
Python爬虫爬取王者荣耀英雄信息并保存到图数据库的操作方法
更新时间:2024年09月28日 13:58:24 作者:叁拾舞
本文介绍了如何使用Python爬虫技术从王者荣耀官方获取英雄信息,并将数据保存到图数据库中,文章详细说明了爬取英雄名称、类型及皮肤名称的过程,并展示了创建英雄类型节点和英雄信息节点的方法
爬取信息说明
- 英雄名称
- 英雄类型
- 英雄包含的所有皮肤名称
创建英雄类型节点
王者荣耀官方给出的英雄类型是以下几种:

直接准备好英雄类型词典
hero_type_dict = [
'战士', '法师', '坦克', '刺客', '射手', '辅助'
]添加到图数据库中
def create_hero_type_node():
for hero_type in hero_type_dict:
cypher = "MERGE (n:HeroType{label: '" + hero_type + "'})"
graph.run(cypher).data()
print('创建英雄类型节点成功')创建英雄信息节点
获取英雄信息
def get_hero_info_list():
# 英雄的全部信息的url
hero_info = 'https://pvp.qq.com/web201605/js/herolist.json'
# 获取英雄的全部信息
response = requests.get(hero_info)
# 转为字典格式
hero_info_dict = json.loads(response.text)
return hero_info_dict打印的内容如下:
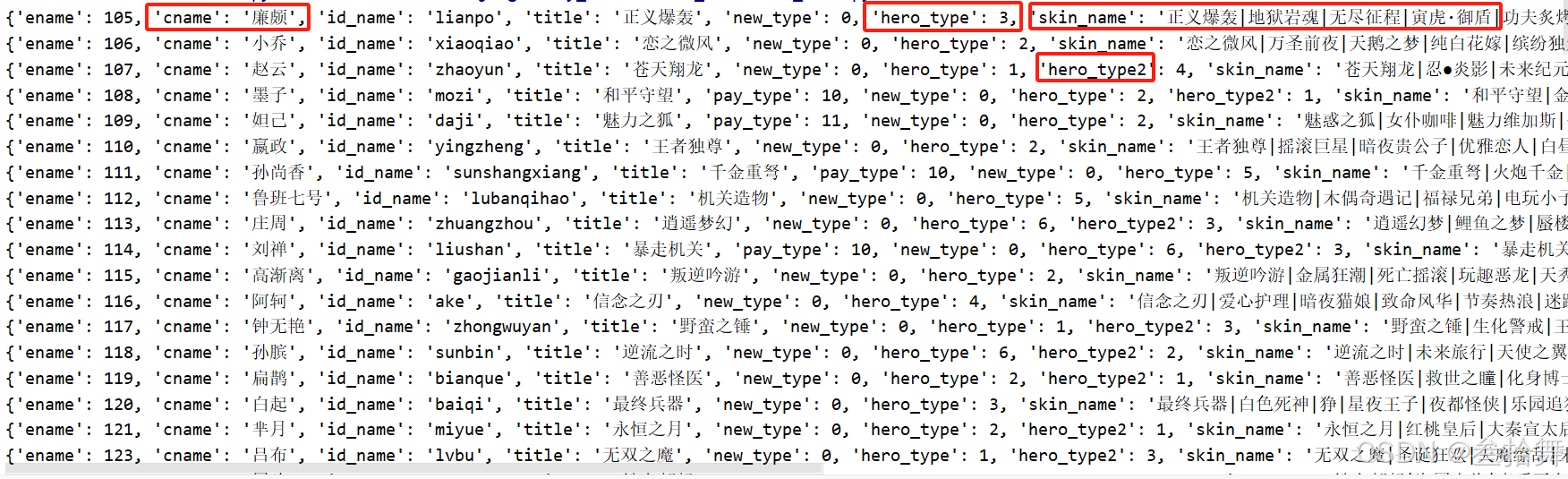
这里需要注意的是,部分英雄包含两个英雄类别。
保存英雄信息
def create_hero_node():
hero_info_dict = get_hero_info_list()
# 1战士 2法师 3坦克 4刺客 5射手 6辅助
for hero in hero_info_dict:
# print(hero)
# print(str(hero.get('cname')) + '===' + str(hero_type[hero.get('hero_type')-1]) + '===' + str(hero.get('skin_name')))
hero_type_list = [str(hero_type_dict[hero.get('hero_type') - 1])]
if '|' in str(hero.get('skin_name')):
skin_name_list = hero.get('skin_name').split('|')
else:
skin_name_list = [hero.get('skin_name')]
if 'hero_type2' in str(hero):
hero_type_list.append(str(hero_type_dict[hero.get('hero_type2') - 1]))
# 创建英雄信息节点
hero_cypher = "MERGE (n:Hero{label: '" + str(hero.get('cname')) + "'})"
graph.run(hero_cypher).data()
# 创建英雄->类型关系
for hero_type in hero_type_list:
cypher_rel = "MATCH(h:Hero{label:'" + str(
hero.get('cname')) + "'}),(t:HeroType{label:'" + hero_type + "'}) MERGE (h)-[r:类型]->(t) RETURN h,r,t"
graph.run(cypher_rel).data()
for skin_name in skin_name_list:
# 创建英雄皮肤节点
cypher = "MERGE (n:Skin{label:'" + skin_name + "'})"
graph.run(cypher).data()
# 创建英雄->皮肤关系
cypher_rel = "MATCH(h:Hero{label:'" + str(
hero.get('cname')) + "'}),(s:Skin{label:'" + skin_name + "'}) MERGE (h)-[r:皮肤]->(s) RETURN h,r,s"
graph.run(cypher_rel).data()
print(str(hero.get('cname')) + '===' + str(hero_type_list) + '===' + str(skin_name_list))完整代码
import json
import requests
