
深入分析美团的Ursa分布式存储系统
1.Ursa
云硬盘对IaaS云计算平台有至关重要的作用,几乎已成为必备组件,如亚马逊的EBS(Elastic Block Store)、阿里云的盘古、OpenStack中的Cinder等。云硬盘可为云计算平台带来许多优良特性,如更高的数据可靠性和可用性、灵活的数据快照功能、更好的虚拟机动态迁移支持、更短的主机故障恢复时间等等。随着万兆以太网逐渐普及,云硬盘的各项优势得到加强和凸显,其必要性变得十分强烈。
云硬盘的底层通常是分布式块存储系统,目前开源领域有一些此类项目,如Ceph RBD、Sheepdog。另外MooseFS和GlusterFS虽然叫做文件系统,但由于其特性与块存储系统接近,也能用于支持云硬盘。我们在测评中发现,这些开源项目均存在一些问题,使得它们都难以直接应用在大规模的生产系统当中。例如Ceph RBD的效率较低(CPU使用过高);Sheepdog在压力测试中出现了数据丢失的现象;MooseFS的POSIX语义支持、基于FUSE的架构、不完全开源的2.0版本等问题给它自身带来了许多的局限性;GlusterFS与Ceph同属红帽收购的开源存储系统,主要用于scale-out文件存储场景,在云计算领域使用不多。此外,这些存储系统都难以充发挥用万兆网卡和SSD的性能潜力,难以在未来承担重任。
由于以上原因,美团云研发了全新的分布式块存储系统Ursa,通过简单稳固的系统架构、高效的代码实现以及对各种非典型场景的仔细考虑,实现了高可靠、高可用、高性能、低开销、可扩展、易运维、易维护等等目标。Ursa的名字源于DotA中的熊战士,他具有极高的攻击速度、攻击力和生命值,分别隐喻存储系统中的IOPS、吞吐率和稳定性。
分布式块存储相关项目与技术
2.1 Ceph
(主要参考:https://www.ustack.com/blog/ceph_infra/)
Ceph项目起源于其创始人Sage Weil在加州大学Santa Cruz分校攻读博士期间的研究课题。项目的起始时间为2004年。在2006年的OSDI学术会议上,Sage发表了关于Ceph的论文,并提供了项目的下载链接,由此开始广为人知。2010年Ceph客户端部分代码正式进入Linux kernel 2.6.34。
Ceph同时提供对象、块和文件这三个层次的分布式存储服务,其中只有块层存储与我们相关。由于块存储在IaaS云计算系统中占有重要地位,Ceph在近些年的关注度得到显著提高。许多云计算系统实例基于Ceph提供块存储服务,如UnitedStack、Mirantis OpenStack等。
Ceph性能测试
测试版本:0.81
操作系统:CentOS 6.x
测试工具:fio
服务器配置:
CPU: Intel Xeon E5-2650v2 @ 2.6GHz
RAM: 96GB
NIC: 10 GbE
HDD: 6 NL SAS, 7200 RPM
RAID Controller: Dell H710p (LSI 2208 with 1GB NVRAM)
服务器数量:4,其中一个为兼职客户端
注意:由于客户端位于一个存储服务器上,所以有1/4的吞吐率不经过网卡。
测试结果如下:
