
Pandas数据分组统计的实现示例
更新时间:2023年11月26日 10:47:30 作者:GarsonW
对数据进行分组统计,主要适用DataFrame对象的groupby()函数,本文就来详细的介绍下Pandas数据分组统计的实现,具有一定的参考价值,感兴趣的可以了解下
1.分组统计groupby()函数
对数据进行分组统计,主要适用DataFrame对象的groupby()函数。其功能如下。
(1)根据特定条件,将数据拆分成组
(2)每个组都可以独立应用函数(如求和函数sum(),均值函数mean()等)
(3)将结果合并到一个数据结构中
示例1:
根据“一级分类”对订单数据进行分组统计求和。
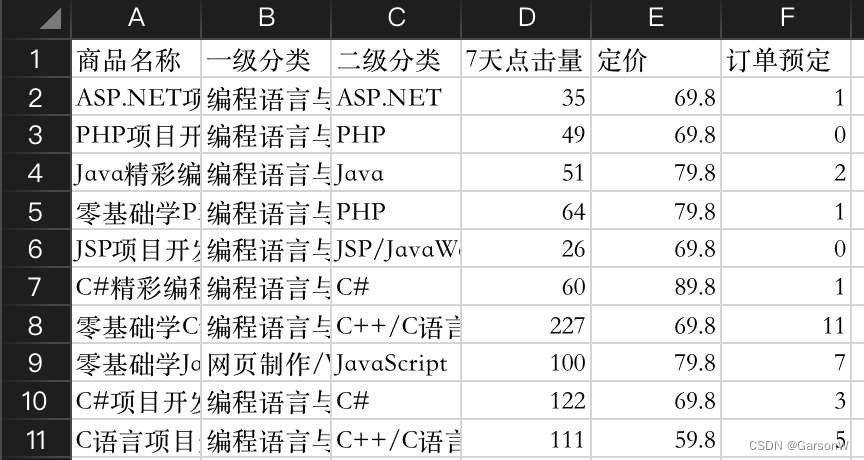
import pandas as pd #导入pandas模块
df=pd.read_csv('JD.csv',encoding='gbk')
#抽取数据
df1=df[['一级分类','7天点击量','订单预定']]
df1=df1.groupby('一级分类').sum() #分组统计求和
示例2:
按照图书“一级分类”和“二级分类”对订单数据进行分组统计求和
import pandas as pd #导入pandas模块
df=pd.read_csv('JD.csv',encoding='gbk')
#抽取数据
df1=df[['一级分类','二级分类','7天点击量','订单预定']]
df2=df1.groupby(['一级分类','二级分类']).sum() #分组统计求和
示例3:
求各二级分类的七天点击量。首先按“二级分类”分类,而后进行分组统计求和。
df1 = df1.groupby('二级分类')['七天点击量'].sum()2.对分组数据进行迭代
示例1:
按照“一级分类”分组,并且输出每一分类中的订单数据
# 抽取数据
df1 = df[['一级分类',‘七天点击量',‘订单预定']]
for name, group in df.groupby('一级分类')
print(name)
print(group)其中name是‘一级分类’, group是其他数据。因此使用groupby()函数对多列进行分组,那么需要在for循环中指定多列。
3.对分组的某列或多列使用聚合函数
Python也可以实现像SQL中的分组聚合运算操作,主要通过groupby()函数与agg()函数实现。
以下代码实现:
1. 以'一级分类'分组,求分组后的平均值与和
2.以'一级分类'分组,求分组后'七天点击量'的平均值与和,求'订单预定'的和
df1.groupby('一级分类').agg(['mean','sum'])
df1.groupby('一级分类').agg({'七天点击量':['mean','sum'],'订单预定':['sum']})我们可以通过自定义函数实现数组分组统计。书本p110
以下代码实现:
1.统计一月份销售数据中,购买次数最多的产品,及其人均购买数,人均花费,总购买数,总花费。
df = pd.read_excel('1月.xlsx')
max1 = lambda x: x.value_counts(dropna=false).index[0]
df1 = df.agg({'宝贝标题':[max1],
'数量':['sum','mean'],
'卖家实际支付金额':['sum','mean']})
print(df1)4.通过字典和Series对象进行分组统计
1.通过字典进行分组统计
创建字典,df.groupby()函数通过字典内信息分组。
import pandas as pd #导入pandas模块
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df=pd.read_csv('JD.csv',encoding='gbk') #导入csv文件
df=df.set_index(['商品名称'])
#创建字典
mapping={'北京出库销量':'北上广','上海出库销量':'北上广',
'广州出库销量':'北上广','成都出库销量':'成都',
'武汉出库销量':'武汉','西安出库销量':'西安'}
df1=df.groupby(mapping,axis=1).sum()
print(df1)
2.通过Series对象进行分组统计
创建一个Series对象,然后将Series对象传给groupby()函数实现数据分组。Series对象内放索引+值:如'北京出库销量',对应值'北上广'。
import pandas as pd #导入pandas模块
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df=pd.read_csv('JD.csv',encoding='gbk') #导入csv文件
df=df.set_index(['商品名称'])
data={'北京出库销量':'北上广','上海出库销量':'北上广',
