
百度蜘蛛抓取时返回304状态码的问题分析
发布时间:2012-08-29 17:13:48 作者:佚名  我要评论
我要评论
网站被百度的蜘蛛抓取时返回304状态码是什么意思呢
最近遇到一个网站被百度蜘蛛抓取首页后大量返回304状态码的问题,以前遇到过301和302,就是没了解过304,刚好可以对这个情况进行一下分析和观察,以便比较深入的了解该问题的出现以及应对之策。
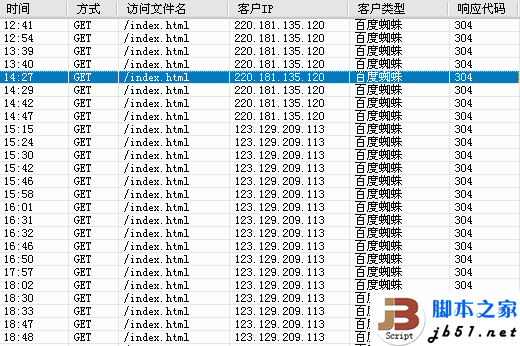
GET /index.html - 80 - 220.181.135.120 Sosospider+(+http://help.soso.com/webspider.htm) 304 0 0
GET /index.html - 80 - 123.129.209.113 Mozilla/5.0+(compatible;+Baiduspider/2.0;++http://www.baidu.com/search/spider.html) 304 0 0
但网站每天都有较多内容的更新,怎么会返回未更新的状态码呢,查看了网站进几天的网站IIS日志,发现这几天对首页的抓取都是返回的304状态码,一般情况下大概会是一下几种可能:
1、服务器缓存缘故
设置缓存的作用一般都是为了加速网站的提前加载,就像我们在浏览器上访问网站的时候也比较容易出现缓存问题,当你打开一个网站之后,如果该网站有更新或者有 变化,直接点击首页会发现还是之前访问的页面,而ctrl+F5重新加载后才会显示新的页面,这其实就是缓存的缘故。另外,有的时候和一些较大的网站换友情链接也会遇到,对方加了友链之后首页不会马上显示,会因为缓存而需要过一段时间才能显示。
2、网站结构问题
如果网站结构不能有效的让蜘蛛顺利爬行,也就是说虽然蜘蛛有抓取,但由于网站结构问题导致蜘蛛前后两次抓取内容相同,或者说蜘蛛每次抓取首页都只抓了那块固定的内容,那么就势必导致蜘蛛对首页的抓取返回304状态码。
3、网站速度问题
谷歌就针对网站的加载时间更 新过算法,把网站加载时间纳入了排名因素,就算搜索引擎排名不重视这点,对于用户体验也是有很大影响,谁也不会愿意多花时间在一个需要加载几十秒甚至几分 钟的网站上面。而对于搜索蜘蛛也是如此,网站的加载速度也会影响蜘蛛的正常抓取,一般情况下网站都是从上往下的加载,而有的时候由于速度因素导致网站只加载了头部,后面部分而没有及时显示出来,也可能导致蜘蛛只抓取了头部部分内容,而由于一般网站的头部都是相同的,也就容易出现了抓取返回没更新的状态码。
另外,网络线路的互通也是一个因素。
4、网站内容问题
网上查找了下关于304状态码的一些内容,不少人都认为是网站内容长期采集或是伪原创也能导致蜘蛛返回该状态码,因为网站内容采集或伪原创的确会降低网站质量,导致百度不收录等情况,搜索蜘蛛也会认为网站内容不具备收录的意义,那么也就不会抓取新的内容而返回没有更新的状态。
5、重视该状态码
既然304状态码是表示未更新的情况,那么经常出现就需要引起重视,同时也需要观察出现该状态码的同时网站各方面数据的变化和趋势,以便对该状态码的影响有较好的了解。
暂时网站出现304状态码之后经过百度更新收录有所减少,前几天有过断断续续的网站无法访问的情况,第二天网站首页就被K掉,在更换服务器之后恢复网站正常访问,次日首页再次恢复,目前仍需要观察和分析,才能更好掌握该状态码。

GET /index.html - 80 - 220.181.135.120 Sosospider+(+http://help.soso.com/webspider.htm) 304 0 0
GET /index.html - 80 - 123.129.209.113 Mozilla/5.0+(compatible;+Baiduspider/2.0;++http://www.baidu.com/search/spider.html) 304 0 0
