
![Hadoop+Spark生态系统操作与实战指南 完整pdf扫描版[115MB]](http://img.jbzj.com/do/uploads/litimg/190327/1IG32JB8.jpg)
 CODESYS基础编程及应用指南 中文pdf完整版
CODESYS基础编程及应用指南 中文pdf完整版10.6MB / 11-19
 Tcl教程中文版+入门教程 完整版PDF
Tcl教程中文版+入门教程 完整版PDF2.12MB / 09-30
 图解算法小抄(笔记) 中文PDF完整版
图解算法小抄(笔记) 中文PDF完整版6.1MB / 09-10
 QNX官方开发手册(中英文版) 完整版pdf
QNX官方开发手册(中英文版) 完整版pdf6.32MB / 09-09
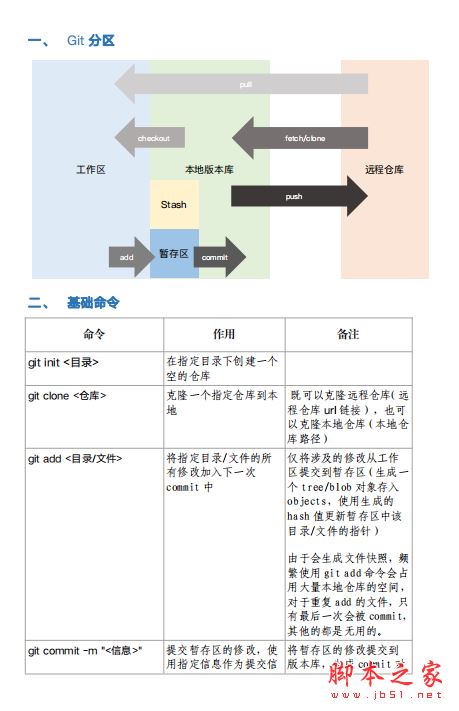 git常用命令手册 完整版PDF
git常用命令手册 完整版PDF2.59MB / 07-11
 lua中文手册+基础教程 完整版PDF
lua中文手册+基础教程 完整版PDF2.52MB / 07-05
 OpenCV4函数手册 + OpenCV4.5中文官方文档 PDF版
OpenCV4函数手册 + OpenCV4.5中文官方文档 PDF版83.2MB / 09-04
 CMD命令大全超级详细完整版合集 + CMD命令手册 中文PDF版
CMD命令大全超级详细完整版合集 + CMD命令手册 中文PDF版1.8MB / 06-12
 SLAM导航机器人零基础实战系列 完整PDF中文版
SLAM导航机器人零基础实战系列 完整PDF中文版35.7MB / 04-28
 ORB-SLAM2源码解析 学习手册 v1.0 中文PDF完整版
ORB-SLAM2源码解析 学习手册 v1.0 中文PDF完整版27.8MB / 04-24










