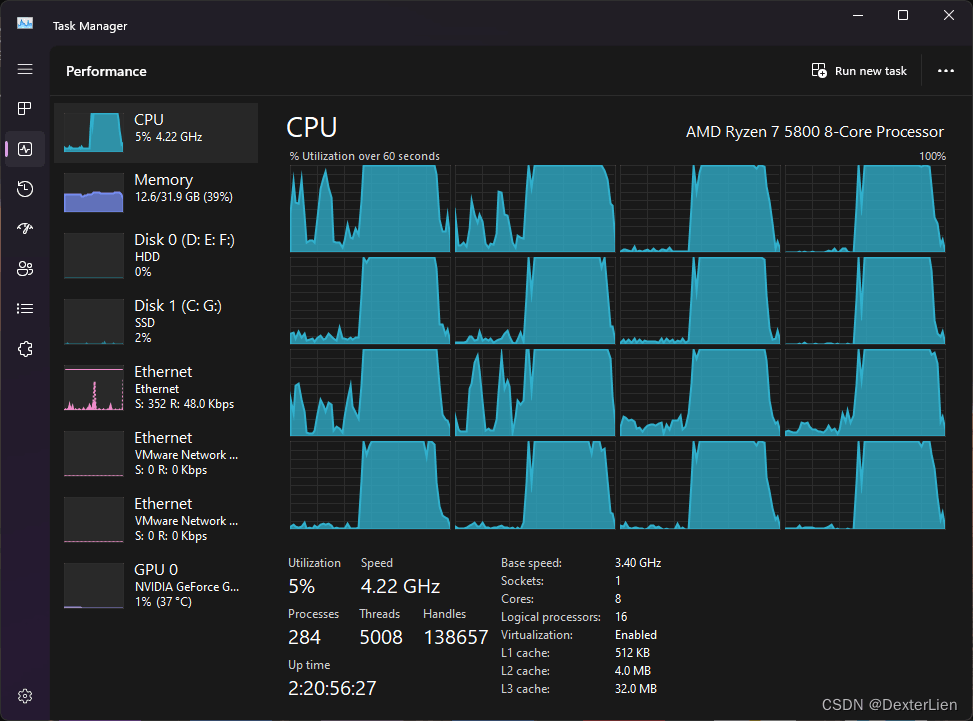
多进程处理方式, 用时 39 秒, 节省了 82% 的时间
到此这篇关于使用 multiprocessing 多进程处理批量数据的文章就介绍到这了,更多相关 multiprocessing 多进程处理批量数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要给大家介绍了关于python修改和新增字典中键值对的2种方法,在Python中字典是一系列键值对,每个键都与一个值相关联,与键相关联的值可以是数、字符串、列表乃至字典,需要的朋友可以参考下2023-07-07
这篇文章主要给大家介绍了关于python修改和新增字典中键值对的2种方法,在Python中字典是一系列键值对,每个键都与一个值相关联,与键相关联的值可以是数、字符串、列表乃至字典,需要的朋友可以参考下2023-07-07 这篇文章主要介绍了python 基于空间相似度的K-means轨迹聚类的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03
这篇文章主要介绍了python 基于空间相似度的K-means轨迹聚类的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03
python中的线程threading.Thread()使用详解
这篇文章主要介绍了python中的线程threading.Thread()使用详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-12-12 这篇文章主要为大家介绍了python深度学习tensorflow入门基础教程示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-06-06
这篇文章主要为大家介绍了python深度学习tensorflow入门基础教程示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-06-06
python程序运行进程、使用时间、剩余时间显示功能的实现代码
这篇文章主要介绍了python程序运行进程、使用时间、剩余时间显示功能,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友参考下吧2019-07-07 分享原创的一段查询通行证办理进度查询的python 3.3代码,利用socket请求相关网站,获得结果后利用正则找出办理进度2013-12-12
分享原创的一段查询通行证办理进度查询的python 3.3代码,利用socket请求相关网站,获得结果后利用正则找出办理进度2013-12-12 这篇文章主要介绍了Python中函数相关的变量作用域,变量的作用域是指程序代码能够访问该变量的区域,如果超出该区域,在访问时就会出现错误,需要的朋友可以参考下2023-08-08
这篇文章主要介绍了Python中函数相关的变量作用域,变量的作用域是指程序代码能够访问该变量的区域,如果超出该区域,在访问时就会出现错误,需要的朋友可以参考下2023-08-08 这篇文章主要介绍了Python实现一个简单的MySQL类,可实现基本的初始化连接及查询、删除等功能,具有一定参考借鉴价值,需要的朋友可以参考下2015-01-01
这篇文章主要介绍了Python实现一个简单的MySQL类,可实现基本的初始化连接及查询、删除等功能,具有一定参考借鉴价值,需要的朋友可以参考下2015-01-01 这篇文章主要介绍了详细介绍Python进度条tqdm的使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-07-07
这篇文章主要介绍了详细介绍Python进度条tqdm的使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-07-07
一篇文章从零开始创建conda环境、常用命令的使用及pycharm配置项目环境
在Conda中创建新环境是一个非常有用的做法,尤其是当你需要为不同的项目安装不同版本的软件包时,这篇文章主要给大家介绍了关于从零开始创建conda环境、常用命令的使用及pycharm配置项目环境的相关资料,需要的朋友可以参考下2024-07-07










最新评论