
![用Python写网络爬虫 (理查德 劳森) 中文pdf完整版[10MB]](http://img.jbzj.com/do/uploads/litimg/170121/1A5142J159.jpg)
 精通Python网络爬虫:核心技术、框架与项目实战 附源码 中文pdf
精通Python网络爬虫:核心技术、框架与项目实战 附源码 中文pdf108.6MB / 10-23
 python网络爬虫(抓取网页的含义和URL基本构成) 中文PDF版 4.25MB
python网络爬虫(抓取网页的含义和URL基本构成) 中文PDF版 4.25MB4.25MB / 09-13
 Python网络爬虫实战(胡松涛 著)完整版PDF[47MB]
Python网络爬虫实战(胡松涛 著)完整版PDF[47MB]47.4MB / 11-23



-

Python网络爬虫技术课件 + 代码 中文pdf完整版 Python电子书 / 45.4MB
-

Python网络爬虫实战案例 中文版PDF Python电子书 / 172KB
-

-

廖雪峰 Python3 教程1-3及新版全套 中文PDF完整版 Python电子书 / 10.2MB
-

Python3零基础入门教程 中文pdf完整版 Python电子书 / 2.0MB
-

Python3 高级教程 廖雪峰 中文pdf完整版 Python电子书 / 2.0MB
-

Python正则表达式最全汇总手册+应用实例 中文PDF Python电子书 / 1.31MB
-

Python爬虫教程合集(1季-3季) 中文PDF版 Python电子书 / 2.2MB
-

-
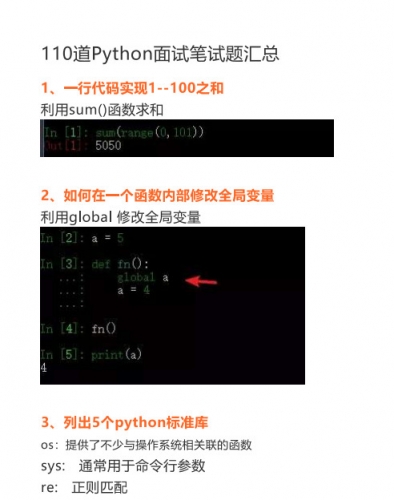
110道Python面试题汇总 中文PDF版 Python电子书 / 4.6MB










详情介绍
作为一种便捷地收集网上信息并从中抽取出可用信息的方式,网络爬虫技术变得越来越有用。使用Python这样的简单编程语言,你可以使用少量编程技能就可以爬取复杂的网站。
《用Python写网络爬虫》作为使用Python来爬取网络数据的杰出指南,讲解了从静态页面爬取数据的方法以及使用缓存来管理服务器负载的方法。此外,本书还介绍了如何使用AJAX URL和Firebug扩展来爬取数据,以及有关爬取技术的更多真相,比如使用浏览器渲染、管理cookie、通过提交表单从受验证码保护的复杂网站中抽取数据等。本书使用Scrapy创建了一个高级网络爬虫,并对一些真实的网站进行了爬取。
《用Python写网络爬虫》介绍了如下内容:
通过跟踪链接来爬取网站;
使用lxml从页面中抽取数据;
构建线程爬虫来并行爬取页面;
将下载的内容进行缓存,以降低带宽消耗;
解析依赖于JavaScript的网站;
与表单和会话进行交互;
解决受保护页面的验证码问题;
对AJAX调用进行逆向工程;
使用Scrapy创建高级爬虫。
本书是为想要构建可靠的数据爬取解决方案的开发人员写作的,本书假定读者具有一定的Python编程经验。当然,具备其他编程语言开发经验的读者也可以阅读本书,并理解书中涉及的概念和原理。
目录
第1章 网络爬虫简介 1
第2章 数据抓取 23
第3章 下载缓存 39
第4章 并发下载 57
第5章 动态内容 69
第6章 表单交互 89
第7章 验证码处理 103
第8章 Scrapy 121
第9章 总结 143
下载地址
人气书籍