读IOPS:16 407(此时客户端CPU占用率超过500%,5台服务器CPU总使用率接近500%)
写IOPS:941
顺序读吞吐率:218 859 KB/s
顺序写吞吐率:67 242 KB/s
顺序读延迟:1.6ms (664 IOPS)
顺序写延迟:4.4ms (225 IOPS)
网络ping值:0.1324ms
本地硬盘顺序读写延迟:0.03332ms (29 126 IOPS)
从测试来看,Ceph的读吞吐率正常,然而写吞吐率不足读的1/3,性能偏低;读写延迟比显著大于网络延迟与磁盘I/O延迟之和;CPU占用率过高。
2.2 Sheepdog
(主要参考:http://peterylh.blog.163.com/blog/static/12033201221594937257/)
Sheepdog是由日本NTT实验室的Morita Kazutaka专为虚拟化平台创立的分布式块存储开源项目, 于2009年开源[1]。从2011年9月开始, 一些淘宝的工程师加入了Sheepdog项目,以及相关开源项目比如Corosync、Accord的开发。Sheepdog主要由两部分组成:集群管理和存储服务,其中集群管理目前使用Corosync或者Zookper来完成,存储服务是全新实现的。
Sheepdog采用无中心节点的全对称架构,基于一致性哈希实现从ObjectID到存储节点的定位:每个节点划分成多个虚拟节点,虚拟节点和ObjectID一样,采用64位整数唯一标识,每个虚拟节点负责一段包含节点ID在内的ObjectID区间。DataObject副本存在ObjectID对应的虚拟节点,及在后续的几个节点上。Sheepdog无单点故障问题,存储容量和性能均可线性扩展,新增节点通过简单配置即可加入集群,并且Sheepdog自动实现负载均衡,节点故障时可自动发现并进行副本修复,还直接支持QEMU/KVM。
Sheepdog的服务进程既承担数据服务的职责,同时也是客户端(QEMU)访问数据的gateway。QEMU的Sheepdog driver将对volume的请求转换成为对object的请求,然后通过UNIX domain socket或者TCP socket连接一个Sheepdog服务进程,并将访问请求发给该进程来完成后续步骤。Sheepdog的服务进程还可以开启数据缓存功能,以减少网络I/O。Sheepdog的I/O路径是“client<->gateway<->object manager(s)”,读操作可以在任意副本完成,更新操作并行的发往所有副本, 当所有副本都更新成功之后,gateway才告诉客户端更新操作成功。
Sheepdog的数据可靠性问题
我们对Sheepdog开展了可靠性、可用性测试。在测试中有共3台服务器,每台配有6个机械硬盘,配置好Sheepdog之后,每台服务器启动10个VM,每个VM内无限循环运行fio分别执行小块随机读、写和大块顺序读、写的测试。
在执行压力测试一周后,对集群中的全部数据进行一致性检测(collie cluster check),发现有些数据块副本与另外2个不一致(“fixed replica ...”),有些数据块的3个各不相同(“no majority of ...”):
