
 若怀刷拉排助手(下拉框关键词刷排名工具) v1.0.1 绿色免费版
若怀刷拉排助手(下拉框关键词刷排名工具) v1.0.1 绿色免费版805KB / 01-18
 站长万能助手 v1.3 模拟POST、GET方式表单提交工具
站长万能助手 v1.3 模拟POST、GET方式表单提交工具36MB / 06-24
 ET 无人值守免费自动采集器 3.5 绿色版
ET 无人值守免费自动采集器 3.5 绿色版18.3MB / 10-24
 石青伪原创SEO高级工具 v2.7.9.1 中文绿色免费版
石青伪原创SEO高级工具 v2.7.9.1 中文绿色免费版59.8MB / 11-11
 珍岛t云系统(T-Cloud) v3.6 官方安装版
珍岛t云系统(T-Cloud) v3.6 官方安装版93.7MB / 01-30





-

讯飞绘文(智能写作分析软件)v3.1.1 官方安装版 站长工具 / 102MB
-

后羿采集器 linux版 v4.0.4 官方免费版 站长工具 / 113MB
-

后羿采集器 v4.0.4 官方免费安装版 站长工具 / 82.8MB
-

搜外内容管家(关键词挖掘采集)V1.8.0 官方绿色版 站长工具 / 16.9MB
-
石青伪原创SEO高级工具 v2.7.9.1 中文绿色免费版 站长工具 / 59.8MB
-

