
Python的Scrapy框架基本使用详解
更新时间:2023年12月06日 10:10:15 作者:凌冰_
这篇文章主要介绍了Python的Scrapy框架基本使用详解,Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据,Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试,需要的朋友可以参考下
一、Scrapy框架使用
1. 创建scrapy项目
(不能有汉字,不能数字开头)
scrapy startproject Baidu
2. 创建爬虫文件
cd Baidu scrapy genspider wenda www.baidu.com
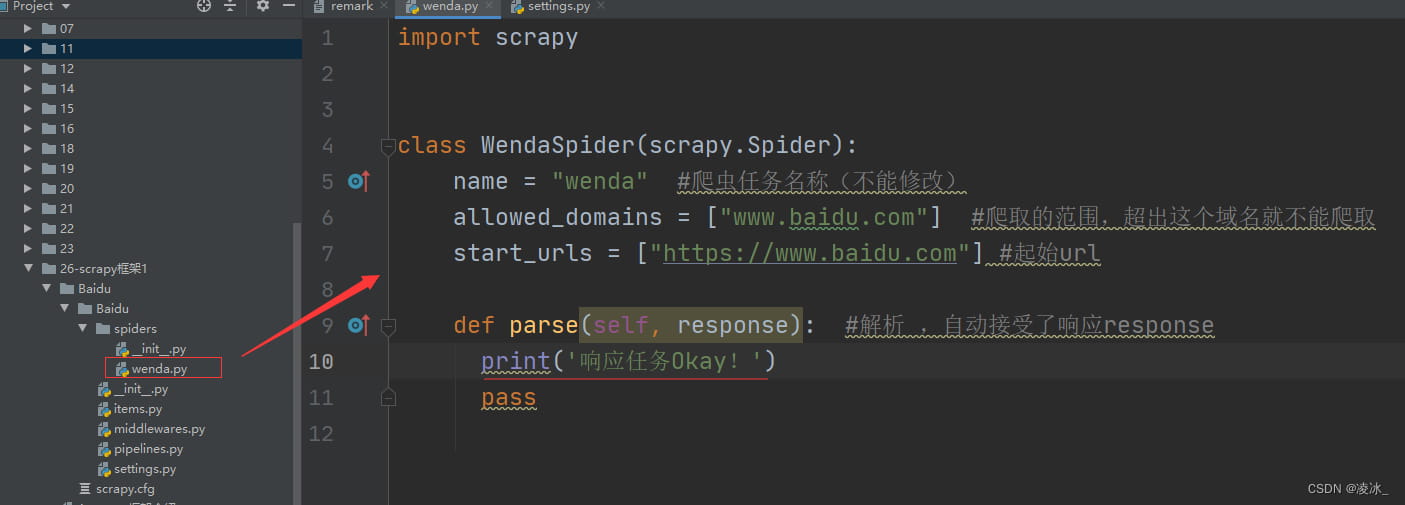
注意: parse()是执行了start_url之后要执行的方法,方法中的response就是返回的对象。相当于response = requests.get或requests.post
3. 运行爬虫代码
scrapy crawl wenda
在parse()函数打印一句话,运行后发现没有打印结果,原因是被一个叫robots.txt的文件给阻止了。
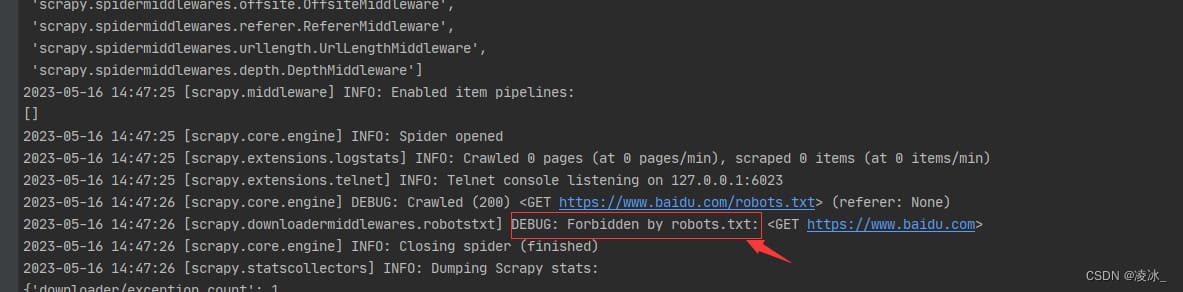
解决:大平台的君子协议,只需在settings里将ROBOTSTXT_OBEY = True注释掉即可。

再次运行
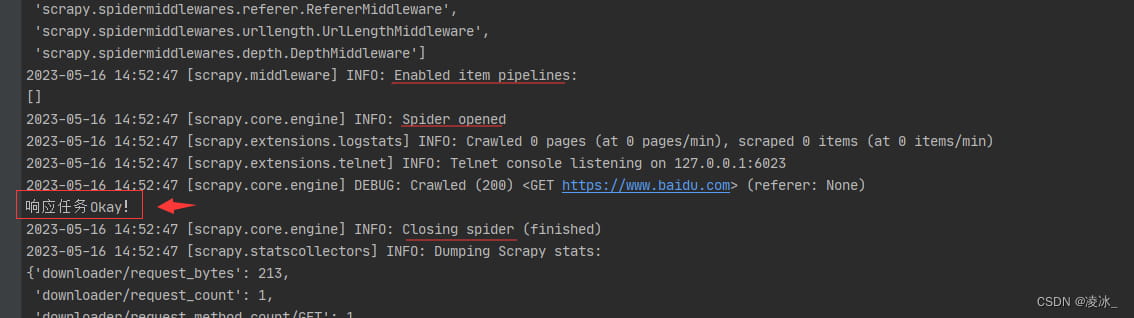
4. scrapy文档
scrapy官网:https://scrapy.org/
scrapy文档:https://doc.scrapy.org/en/latest/intro/tutorial.html
scrapy日志:https://docs.scrapy.org/en/latest/news.html
二、scrapy项目的结构

四、response的属性和方法
- response.text 获取响应的字符串(源码)
- response.body 获取响应的二进制数据(二进制源码)
- response.xpath 直接通过xpath解析response中的内容
- response.extract() 提取selector对象的data所有属性值
- response.extract_first() 提取selector列表的第一个数据
- response.get() : 得到第一条数据