from bs4 import BeautifulSoup
from py2neo import Graph, RelationshipMatcher, NodeMatcher
from dict import hero_type_dict
url = "bolt://localhost:7687"
username = "neo4j"
password = 'Suns3535'
graph = Graph(url, auth=(username, password), name="wzry")
node_matcher = NodeMatcher(graph=graph)
relationship_matcher = RelationshipMatcher(graph=graph)
def get_hero_info_list():
# 英雄的全部信息的url
hero_info = 'https://pvp.qq.com/web201605/js/herolist.json'
# 获取英雄的全部信息
response = requests.get(hero_info)
# 转为字典格式
hero_info_dict = json.loads(response.text)
return hero_info_dict
def create_hero_type_node():
for hero_type in hero_type_dict:
cypher = "MERGE (n:HeroType{label: '" + hero_type + "'})"
graph.run(cypher).data()
print('创建英雄类型节点成功')
def create_hero_node():
hero_info_dict = get_hero_info_list()
# 1战士 2法师 3坦克 4刺客 5射手 6辅助
for hero in hero_info_dict:
# print(hero)
# print(str(hero.get('cname')) + '===' + str(hero_type[hero.get('hero_type')-1]) + '===' + str(hero.get('skin_name')))
hero_type_list = [str(hero_type_dict[hero.get('hero_type') - 1])]
if '|' in str(hero.get('skin_name')):
skin_name_list = hero.get('skin_name').split('|')
else:
skin_name_list = [hero.get('skin_name')]
if 'hero_type2' in str(hero):
hero_type_list.append(str(hero_type_dict[hero.get('hero_type2') - 1]))
# 创建英雄信息节点
hero_cypher = "MERGE (n:Hero{label: '" + str(hero.get('cname')) + "'})"
graph.run(hero_cypher).data()
# 创建英雄->类型关系
for hero_type in hero_type_list:
cypher_rel = "MATCH(h:Hero{label:'" + str(
hero.get('cname')) + "'}),(t:HeroType{label:'" + hero_type + "'}) MERGE (h)-[r:类型]->(t) RETURN h,r,t"
graph.run(cypher_rel).data()
for skin_name in skin_name_list:
# 创建英雄皮肤节点
cypher = "MERGE (n:Skin{label:'" + skin_name + "'})"
graph.run(cypher).data()
# 创建英雄->皮肤关系
cypher_rel = "MATCH(h:Hero{label:'" + str(
hero.get('cname')) + "'}),(s:Skin{label:'" + skin_name + "'}) MERGE (h)-[r:皮肤]->(s) RETURN h,r,s"
graph.run(cypher_rel).data()
print(str(hero.get('cname')) + '===' + str(hero_type_list) + '===' + str(skin_name_list))
# 创建英雄类型节点
create_hero_type_node()
# 创建英雄信息
create_hero_node()实现效果