[root@node3-10gtest ~]# collie cluster check
fix vdi test1-3
99.9 % [=================================================================>] 50 GB / 50 GB
fixed replica 3e563000000fca
99.9 % [=================================================================>] 50 GB / 50 GB
fixed replica 3e563000000fec
100.0 % [================================================================>] 50 GB / 50 GB
fixed replica 3e5630000026f5
100.0 % [================================================================>] 50 GB / 50 GB
fixed replica 3e563000002da6
100.0 % [================================================================>] 50 GB / 50 GB
fixed replica 3e563000001e8c
100.0 % [================================================================>] 50 GB / 50 GB
fixed replica 3e563000001530
...
fix vdi test2-9
50.9 % [=================================> ] 25 GB / 50 GB
no majority of d781e300000123
51.0 % [===================================> ] 26 GB / 50 GB
no majority of d781e300000159
51.2 % [===================================> ] 26 GB / 50 GB
no majority of d781e30000018a
53.2 % [====================================> ] 27 GB / 50 GB
…
2.3 MooseFS
(主要参考:http://peterylh.blog.163.com/blog/static/12033201251791139592/)
MooseFS是容错的分布式文件系统,通过FUSE支持标准POSIX文件系统接口。 MooseFS的架构类似于GFS,由四个部分组成:
管理服务器Master:类似于GFS的Master,主要有两个功能:(1)存储文件和目录元数据,文件元数据包括文件大小、属性、对应的Chunk等;(2)管理集群成员关系和Chunk元数据信息,包括Chunk存储、版本、Lease等。