'广州出库销量':'北上广','成都出库销量':'成都',
'武汉出库销量':'武汉','西安出库销量':'西安',}
s1=pd.Series(data)
print(s1)
df1=df.groupby(s1,axis=1).sum()
print(df1)到此这篇关于Pandas数据分组统计的实现示例的文章就介绍到这了,更多相关Pandas 分组统计内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 今天小编就为大家分享一篇django 中使用DateTime常用的时间查询方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-12-12
今天小编就为大家分享一篇django 中使用DateTime常用的时间查询方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-12-12 这篇文章主要给大家介绍了关于Python中可迭代对象、迭代器和生成器的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用Python具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2019-08-08
这篇文章主要给大家介绍了关于Python中可迭代对象、迭代器和生成器的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用Python具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2019-08-08 在本篇文章里小编给大家整理了关于python3代码输出嵌套式对象实例详解内容,有兴趣的朋友们可以学习下。2020-12-12
在本篇文章里小编给大家整理了关于python3代码输出嵌套式对象实例详解内容,有兴趣的朋友们可以学习下。2020-12-12
Python利用matplotlib模块数据可视化绘制3D图
matplotlib是python最著名的绘图库,它提供了一整套和matlab相似的命令API,十分适合交互式地行制图,下面这篇文章主要给大家介绍了关于Python利用matplotlib模块数据可视化实现3D图的相关资料,需要的朋友可以参考下2022-02-02 这篇文章主要介绍了解决python3输入的坑——input(),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-12-12
这篇文章主要介绍了解决python3输入的坑——input(),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-12-12 这篇文章主要介绍了python实现的jpg格式图片修复代码,本文直接给出实现代码,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了python实现的jpg格式图片修复代码,本文直接给出实现代码,需要的朋友可以参考下2015-04-04 这篇文章主要为大家详细介绍了python查看微信好友是否删除自己,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2016-12-12
这篇文章主要为大家详细介绍了python查看微信好友是否删除自己,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2016-12-12 Python是一种流行的编程语言,可以轻松地通过脚本调用各种应用程序,本文就详细的介绍了python调用可执行文件.exe的2种实现方法,感兴趣的可以了解一下2023-08-08
Python是一种流行的编程语言,可以轻松地通过脚本调用各种应用程序,本文就详细的介绍了python调用可执行文件.exe的2种实现方法,感兴趣的可以了解一下2023-08-08 很多时候,使用python进行数据分析的第一步就是读取excel文件,下面这篇文章主要给大家介绍了关于如何用python获取EXCEL文件内容并保存到DBC的相关资料,需要的朋友可以参考2023-12-12
很多时候,使用python进行数据分析的第一步就是读取excel文件,下面这篇文章主要给大家介绍了关于如何用python获取EXCEL文件内容并保存到DBC的相关资料,需要的朋友可以参考2023-12-12 这篇文章主要为大家详细介绍了python+opencv实现霍夫变换检测直线,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-12-12
这篇文章主要为大家详细介绍了python+opencv实现霍夫变换检测直线,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-12-12










最新评论