
搜索引擎确定重复内容的原理分析
发布时间:2010-02-07 15:48:21 作者:佚名  我要评论
我要评论
现在的互联网鱼龙混杂,信息庞大而繁琐,各类信息充斥着互联网。然而大量的重复信息却不断的上演着,但是这种事情并没法去终止,或者说不可避免。
有严重者,甚至能侵害版权。那么这么庞大的信息,搜索引擎蜘蛛是怎么做到的呢?做网站seo的朋友一定要熟知这方面的知识,只有找对了问题的所在,才能突破收录排名局限!请先看一下图片吧。 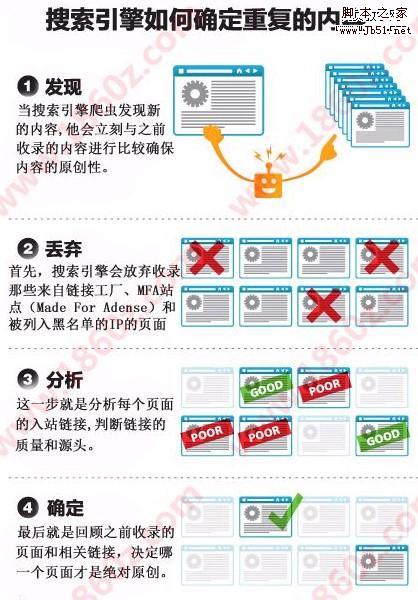

相信大家都能看懂图片的含义吧,比较生动一点,下面简单的给大家表述一下这四个步骤。
1.发现内容:当搜索引擎爬虫发现新内容的时候,他就会理科与之前收录的内容进行比较,确保网站的内容原创性!这一步很关键。如果是伪原创内容的话,请一定保证80%以上的不同!
2.信息丢弃:首先搜索引擎会放弃收录那些来自连接工厂,mfa站点(made for adense)和被列入黑名单的ip页面。
3.链接分析:这一步就是分析每个页面的入站链接,判断链接的质量和源头。这一步也是做导入链接的关键部分,在有限的时间内,做好高质量的链接,保证数量!
4.最后确定:最后就是回顾之前收录的页面和相关链接,决定哪一个页面才是绝对原创。并把原创内容放到排名前面。
总结,这里虽然设计的有的原创,有的伪原创,也有的可能是直接转载。百度蜘蛛和Google机器人默认的排名是最开始的创始地点。最原始的排名越靠前!
相关文章
- 怎么避免网站大量重复URL被百度收录?很多站长发现,自己的网站出现大量的重复收录,这对万展有很大影响,该怎么避免网站中的网页被重复收录呢?请看下文详细介绍2016-01-12
- 一篇文章被三次重复收录,这一现象无论是对于读者还是对于搜索引擎都是不好的,一篇同样文章被收录三次,另外两篇就成了"垃圾"了么?文章为什么被重复收录?本文将提供文章2016-01-06
- 网站内容过度重复该怎么办?最近网站总是出现内容重复度过高的问题,该怎么办呢?网站出现的收录可能会是加后缀的网页,最好给url加上后缀,下面我们以虎嗅网为例,给大家2015-12-18
- 很多人都不知道关键词重复和关键词广度有什么区别?关键词重复是指相同的关键词在大量不同的页面中出现,而关键词广度是指在一个页面中布局大量不同的关键词,下面我们来看2014-12-02
- 朋友圈里有很多代购的,综合看一下代购什么的最多?当然是面膜,为什么这么多产品偏偏选择面膜呢?这也是营销中产品选择的厉害之处,面膜消耗快且能重复消费,需要的朋友可2014-10-10
- 做网站SEO优化的站长朋友应该都比较忌讳自己网站中存在与其他同行网站相同的信息,这也是我们做SEO 工作时应该尽量避免出现的情况2014-04-15
怎么解决wordpress分页title标题重复不利于SEO的问题
在使用谷歌管理员工具时发现wordpress博客列表文章分页重复56页,肯定是对SEO十分不利,那怎么解决这个问题呢?下文给出的解决办法供大家参考2014-01-12- 网站内容重复,是百度K站的一个主要原因,但是也有一些人并不知道什么情况才算网站内容重复,也不知道如何解决网站内容重复的问题。笔者认为网站内容重复不单单是指网站本2013-07-23
- 这次取消的行政审批项目主要分5种情况:一是属于重复审批的项目。经营性互联网信息服务许可和非经营性互联网信息服务备案”已包含了互联网电子公告服务专项审批(备案)。2010-07-17
- 信息是不断涌来的水,互联网承载着信息之水日夜流淌。而网站编辑就是将这些信息内容根据我们站的定位一条一条的,一天一天的呈现在我们的网站上。2010-02-01
最新评论