元数据备份服务器Metalogger Server:根据元数据文件和log实时备份Master元数据。
存储服务器Chunk Server:负责存储Chunk,提供Chunk读写能力。Chunk文件默认为64MB大小。
客户端Client:以FUSE方式挂到本地文件系统,实现标准文件系统接口。
MooseFS本地不会缓存Chunk信息, 每次读写操作都会访问Master, Master的压力较大。此外MooseFS写操作流程较长且开销较高。MooseFS支持快照,但是以整个Chunk为单位进行CoW(Copy-on-Write),可能造成响应时间恶化,补救办法是以牺牲系统规模为代价,降低Chunk大小。
MooseFS基于FUSE提供POSIX语义支持,已有应用可以不经修改直接迁移到MooseFS之上,这给应用带来极大的便利。然而FUSE也带来了一些负面作用,比如POSIX语义对于块存储来说并不需要,FUSE会带来额外开销等等。
2.4 GFS/HDFS
(主要参考:http://www.nosqlnotes.net/archives/119)
HDFS基本可以认为是GFS的一个简化开源实现,二者因此有很多相似之处。首先,GFS和HDFS都采用单一主控机+多台工作机的模式,由一台主控机(Master)存储系统全部元数据,并实现数据的分布、复制、备份决策,主控机还实现了元数据的checkpoint和操作日志记录及回放功能。工作机存储数据,并根据主控机的指令进行数据存储、数据迁移和数据计算等。其次,GFS和HDFS都通过数据分块和复制(多副本,一般是3)来提供更高的可靠性和更高的性能。当其中一个副本不可用时,系统都提供副本自动复制功能。同时,针对数据读多于写的特点,读服务被分配到多个副本所在机器,提供了系统的整体性能。最后,GFS和HDFS都提供了一个树结构的文件系统,实现了类似与Linux下的文件复制、改名、移动、创建、删除操作以及简单的权限管理等。
然而,GFS和HDFS在关键点的设计上差异很大,HDFS为了规避GFS的复杂度进行了很多简化。例如HDFS不支持并发追加和集群快照,早期HDFS的NameNode(即Master)没原生HA功能。总之,HDFS基本可以认为是GFS的简化版,由于时间及应用场景等各方面的原因对GFS的功能做了一定的简化,大大降低了复杂度。
2.5 HLFS
(主要参考:http://peterylh.blog.163.com/blog/static/120332012226104116710/)
HLFS(HDFS Log-structured File System)是一个开源分布式块存储系统,其最大特色是结合了LFS和HDFS。HDFS提供了可靠、随时可扩展的文件服务,而HLFS通过Log-structured技术弥补了HDFS不能随机更新的缺憾。在HLFS中,虚拟磁盘对应一个文件, 文件长度能够超过TB级别,客户端支持Linux和Xen,其中Linux基于NBD实现,Xen基于blktap2实现,客户端通过类POSIX接口libHLFS与服务端通讯。HLFS主要特性包括多副本、动态扩容、故障透明处理和快照。