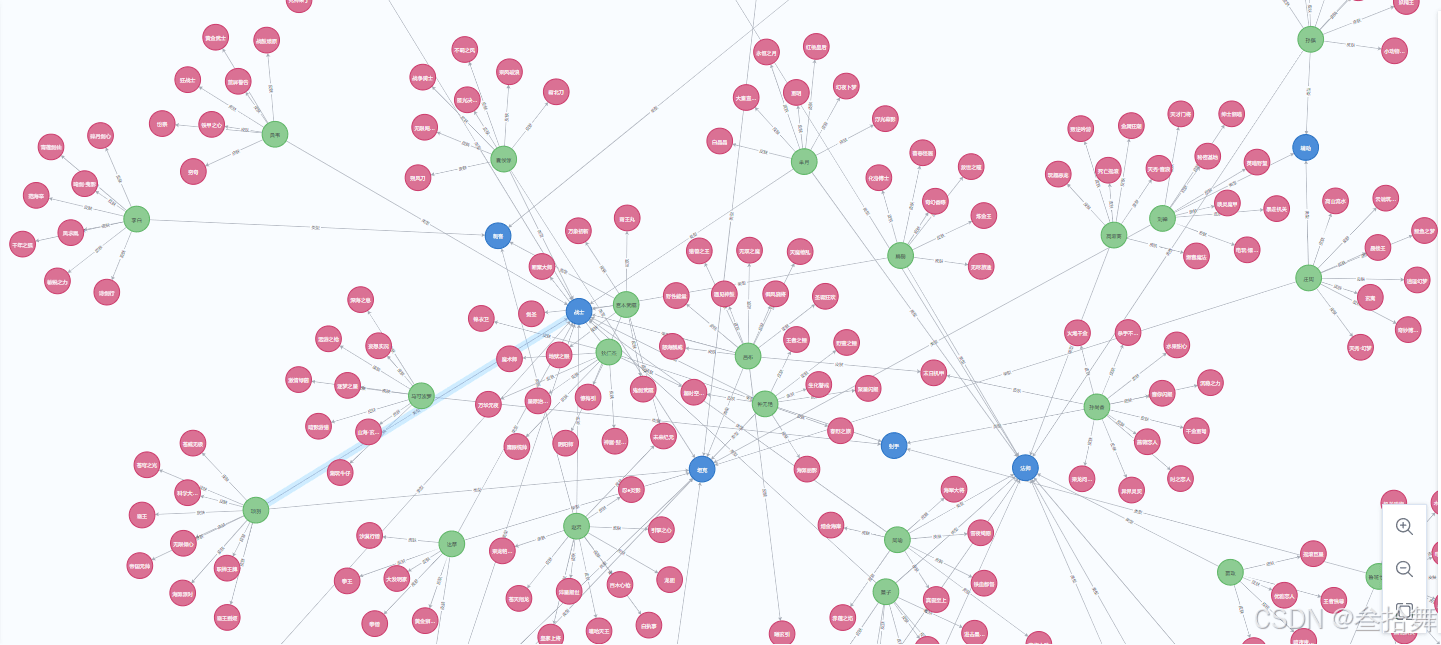
到此这篇关于Python爬虫爬取王者荣耀英雄信息并保存到图数据库的文章就介绍到这了,更多相关Python爬取王者荣耀英雄信息内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

Python 生成器,迭代,yield关键字,send()传参给yield语句操作示例
这篇文章主要介绍了Python 生成器,迭代,yield关键字,send()传参给yield语句操作,结合实例形式分析了Python生成器、迭代、yield关键字及异常处理相关操作技巧,需要的朋友可以参考下2019-10-10 在进行小数计算的时候使用float,经常会出现小数位不精确的情况。在python编程中,推荐使用decimal来完成小数位的精度计算。本文将通过示例详细说说decimal的使用,需要的可以参考一下2022-10-10
在进行小数计算的时候使用float,经常会出现小数位不精确的情况。在python编程中,推荐使用decimal来完成小数位的精度计算。本文将通过示例详细说说decimal的使用,需要的可以参考一下2022-10-10 Python 是每个程序员都喜欢的语言,因为它易于编码和易于阅读的语法。但是,你知道 python 有一些很酷的技巧可以用来让事情变得更简单吗?在今天的内容中,我将与你分享7 个你可能从未使用过的Python 技巧2023-03-03
Python 是每个程序员都喜欢的语言,因为它易于编码和易于阅读的语法。但是,你知道 python 有一些很酷的技巧可以用来让事情变得更简单吗?在今天的内容中,我将与你分享7 个你可能从未使用过的Python 技巧2023-03-03 这篇文章主要为大家详细了如何使用Python来实现PDF文件的密码保护,以确保只有授权的用户可以访问文档,文中的示例代码简洁易懂,有需要的小伙伴可以参考一下2024-01-01
这篇文章主要为大家详细了如何使用Python来实现PDF文件的密码保护,以确保只有授权的用户可以访问文档,文中的示例代码简洁易懂,有需要的小伙伴可以参考一下2024-01-01 本文主要介绍了python使用pyodbc连接sqlserver,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-02-02
本文主要介绍了python使用pyodbc连接sqlserver,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-02-02
AMP Tensor Cores节省内存PyTorch模型详解
这篇文章主要为大家介绍了AMP Tensor Cores节省内存PyTorch模型详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-10-10 二维码作为一种信息传递的工具,在当今社会发挥了重要作用。从手机用户登录到手机支付,生活的各个角落都能看到二维码的存在。下面我们就来看看Python如何生成一个优雅的二维码吧2022-09-09
二维码作为一种信息传递的工具,在当今社会发挥了重要作用。从手机用户登录到手机支付,生活的各个角落都能看到二维码的存在。下面我们就来看看Python如何生成一个优雅的二维码吧2022-09-09![聊聊Numpy.array中[:]和[::]的区别在哪](//img.jbzj.com/images/xgimg/bcimg7.png) 这篇文章主要介绍了在Numpy.array中[:]和[::]的区别说明,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-05-05
这篇文章主要介绍了在Numpy.array中[:]和[::]的区别说明,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-05-05 这篇文章主要介绍了用pandas划分数据集实现训练集和测试集,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-07-07
这篇文章主要介绍了用pandas划分数据集实现训练集和测试集,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-07-07
python输出当前目录下index.html文件路径的方法
这篇文章主要介绍了python输出当前目录下index.html文件路径的方法,涉及Python操作目录的相关技巧,需要的朋友可以参考下2015-04-04







![聊聊Numpy.array中[:]和[::]的区别在哪](http://img.jbzj.com/images/xgimg/bcimg7.png)


最新评论