-
CODESYS基础编程及应用指南 中文pdf完整版 编程其它 / 10.6MB
-
Tcl教程中文版+入门教程 完整版PDF 编程其它 / 2.12MB
-
图解算法小抄(笔记) 中文PDF完整版 编程其它 / 6.1MB
-
QNX官方开发手册(中英文版) 完整版pdf 编程其它 / 6.32MB
-
OpenCV4函数手册 + OpenCV4.5中文官方文档 PDF版 编程其它 / 83.2MB
-
git常用命令手册 完整版PDF 编程其它 / 2.59MB
-
lua中文手册+基础教程 完整版PDF 编程其它 / 2.52MB
-
-
SLAM导航机器人零基础实战系列 完整PDF中文版 编程其它 / 35.7MB
-
ORB-SLAM2源码解析 学习手册 v1.0 中文PDF完整版 编程其它 / 27.8MB
详情介绍
《Hadoop+Spark生态系统操作与实战指南》用于Hadoop+Spark快速上手,全面解析Hadoop和Spark生态系统,通过原理解说和实例操作每一个组件,让读者能够轻松跨入大数据分析与开发的大门。
全书共12章,大致分为3个部分,第1部分(第1~7章)讲解Hadoop的原生态组件,包括Hadoop、ZooKeeper、HBase、Hive环境搭建与安装,以及介绍MapReduce、HDFS、ZooKeeper、HBase、Hive原理和Apache版本环境下实战操作。第2部分(第8~11章)讲解Spark的原生态组件,包括SparkCore、SparkSQL、SparkStreaming、DataFrame,以及介绍Scala、SparkAPI、SparkSQL、SparkStreaming、DataFrame原理和CDH版本环境下实战操作,其中Flume和Kafka属于Apache*开源项目也放在本篇讲解。第3部分(第12章)讲解两个大数据项目,包络网页日志离线项目和实时项目,在CDH版本环境下通过这两个项目将Hadoop和Spark原生态组件进行整合,一步步带领读者学习和实战操作。
本书适合想要快速掌握大数据技术的初学者,也适合作为高等院校和培训机构相关专业师生的教学参考书和实验用书。
目录
第1章 Hadoop概述 1
第2章 Hadoop集群搭建 22
第3章 Hadoop基础与原理 56
第4章 ZooKeeper实战 72
第5章 MapReduce实战 88
第6章 HBase实战 122
第7章 Hive实战 141
第8章 Scala实战 162
第9章 Flume实战 207
第10章 Kafka实战 215
第11章 Spark实战 234
第12章 大数据网站日志分析项目267
下载地址
人气书籍

![设计模式:可复用面向对象软件的基础 PDF 扫描版[21M]](http://img.jbzj.com/do/uploads/litimg/130617/111016222643.jpg "设计模式:可复用面向对象软件的基础 PDF 扫描版[21M]")
![啊哈!算法 PDF扫描版[73MB]](http://img.jbzj.com/do/uploads/litimg/150117/153I42UK0.png "啊哈!算法 PDF扫描版[73MB]")

![算法图解 (袁国忠著) 中文pdf完整版[17MB]](http://img.jbzj.com/do/uploads/litimg/170330/1FGRI202.jpg "算法图解 (袁国忠著) 中文pdf完整版[17MB]")
![Unity3D游戏开发 宣雨松著 PDF扫描版[27MB]](http://img.jbzj.com/do/uploads/litimg/140510/1524562S048.png "Unity3D游戏开发 宣雨松著 PDF扫描版[27MB]")
![R语言实战(第2版) ([美]卡巴科弗) 中文pdf完整版[19MB]](http://img.jbzj.com/do/uploads/litimg/170212/1FU02M035.jpg "R语言实战(第2版) ([美]卡巴科弗) 中文pdf完整版[19MB]")
![unity3d从入门到精通中文教程 高清PDF完整版[11MB]](http://img.jbzj.com/do/uploads/litimg/150926/1625122HS7.jpg "unity3d从入门到精通中文教程 高清PDF完整版[11MB]")

![大型网站技术架构.核心原理与案例分析(李智慧) PDF扫描版[52MB]](http://img.jbzj.com/do/uploads/litimg/150518/1616422X629.jpg "大型网站技术架构.核心原理与案例分析(李智慧) PDF扫描版[52MB]")
下载声明
☉ 解压密码:www.jb51.net 就是本站主域名,希望大家看清楚,[ 分享码的获取方法 ]可以参考这篇文章
☉ 推荐使用 [ 迅雷 ] 下载,使用 [ WinRAR v5 ] 以上版本解压本站软件。
☉ 如果这个软件总是不能下载的请在评论中留言,我们会尽快修复,谢谢!
☉ 下载本站资源,如果服务器暂不能下载请过一段时间重试!或者多试试几个下载地址
☉ 如果遇到什么问题,请评论留言,我们定会解决问题,谢谢大家支持!
☉ 本站提供的一些商业软件是供学习研究之用,如用于商业用途,请购买正版。
☉ 本站提供的Hadoop+Spark生态系统操作与实战指南 完整pdf扫描版[115MB]资源来源互联网,版权归该下载资源的合法拥有者所有。