HLFS性能较低。首先,非原地更新必然导致数据块在物理上非连续存放,因此读I/O比较随机,顺序读性能下降。其次,虽然从单个文件角度看来,写I/O是顺序的,但是在HDFS的Chunk Server服务了多个HLFS文件,因此从它的角度来看,I/O仍然是随机的。第三,写延迟问题,HDFS面向大文件设计,小文件写延时不够优化。第四,垃圾回收的影响,垃圾回收需要读取和写入大量数据,对正常写操作造成较大影响。此外,按照目前实现,相同段上的垃圾回收和读写请求不能并发,垃圾回收算法对正常操作的干扰较大。
2.6 iSCSI、FCoE、AoE、NBD
iSCSI、FCoE、AoE、NBD等都是用来支持通过网络访问块设备的协议,它们都采用C/S架构,无法直接支持分布式块存储系统。
3.Ursa的设计与实现
分布式块存储系统给虚拟机提供的是虚拟硬盘服务,因而有如下设计目标:
大文件存储:虚拟硬盘实际通常GB级别以上,小于1GB是罕见情况
需要支持随机读写访问,不需支持追加写,需要支持resize
通常情况下,文件由一个进程独占读写访问;数据块可被共享只读访问
高可靠,高可用:任意两个服务器同时出现故障不影响数据的可靠性和可用性
能发挥出新型硬件的性能优势,如万兆网络、SSD
由于应用需求未知,同时需要优化吞吐率和IOPS
高效率:降低资源消耗,就降低了成本
除了上述源于虚拟硬盘的直接需求意外,分布式块存储还需要支持下列功能:
快照:可给一个文件在不同时刻建立多个独立的快照
克隆:可将一个文件或快照在逻辑上复制成独立的多份
精简配置(thin-provisioning):只有存储数据的部分才真正占用空间
3.1 系统架构
分布式存储系统总体架构可以分为有master(元数据服务器)和无master两大类。有master架构在技术上较为简单清晰,但存在单点失效以及潜在的性能瓶颈问题;无master架构可以消除单点失效和性能瓶颈问题,然而在技术上却较为复杂,并且在数据布局方面具有较多局限性。块存储系统对master的压力不大,同时master的单点故障问题可采用一些现有成熟技术解决,因而美团EBS的总体架构使用有master的类型。这一架构与GFS、HDFS、MooseFS等系统的架构属于同一类型。
如图1所示,美团EBS系统包括M、S和C三个部分,分别代表Master、Chunk Server和Client。Master中记录的元数据包括3种:(1)关于volume的信息,如类型、大小、创建时间、包含哪些数据chunk等等;(2)关于chunk的信息,如大小、创建时间、所在位置等;(3)关于Chunk Server的信息,如IP地址、端口、数据存储量、I/O负载、空间剩余量等。这3种信息当中,关于volume的信息是持久化保存的,其余两种均为暂存信息,通过Chunk Server上报。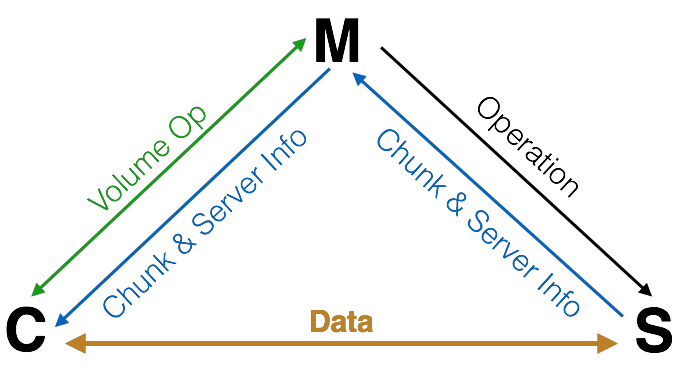
在元数据中,关于volume的信息非常重要,必须持久化保存;关于chunk的信息和Chunk Server的信息是时变的,并且是由Chunk Server上报的,因而没必要持久化保存。根据这样的分析,我们将关于volume的信息保存在MySQL当中,其他元数据保存在Redis当中,余下的集群管理功能由Manager完成。Master == Manager + MySQL + Redis,其中MySQL使用双机主从配置,Redis使用官方提供的标准cluster功能。