- response.getall() :取出所有的数据,以列表的方式呈现
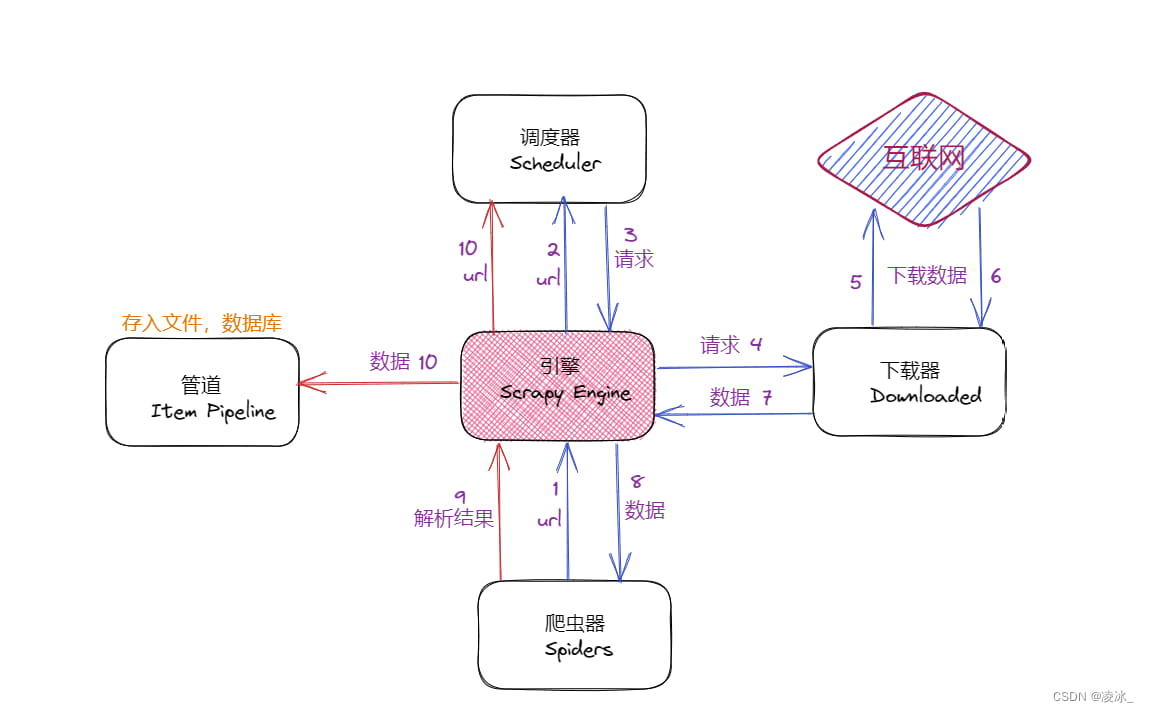
五、scrapy工作原理
- 引擎向spiders要url
- 引擎将要爬取的url给调度器
- 调度器会将url生成请求对象放入到指定的队列中
- 从队列中出队一个请求
- 引擎将请求交给下载器处理
- 下载器发送请求获取互联网数据
- 下载器将数据返回给引擎
- 引擎将数据再次给spiders
- spiders通过xpath解析该数据,得到数据或url
- spiders将数据或url给到引擎
- 引擎判断是数据还是url,若是数据,交给管道处理;若是url,交给调度器处理
到此这篇关于Python的Scrapy框架基本使用详解的文章就介绍到这了,更多相关Python的Scrapy框架内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了python机器学习包mlxtend的安装和配置详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-08-08
这篇文章主要介绍了python机器学习包mlxtend的安装和配置详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-08-08 这篇文章主要介绍了python框架django项目部署相关知识详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-11-11
这篇文章主要介绍了python框架django项目部署相关知识详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-11-11 今天小编就为大家分享一篇python3.6.3转化为win-exe文件发布的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-10-10
今天小编就为大家分享一篇python3.6.3转化为win-exe文件发布的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-10-10 Python3调用cmd复制文件,win7下测试通过,大家参考使用吧2013-12-12
