
Python自动检测requests所获得html文档的编码
更新时间:2024年11月18日 11:12:46 作者:Humbunklung
这篇文章主要为大家详细介绍了如何通过Python自动检测requests实现获得html文档的编码,文中的示例代码讲解详细,感兴趣的可以了解下
使用chardet库自动检测requests所获得html文档的编码
使用requests和BeautifulSoup库获取某个页面带来的乱码问题
使用requests配合BeautifulSoup库,可以轻松地从网页中提取数据。但是,当网页返回的编码格式与Python默认的编码格式不一致时,就会导致乱码问题。
以如下代码为例,它会获取到一段乱码的html:
import requests
from bs4 import BeautifulSoup
# 目标 URL
url = 'https://finance.sina.com.cn/realstock/company/sh600050/nc.shtml'
# 发送 HTTP GET 请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 获取网页内容
html_content = response.text
# 使用 BeautifulSoup 解析 HTML 内容
soup = BeautifulSoup(html_content, 'html.parser')
# 要查找的 ID
target_id = 'hqDetails'
# 查找具有特定 ID 的标签
element = soup.find(id=target_id)
if element:
# 获取该标签下的 HTML 内容
element_html = str(element)
print(f"ID 为 {target_id} 的 HTML 内容:\n{element_html}\n")
# 查找该标签下的所有 table 元素
tables = element.find_all('table')
if tables:
for i, table in enumerate(tables):
print(f"第 {i+1} 个 table 的 HTML 内容:\n{table}\n")
else:
print(f"ID 为 {target_id} 的标签下没有 table 元素")
else:
print(f"未找到 ID 为 {target_id} 的标签")
else:
print(f"请求失败,状态码: {response.status_code}")
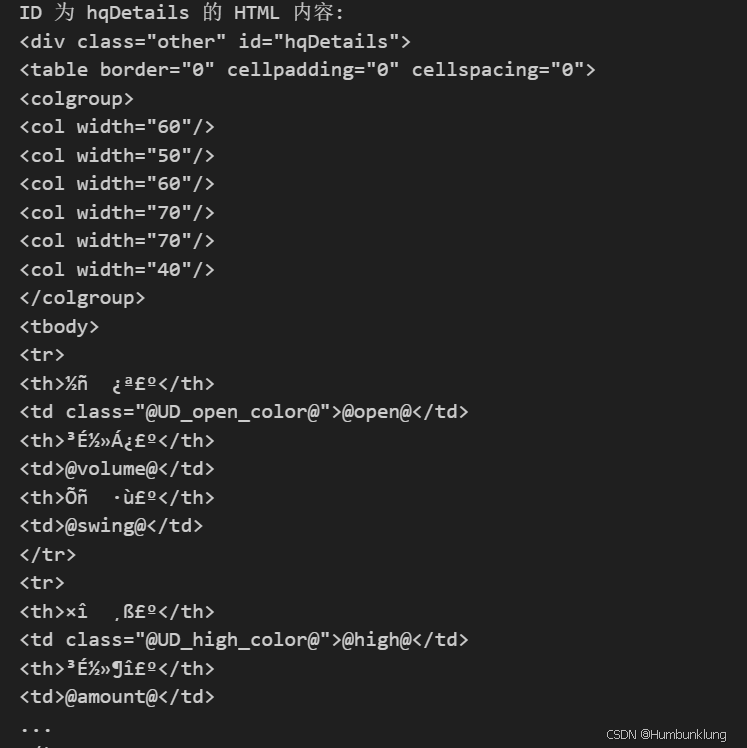
我们可以通过通过手工指定代码的方式来解决这个问题,例如在response.status_code == 200后,通过response.encoding = 'utf-8'指定代码,又或通过soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8') 来指定编码。
然而,当我们获取的html页面编码不确定的时候,有没有更好的办法让编码监测自动执行呢?这时候chardet编码监测库是一个很好的帮手。
使用 chardet 库自动检测编码
chardet 是一个用于自动检测字符编码的库,可以更准确地检测响应的编码。
安装chardet库
pip install chardet
代码应用示例
import requests
from bs4 import BeautifulSoup
import chardet
# 目标 URL
url = 'https://finance.sina.com.cn/realstock/company/sh600050/nc.shtml'
# 发送 HTTP GET 请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 自动检测字符编码
detected_encoding = chardet.detect(response.content)['encoding']
# 设置响应的编码
response.encoding = detected_encoding
# 获取网页内容
html_content = response.text
# 使用 BeautifulSoup 解析 HTML 内容
soup = BeautifulSoup(html_content, 'html.parser')
# 要查找的 ID
target_id = 'hqDetails'
# 查找具有特定 ID 的标签
element = soup.find(id=target_id)
if element:
# 获取该标签下的 HTML 内容
element_html = str(element)
print(f"ID 为 {target_id} 的 HTML 内容:\n{element_html}\n")
# 查找该标签下的所有 table 元素
tables = element.find_all('table')
if tables:
for i, table in enumerate(tables):
print(f"第 {i+1} 个 table 的 HTML 内容:\n{table}\n")
else:
print(f"ID 为 {target_id} 的标签下没有 table 元素")
else:
print(f"未找到 ID 为 {target_id} 的标签")
else:
print(f"请求失败,状态码: {response.status_code}")
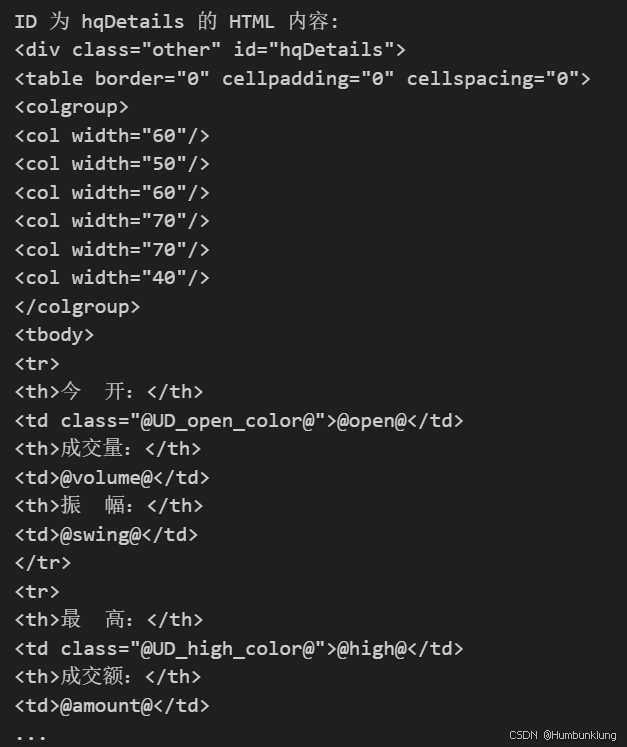
可见,通过使用chardet库,可以有效实现代码的自动检测。
以上就是Python自动检测requests所获得html文档的编码的详细内容,更多关于Python检测requests获得html文档编码的资料请关注脚本之家其它相关文章!
相关文章
 今天小编就为大家分享一篇关于Python神奇的内置函数locals的实例讲解,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2019-02-02
今天小编就为大家分享一篇关于Python神奇的内置函数locals的实例讲解,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2019-02-02 这篇文章主要介绍了Python之列表推导式最全汇总(下篇),本文章内容详细,通过案例可以更好的理解列表推导式的相关知识,本模块分为了三部分,本次为下篇,需要的朋友可以参考下2023-01-01
这篇文章主要介绍了Python之列表推导式最全汇总(下篇),本文章内容详细,通过案例可以更好的理解列表推导式的相关知识,本模块分为了三部分,本次为下篇,需要的朋友可以参考下2023-01-01 用Pycharm写Python代码有一段时间了,最近发现了一个Pycharm的一个小技巧想分享给大家,下面这篇文章主要给大家介绍了关于Pycharm代码跳转该如何回退的相关资料,文中介绍的非常详细,对大家具有一定的参考学习价值,需要的朋友们下面来一起看看吧。2017-07-07
用Pycharm写Python代码有一段时间了,最近发现了一个Pycharm的一个小技巧想分享给大家,下面这篇文章主要给大家介绍了关于Pycharm代码跳转该如何回退的相关资料,文中介绍的非常详细,对大家具有一定的参考学习价值,需要的朋友们下面来一起看看吧。2017-07-07 将视频转换为 GIF 图形的重要性不言而喻,在信息快速传播和多种社交平台广泛应用的背景下,GIF 动画不仅为个人用户提供了一种轻松的表达方式,本文给大家介绍了如何利用python实现把视频转换成gif图形,需要的朋友可以参考下2024-10-10
将视频转换为 GIF 图形的重要性不言而喻,在信息快速传播和多种社交平台广泛应用的背景下,GIF 动画不仅为个人用户提供了一种轻松的表达方式,本文给大家介绍了如何利用python实现把视频转换成gif图形,需要的朋友可以参考下2024-10-10 这篇文章主要为大家详细介绍了Python端口扫描简单程序的实现方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2016-11-11
这篇文章主要为大家详细介绍了Python端口扫描简单程序的实现方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2016-11-11 今天小编就为大家分享一篇使用python 打开文件并做匹配处理的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01
今天小编就为大家分享一篇使用python 打开文件并做匹配处理的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01 当你写好一个python应用以后(有可能是命令行,有可能是GUI),你或许希望分享给他人使用,而别人可能并没有python环境,那么我们需要寻找一种方法生成可执行文件(比如Windows上的exe或macOs上的app)2021-10-10
当你写好一个python应用以后(有可能是命令行,有可能是GUI),你或许希望分享给他人使用,而别人可能并没有python环境,那么我们需要寻找一种方法生成可执行文件(比如Windows上的exe或macOs上的app)2021-10-10 这篇文章主要给大家介绍了关于python中eval与int的区别,文中通过示例代码介绍的非常详细,对大家学习或者使用python具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2019-08-08
这篇文章主要给大家介绍了关于python中eval与int的区别,文中通过示例代码介绍的非常详细,对大家学习或者使用python具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2019-08-08 本篇文章主要介绍了python实现快速排序的示例(二分法思想),小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-03-03
本篇文章主要介绍了python实现快速排序的示例(二分法思想),小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-03-03 这篇文章主要介绍了python如何控制进程或者线程的个数,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-10-10
这篇文章主要介绍了python如何控制进程或者线程的个数,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-10-10










最新评论