3.2 CAP取舍
C、A、P分别代表Consistency、Availability和Partition-tolerance。分布式系统很难同时在这三个方面做到很高的保障,通常要在仔细分析应用需求的基础之上对CAP做出取舍。
块存储系统主要用于提供云硬盘服务,每块云硬盘通常只会挂载到1台VM之上,不存在多机器并发读写的情况,因而其典型应用场景对一致性的需求较低。针对这一特性,我们可以在设计上舍C而取AP。
对于多机并行访问云硬盘的使用模式,若数据是只读的则无需额外处理;若数据有写有读,甚至是多写多读,则需要在上层引入分布式锁,来确保数据一致性和完整性。这种使用模式在SAN领域并不少见,其典型应用场景是多机同时挂载一个网络硬盘,并通过集群文件系统(而不是常见的单机文件系统)来协调访问存储空间。集群文件系统内部会使用分布式锁来确保数据操作的正确性,所以我们舍C的设计决策不会影响多机并行访问的使用模式。
3.3 并发模型
并发(不是并行!)模型的选择和设计无法作为实现细节隐藏在局部,它会影响到程序代码的各个部分,从底层到上层。基本的并发模型只有这样几种:事件驱动、多线程、多进程以及较为小众的多协程。
事件驱动模型是一种更接近硬件工作模式的并发模型,具有更高的执行效率,是高性能网络服务的普遍选择。为能充分发挥万兆网络和SSD的性能潜力,我们必须利用多核心并行服务,因而需要选用多线程或者多进程模型。由于多进程模型更加简单,进程天然是故障传播的屏障,这两方面都十分有利于提高软件的健壮性;并且我们也很容易对业务进行横向拆分,做到互相没有依赖,也不需要交互,所以我们选择了多进程模型,与事件驱动一起构成混合模型。
协程在现实中的应用并不多,很多语言/开发生态甚至不支持协程,然而协程在一些特定领域其实具有更好的适用性。比如,QEMU/KVM在磁盘I/O方面的并发执行完全是由协程负责的,即便某些block driver只提供了事件驱动的接口(如Ceph RBD),QEMU/KVM也会自动把它们转化封装成多协程模式。实践表明,在并发I/O领域,多协程模型可以同时在性能和易用性方面取得非常好的效果,所以我们做了跟QEMU/KVM类似的选择——在底层将事件驱动模型转换成了多协程模型,最终形成了“多进程+多协程+事件驱动”的混合并发模型。
3.4 存储结构
如图所示,Ursa中的存储结构与GFS/HDFS相似,存储卷由64MB(可配置)大小的chunk组成。Ursa系统中的数据复制、故障检测与修复均在chunk层次进行。系统中,每3个(可配置)chunk组成一组,互为备份。每2个chunk组构成一个stripe组,实现条带化交错读写,提高单客户端顺序读写性能。Ursa在I/O栈上层添加Cache模块,可将最常用的数据缓存在客户端本地的SSD介质当中,当访问命中缓存时可大大提高性能。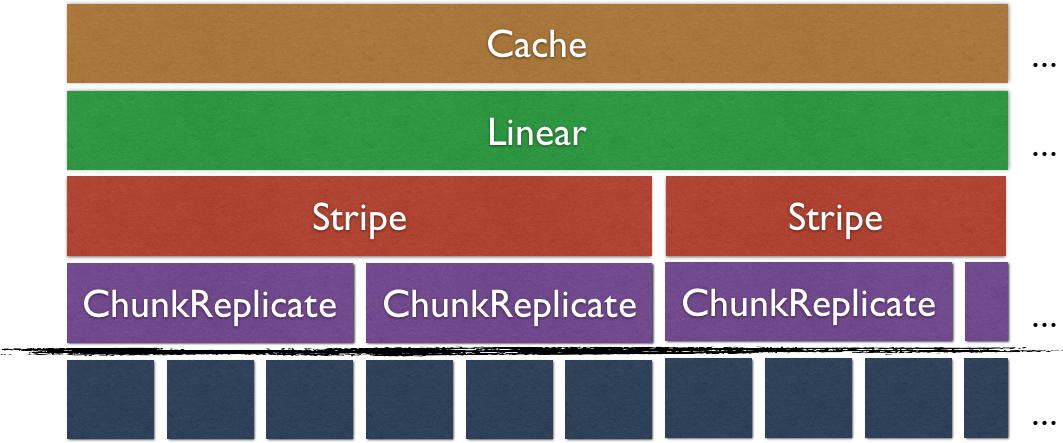
3.5 写入策略