Python3调用cmd复制文件,win7下测试通过,大家参考使用吧2013-12-12 这篇文章主要通过几个简单的示例,为大家详细介绍一下Python实现文件处理的方法,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2023-02-02
这篇文章主要通过几个简单的示例,为大家详细介绍一下Python实现文件处理的方法,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2023-02-02 这篇文章主要为大家详细介绍了python使用tkinter实现屏幕中间倒计时,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-03-03
这篇文章主要为大家详细介绍了python使用tkinter实现屏幕中间倒计时,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-03-03 Django提供一种强大而又直观的方式来"处理"查询中的关联关系,它在后台自动帮你处理JOIN,下面这篇文章主要给大家介绍了关于Django多表查询操作的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2023-06-06
Django提供一种强大而又直观的方式来"处理"查询中的关联关系,它在后台自动帮你处理JOIN,下面这篇文章主要给大家介绍了关于Django多表查询操作的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2023-06-06 这篇文章主要为大家详细介绍了python书籍信息爬虫示例,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-03-03
这篇文章主要为大家详细介绍了python书籍信息爬虫示例,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-03-03
python Elasticsearch索引建立和数据的上传详解
在本篇文章里小编给大家整理的是关于基于python的Elasticsearch索引的建立和数据的上传的知识点内容,需要的朋友们参考下。2019-08-08
python+selenium爬取微博热搜存入Mysql的实现方法
这篇文章主要介绍了python+selenium爬取微博热搜存入Mysql的实现方法,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-01-01










最新评论