但网站每天都有较多内容的更新,怎么会返回未更新的状态码呢,查看了网站进几天的网站IIS日志,发现这几天对首页的抓取都是返回的304状态码,一般情况下大概会是一下几种可能:
1、服务器缓存缘故
设置缓存的作用一般都是为了加速网站的提前加载,就像我们在浏览器上访问网站的时候也比较容易出现缓存问题,当你打开一个网站之后,如果该网站有更新或者有 变化,直接点击首页会发现还是之前访问的页面,而ctrl+F5重新加载后才会显示新的页面,这其实就是缓存的缘故。另外,有的时候和一些较大的网站换友情链接也会遇到,对方加了友链之后首页不会马上显示,会因为缓存而需要过一段时间才能显示。
2、网站结构问题
如果网站结构不能有效的让蜘蛛顺利爬行,也就是说虽然蜘蛛有抓取,但由于网站结构问题导致蜘蛛前后两次抓取内容相同,或者说蜘蛛每次抓取首页都只抓了那块固定的内容,那么就势必导致蜘蛛对首页的抓取返回304状态码。
3、网站速度问题
谷歌就针对网站的加载时间更 新过算法,把网站加载时间纳入了排名因素,就算搜索引擎排名不重视这点,对于用户体验也是有很大影响,谁也不会愿意多花时间在一个需要加载几十秒甚至几分 钟的网站上面。而对于搜索蜘蛛也是如此,网站的加载速度也会影响蜘蛛的正常抓取,一般情况下网站都是从上往下的加载,而有的时候由于速度因素导致网站只加载了头部,后面部分而没有及时显示出来,也可能导致蜘蛛只抓取了头部部分内容,而由于一般网站的头部都是相同的,也就容易出现了抓取返回没更新的状态码。
另外,网络线路的互通也是一个因素。
4、网站内容问题
网上查找了下关于304状态码的一些内容,不少人都认为是网站内容长期采集或是伪原创也能导致蜘蛛返回该状态码,因为网站内容采集或伪原创的确会降低网站质量,导致百度不收录等情况,搜索蜘蛛也会认为网站内容不具备收录的意义,那么也就不会抓取新的内容而返回没有更新的状态。
5、重视该状态码
既然304状态码是表示未更新的情况,那么经常出现就需要引起重视,同时也需要观察出现该状态码的同时网站各方面数据的变化和趋势,以便对该状态码的影响有较好的了解。
暂时网站出现304状态码之后经过百度更新收录有所减少,前几天有过断断续续的网站无法访问的情况,第二天网站首页就被K掉,在更换服务器之后恢复网站正常访问,次日首页再次恢复,目前仍需要观察和分析,才能更好掌握该状态码。
相关文章
- 在我的既有观念中,搜索引擎的网页爬虫/蜘蛛/机器人(Crawler/Spider/Robot)只抓取页面的 HTML 代码,对于内部或外部的 JS 与 CSS 代码是一律无视的。2010-01-01
- 百度蜘蛛日志抓取解读 教你如何提高百度收录:百度的收录是关心的重中之重,了解百度蜘蛛的爬行规律从而更好的改善收录情况也是必须要掌握的。2010-06-29
- 如何让搜索引擎蜘蛛喜欢上你的网站,以下几点大家都注意下2012-03-23
- 做网站的都希望被搜索引擎所收录.就是希望网络蜘蛛能爬到自己的网站里收录信息2012-07-05
- 搜索引擎蜘蛛每天是怎么样去爬取我们的网的呢?针对这些你有多少的了解?那搜索引擎蜘蛛的爬取过程又是怎么样的呢?2013-04-01
- 网站有哪些地方是不利于蜘蛛爬取的呢?下面脚本之家分享了一些蜘蛛爬取陷阱,让蜘蛛爬去不到页面的一些因素,需要的朋友可以参考下2014-10-13
- 想要提高网站的排名首先要了解蜘蛛的爬行规则,下面我们来看看解蜘蛛最喜欢的是什么?当蜘蛛爬行一个网站的时候,它需要爬行的信息首先就是站内的结构,查看站内结构是否是2014-10-14
- 作为一名编辑乃至站长,在关注网站在搜索引擎排名的时候,最重要的就是蜘蛛(spider)。搜索引擎蜘蛛是一个自动抓取互联网上网页内容的程序,每个搜索引擎都有自己的蜘蛛,那2016-05-27
最新评论