最常见的写入策略有两种:(1)客户端直接写多个副本到各个Chunk Server,如图(a)所示,Sheepdog采用此种办法;(2)客户端写第一个副本,并将写请求依次传递下去,如图(b)所示。这两种方法各有利弊:前者通常具有较小的写入延迟,但吞吐率最高只能达到网络带宽的1/3;后者的吞吐率可以达到100%网络带宽,却具有较高的写入延迟。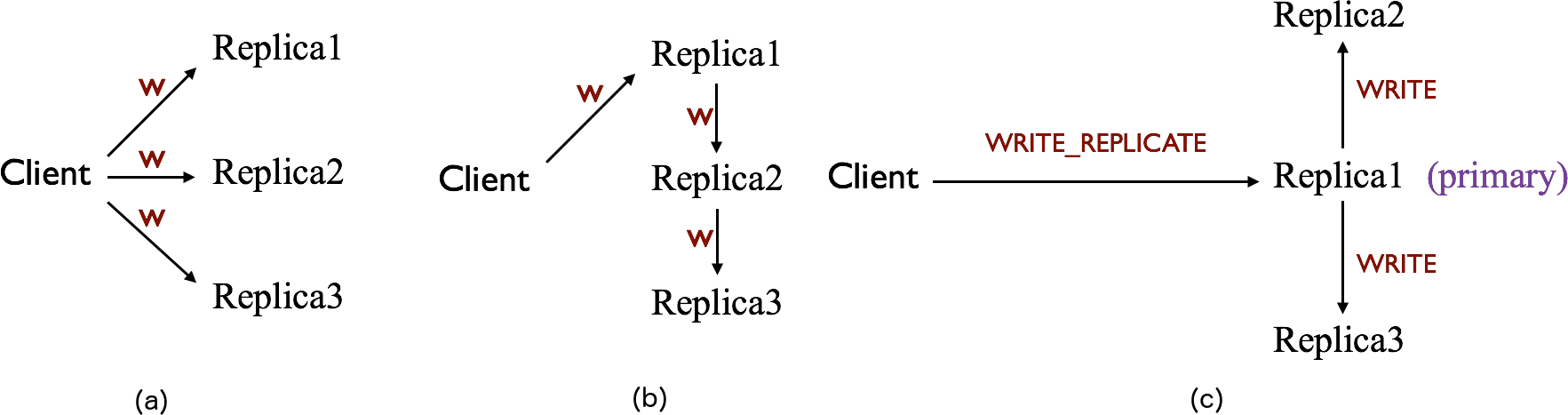
由于Ursa可能用于支持各种类型的应用,必须同时面向吞吐率和带宽进行优化,所以我们设计采用了一种分叉式的写入策略:如图(c)所示,客户端使用WRITE_REPLICATE请求求将数据写到第一个副本,称为primary,然后由primary负责将数据分别写到其他副本。这样Ursa可以在吞吐率和延迟两方面取得较好的均衡。为确保数据可靠性,写操作会等所有副本的写操作都完成之后才能返回。
3.6 无状态服务
Chunk Server内部几乎不保存状态,通常情况下各个请求之间是完全独立执行的,并且重启Chunk Server不会影响后续请求的执行。这样的Chunk Server不但具有更高的鲁棒性,而且具有更高的扩展性。许多其他网络服务、协议的设计都遵循了无状态的原则。
3.7 模块
如下图所示,Ursa中的I/O功能模块的组织采用decorator模式,即所有模块都实现了IStore抽象接口,其中负责直接与Chunk Server通信的模块属于decorator模式中的concrete component,其余模块均为concrete decorator。所有的decorator都保存数量不等的指向其他模块的指针(IStore指针)。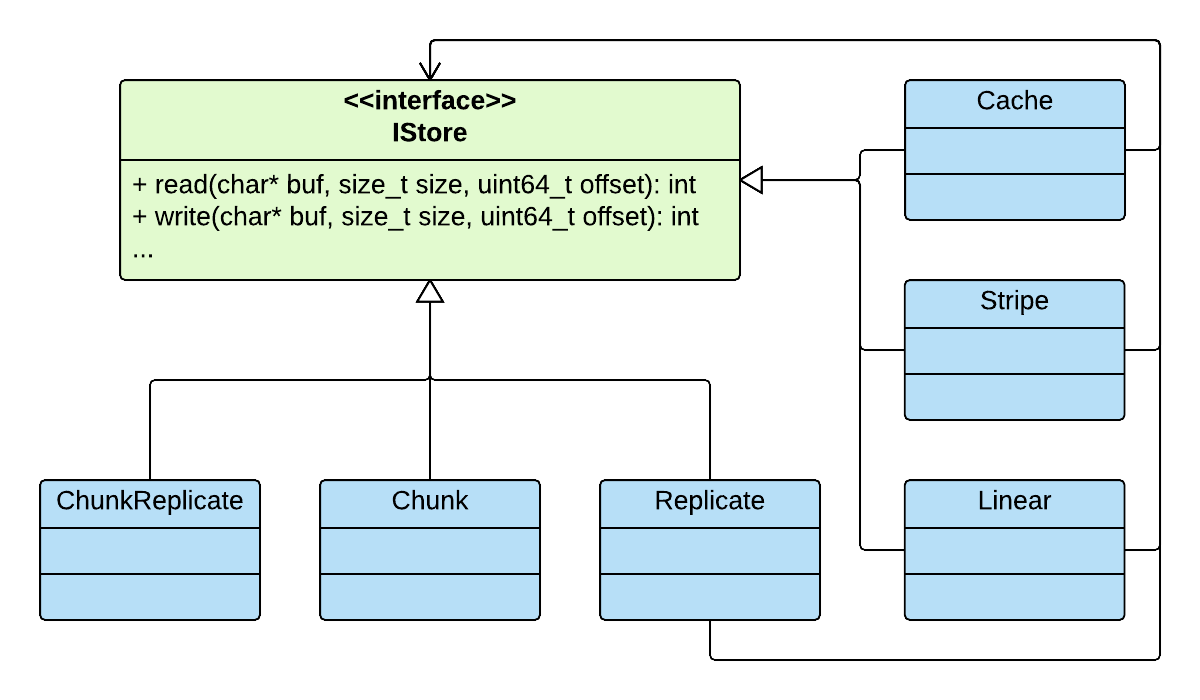
在运行时,Ursa的I/O栈层次结构的对象图如下所示。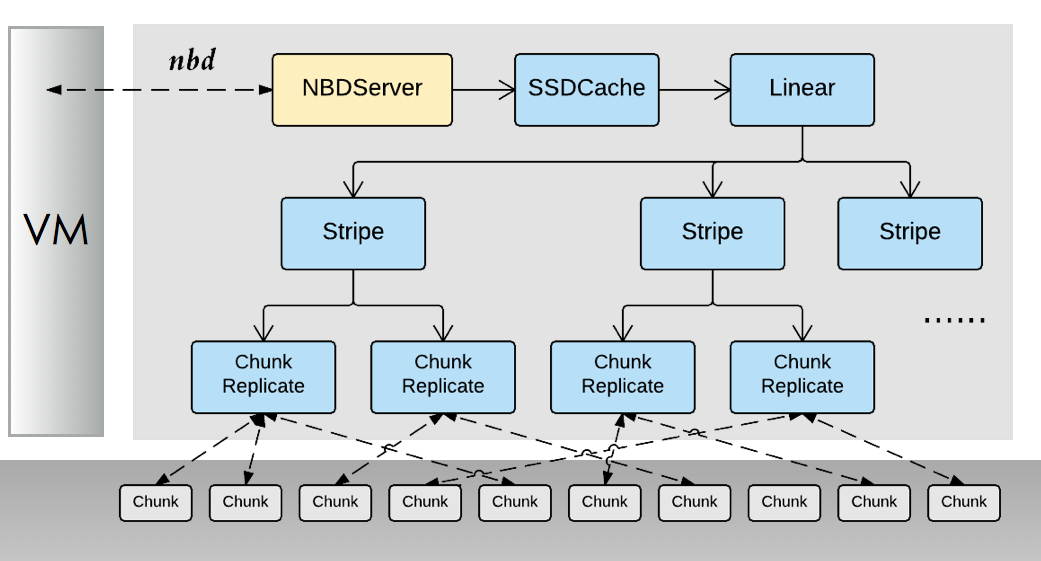
3.8 产品界面
4.性能实测
如下图所示,测试环境由万兆以太网、1台Client和3台Chunk Server组成,chunk文件存在tmpfs上,即所有写操作不落盘,写到内存为止。选择tmpfs主要是为了避免硬盘的I/O速度的局限性,以便测试Ursa在极限情况下的表现。
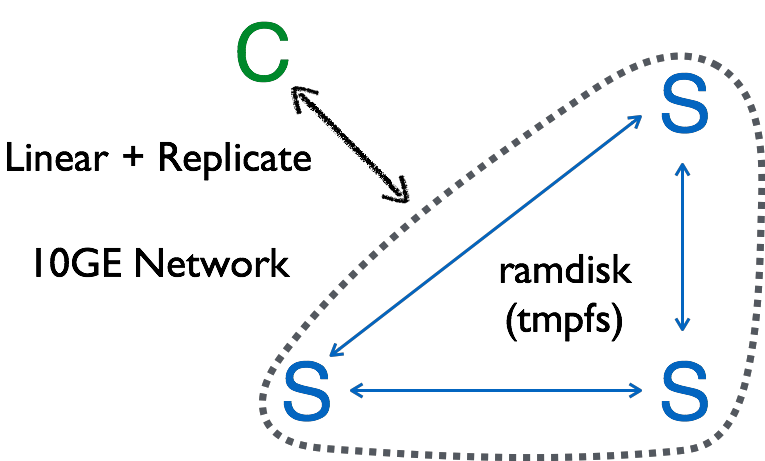
测试环境的网络延迟如下:
在上述环境中,用fio分别测试了读写操作的吞吐率、IOPS以及I/O延迟,测试参数与结果如下: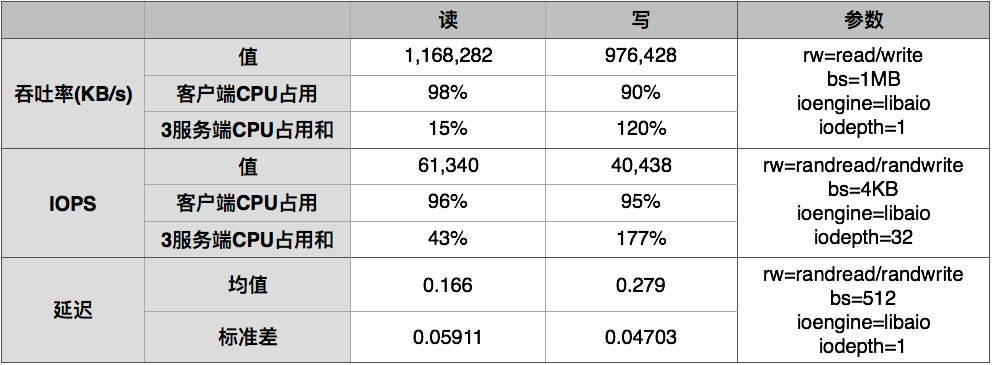
从测试结果可以看出:
(1). Ursa在吞吐率测试中可以轻易接近网卡理论带宽;
(2). Ursa的IOPS性能可以达到SSD的水准;
(3). Ursa的读延迟接近ping值,写操作需要写3个副本,延迟比读高68%。
作为对比,我们在测试Ceph的过程中监测到服务端CPU占用情况如下:
此时机器上5个存储服务进程ceph-osd共占用123.7%的CPU资源,提供了4 101的读IOPS服务;而Ursa的服务进程只消耗了43%的CPU资源,提供了61 340读IOPS服务,运行效率比Ceph高43倍。在客户端方面,Ceph消耗了500%+的CPU资源,得到了16 407读IOPS;而Ursa只消耗了96%的CPU资源,得到了61 340读IOPS,运行效率比Ceph高21倍。