Python学习手册第4版 中文PDF版 数10万Python爱好者的入门必读 中文高清pdf版")
Python 核心编程 (第二版) 中文高清pdf版![Python编程入门经典 PDF中文版[56M]](//img.jbzj.com/do/uploads/litimg/130228/142530221139.gif "Python编程入门经典 PDF中文版[56M]")
Python编程入门经典 PDF中文版[56M]![Python学习手册 第5版(Learning Python, 5th Edition)[鲁特兹] P](//img.jbzj.com/do/uploads/litimg/150906/1143312OG1.jpg "Python学习手册 第5版(Learning Python, 5th Edition)[鲁特兹] P")
Python学习手册 第5版(Learning Python, 5th Edition)[鲁特兹] P![用Python写网络爬虫 (理查德 劳森) 中文pdf完整版[10MB]](//img.jbzj.com/do/uploads/litimg/170121/1A5142J159.jpg "用Python写网络爬虫 (理查德 劳森) 中文pdf完整版[10MB]")
用Python写网络爬虫 (理查德 劳森) 中文pdf完整版[10MB]![Python数据分析与挖掘实战 完整版 pdf扫描版[63MB]](//img.jbzj.com/do/uploads/litimg/161226/1G1302L315.jpg "Python数据分析与挖掘实战 完整版 pdf扫描版[63MB]")
Python数据分析与挖掘实战 完整版 pdf扫描版[63MB]![Python金融大数据分析 完整版 中文pdf扫描版[42MB]](//img.jbzj.com/do/uploads/litimg/161109/1FQ12MO0.jpg "Python金融大数据分析 完整版 中文pdf扫描版[42MB]")
Python金融大数据分析 完整版 中文pdf扫描版[42MB] 中文高清pdf完整版")
Python基础教程(第3版) 中文高清pdf完整版![Head First Python(中文版) PDF 扫描版[38M]](//img.jbzj.com/do/uploads/litimg/130613/093Q42241W.jpg "Head First Python(中文版) PDF 扫描版[38M]")
Head First Python(中文版) PDF 扫描版[38M]![Python Qt GUI快速编程——PyQt编程指南 中文pdf完整版[99MB]](//img.jbzj.com/do/uploads/litimg/170615/1G9252L424.jpg "Python Qt GUI快速编程——PyQt编程指南 中文pdf完整版[99MB]")
Python Qt GUI快速编程——PyQt编程指南 中文pdf完整版[99MB]

 中文高清pdf版")
![Python编程入门经典 PDF中文版[56M]](http://img.jbzj.com/do/uploads/litimg/130228/142530221139.gif "Python编程入门经典 PDF中文版[56M]")
![Python学习手册 第5版(Learning Python, 5th Edition)[鲁特兹] P](http://img.jbzj.com/do/uploads/litimg/150906/1143312OG1.jpg "Python学习手册 第5版(Learning Python, 5th Edition)[鲁特兹] P")
![Python数据分析与挖掘实战 完整版 pdf扫描版[63MB]](http://img.jbzj.com/do/uploads/litimg/161226/1G1302L315.jpg "Python数据分析与挖掘实战 完整版 pdf扫描版[63MB]")
![Python金融大数据分析 完整版 中文pdf扫描版[42MB]](http://img.jbzj.com/do/uploads/litimg/161109/1FQ12MO0.jpg "Python金融大数据分析 完整版 中文pdf扫描版[42MB]")
 中文高清pdf完整版")
![Head First Python(中文版) PDF 扫描版[38M]](http://img.jbzj.com/do/uploads/litimg/130613/093Q42241W.jpg "Head First Python(中文版) PDF 扫描版[38M]")
![Python Qt GUI快速编程——PyQt编程指南 中文pdf完整版[99MB]](http://img.jbzj.com/do/uploads/litimg/170615/1G9252L424.jpg "Python Qt GUI快速编程——PyQt编程指南 中文pdf完整版[99MB]")
下载声明
☉ 解压密码:www.jb51.net 就是本站主域名,希望大家看清楚,[ 分享码的获取方法 ]可以参考这篇文章
☉ 推荐使用 [ 迅雷 ] 下载,使用 [ WinRAR v5 ] 以上版本解压本站软件。
☉ 如果这个软件总是不能下载的请在评论中留言,我们会尽快修复,谢谢!
☉ 下载本站资源,如果服务器暂不能下载请过一段时间重试!或者多试试几个下载地址
☉ 如果遇到什么问题,请评论留言,我们定会解决问题,谢谢大家支持!
☉ 本站提供的一些商业软件是供学习研究之用,如用于商业用途,请购买正版。
☉ 本站提供的用Python写网络爬虫 (理查德 劳森) 中文pdf完整版[10MB]资源来源互联网,版权归该下载资源的合法拥有者所有。