总结与展望
Ursa从零开始动手开发到内部上线只经历了9个月的时间,虽然基本功能、性能都已达到预期,但仍有许多需要进一步开发的地方。一个重要的方向是对SSD的支持。虽然将HDD简单替换为SSD,不修改Ursa的任何代码、配置就可以运行,并取得性能上的显著改善,然而SSD在性能、成本、寿命等方面与HDD差异巨大,Ursa必须做出针对性的优化才能使SSD扬长避短。另一个重要方向是对大量VM同时启动的更好的支持。如果同时有上百台相同的VM从Ursa启动(即系统盘放在Ursa上),会在短时间内有大量读请求访问相同的数据集(启动文件),形成局部热点,此时相关的Chunk Server服务能力会出现不足,导致启动变慢。由于各个VM所需的启动数据基本相同,我们可以采用“一传十,十传百”的方式组织一个应用层组播树overlay网络来进行数据分发,这样可以从容应对热点数据访问问题。随着一步步的完善,相信Ursa将在云平台的运营当中起到越来越重要的作用。
相关文章
- 这篇文章主要介绍了阿里云飞天分布式系统使用沙箱机制的经验总结,通过对沙箱机制的使用可以有效维护云计算服务器的安全,需要的朋友可以参考下2016-02-26
- 这篇文章主要介绍了解析百度开放云分布式计算平台对大数据的处理,讲到了MapReduce 和BML机器学习等干货,需要的朋友可以参考下2016-02-02
- 这篇文章主要介绍了在Ubuntu系统上部署分布式系统Ceph的方法,文中对Ceph做了一个简单的说明,需要的朋友可以参考下2016-01-15
- 这篇文章主要介绍了在CentOS下安装和配置分布式系统Ceph的教程,在云计算大行其道的当下分布式系统正是一个发展趋势,需要的朋友可以参考下2015-11-23
分布式队列服务MemcacheQ在Linux系统下的编译安装
不少人在MemcacheQ的安装上遇到了不少麻烦,小编就为大家详细介绍下MemcacheQ在Linux系统下的编译安装,需要的朋友不要错过啊2015-06-15- 这篇文章主要介绍了美团网站前端的组件化开发经验,随着Facebook开源JavaScript的React框架,组件化的前端开发优势日益凸显,俨然成为当下的潮流,需要的朋友可以参考下2016-03-25
- 这篇文章主要介绍了美团网站搜索排序解决方案分享,分为线上篇和线下篇来讲,深入剖析了美团将大数据排序进行优化的架构,十分推荐!需要的朋友可以参考下2016-03-25
- 这篇文章主要介绍了美团点评对于网站性能优化的经验总结,根据美团点评的项目总结出了一些网站构件原则及一些实际案例的分享,需要的朋友可以参考下2016-03-23
- 这篇文章主要介绍了美团内部所采用的网站压力测试方案,包括其对开源压力测试工具的应用以及其相关流量拷贝等功能的使用,,需要的朋友可以参考下2016-03-23
美团酒店服务使用Node.js实现JavaScript全栈开发的经验分享
这篇文章主要介绍了美团酒店服务使用Node.js实现JavaScript全栈开发的经验分享,前端js+数据库MongoDB+后端Node的JavaScript一站式开发是时下的热门建站方案,需要的朋友可以2016-03-08
最新评论