Vovsoft SEO Checker(SEO优化)v9.4 官方安装版 站长工具 / 6.55MB
-

-

VovSoft Broken Link Detector(网站死链检测)v4.2 绿色便携版 站长工具 / 2.19MB
-

Vovsoft Bulk Domain Appraisal域名价值评估 v3.6 绿色便携版 站长工具 / 3.52MB
-

Octoparse(数据采集软件) v8.7.2 官方免费安装版 站长工具 / 80.6MB









详情介绍
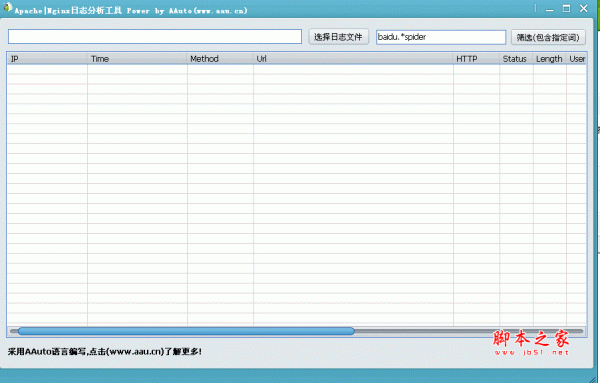
也可以用模式匹配语法 例如这样 404.*?baidu
PS:发现apache的日志也是可以用的。
awstats中, unique visitor 是根据IP来计算的,所以awstats中统计的UV值,即是IP值。
webtrends中, 也有对UV的统计,不过webtrends也是有JS统计代码的,所以,它的统计原理跟大部分统计代码都一样,通过JS获取客户端的cookie来计算UV值。
查看并询问了一些关于Google Analytics计算UV数的算法,Google Analytics对于独立访客(UV)的计算,是基于访客浏览器中cookie来确定的,当访客第一次(或cookie丢失后)访问添加GATC的代码时,便会创建一个唯一的cookie(即一个UV),cookie中utma变量记录了访客ID、访问次数、访问时间等信息,UV数以此累加。当访客丢失cookie或更换浏览器重新访问网站,都将会被认为新访客,而创建一个cookie,记录为一个新的UV。
apache日志分析:以下内容也是一些关于apache日志分析的东东,记录下来。
1.什么是UV?
UV是unique visitor的简写,是指独立访客,是以实际访问的电脑计数。
2.什么是IP?
IP是国际互联网协议(Internet Protocol)的简称,是通过网络间信息地址定位具体计算机的方式之一。
3.UV和IP的概念有什么区别?
对于IP来说,它在同一级别的网络(例如某个局域网、社区网、教学楼网或者INTERNET)范围内是唯一的,同一局域网内的所有电脑都只有一个共同ip。
举例来说,我在一个局域网里,对外的IP是219.129.170.111,那么跟我同一局域网里的所有电脑都是这个IP,也就是说假如整个局域网的电脑都访问您的网站的话,在24小时内也只计算一个IP,所以相对UV来说不是很精确。
而UV跟IP稍有不同,UV是访问你的网站的每一台电脑客户端。现在很多朋友用的网络都是局域网,引入了UV后,就能更精确的统计。
总结:
UV的统计数比IP更为准确,能够准确的计数每一台访问电脑,而IP把同一局域内的所有电脑视为一个。
(PS:UV计数会涉及COOKIE。)
上次因工作的需求对一台apache的log做了一次整体的分析,所以顺便也对apache的日志分析做下简单的介绍,主要参考apache官网的Log Files,手册参照 //httpd.apache.org/docs/2.2/logs.html
一.日志分析
如果apache的安装时采用默认的配置,那么在/logs目录下就会生成两个文件,分别是access_log和error_log
1.access_log
access_log为访问日志,记录所有对apache服务器进行请求的访问,它的位置和内容由CustomLog指令控制,LogFormat指令可以用来简化该日志的内容和格式
例如,我的其中一台服务器配置如下
CustomLog “| /usr/sbin/rotatelogs /var/log/apache2/%Y_%m_%d_other_vhosts_access.log 86400 480″ vhost_combined
-rw-r–r– 1 root root 22310750 12-05 23:59 2010_12_05_other_vhosts_access.log
-rw-r–r– 1 root root 26873180 12-06 23:59 2010_12_06_other_vhosts_access.log
-rw-r–r– 1 root root 26810003 12-07 23:59 2010_12_07_other_vhosts_access.log
-rw-r–r– 1 root root 24530219 12-08 23:59 2010_12_08_other_vhosts_access.log
-rw-r–r– 1 root root 24536681 12-09 23:59 2010_12_09_other_vhosts_access.log
-rw-r–r– 1 root root 14003409 12-10 14:57 2010_12_10_other_vhosts_access.log
通过CustomLog指令,每天一天生成一个独立的日志文件,同时也写了定时器将一周前的日志文件全部清除,这样可以显得更清晰,既可以分离每一天的日志又可以清除一定时间以前的日志通过制,LogFormat定义日志的记录格式
LogFormat “%h %l %u %t \”%r\” %>s %b \”%{Referer}i\” \”%{User-Agent}i\”" combined
LogFormat “%{X-Forwarded-For}i %l %u %t \”%r\” %>s %b \”%{Referer}i\” \”%{User-Agent}i\”" combinedproxy
LogFormat “%h %l %u %t \”%r\” %>s %b” common
LogFormat “%{Referer}i -> %U” referer
LogFormat “%{User-agent}i” agent
随意的tail一个access_log文件,下面是一条经典的访问记录
218.19.140.242 – - [10/Dec/2010:09:31:17 +0800] “GET /query/trendxml/district/todayreturn/month/2009-12-14/2010-12-09/haizhu_tianhe.xml HTTP/1.1″ 200 1933 “-” “Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.2.8) Gecko/20100722 Firefox/3.6.8 (.NET CLR 3.5.30729)”
一共是有9项,将他们一一拆开
218.19.140.242
-
-
[10/Dec/2010:09:31:17 +0800]
“GET /query/trendxml/district/todayreturn/month/2009-12-14/2010-12-09/haizhu_tianhe.xml HTTP/1.1″
200
1933
“-”
“Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.2.8) Gecko/20100722 Firefox/3.6.8 (.NET CLR 3.5.30729)”
1) 218.19.140.242 这是一个请求到apache服务器的客户端ip,默认的情况下,第一项信息只是远程主机的ip地址,但我们如果需要apache查出主机的名字,可以将 HostnameLookups设置为on,但这种做法是不推荐使用,因为它大大的减缓了服务器.另外这里的ip地址不一定就是客户主机的ip地址,如果 客户端使用了代理服务器,那么这里的ip就是代理服务器的地址,而不是原机.
2) - 这一项是空白,使用”-”来代替,这个位置是用于标注访问者的标示,这个信息是由identd的客户端存在,除非IdentityCheck为on,非则apache是不会去获取该部分的信息(ps:不太理解,基本上这一项都是为空,奉上原文)
The “hyphen” in the output indicates that the requested piece of information is not available. In this case, the information that is not available is the RFC 1413 identity of the client determined by identd on the clients machine. This information is highly unreliable and should almost never be used except on tightly controlled internal networks. Apache httpd will not even attempt to determine this information unless IdentityCheck is set to On.
3) - 这一项又是为空白,不过这项是用户记录用户HTTP的身份验证,如果某些网站要求用户进行身份雁阵,那么这一项就是记录用户的身份信息
4) [10/Dec/2010:09:31:17 +0800] 第四项是记录请求的时间,格式为[day/month/year:hour:minute:second zone],最后的+0800表示服务器所处的时区为东八区
5) “GET /..haizhu_tianhe.xml HTTP/1.1″ 这一项整个记录中最有用的信息,首先,它告诉我们的服务器收到的是一个GET请求,其次,是客户端请求的资源路径,第三,客户端使用的协议时HTTP/1.1,整个格式为”%m %U%q %H”,即”请求方法/访问路径/协议”
6) 200 这是一个状态码,由服务器端发送回客户端,它告诉我们客户端的请求是否成功,或者是重定向,或者是碰到了什么样的错误,这项值为200,表示服务器已经成 功的响应了客户端的请求,一般来说,这项值以2开头的表示请求成功,以3开头的表示重定向,以4开头的标示客户端存在某些的错误,以5开头的标示服务器端 存在某些错误,详细的可以参见 HTTP specification (RFC2616 section 10).[//www.w3.org/Protocols/rfc2616/rfc2616.txt]
7) 1933 这项表示服务器向客户端发送了多少的字节,在日志分析统计的时侯,把这些字节加起来就可以得知服务器在某点时间内总的发送数据量是多少
8) - 暂不知
9) “Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.2.8) Gecko/20100722 Firefox/3.6.8 (.NET CLR 3.5.30729)” 这项主要记录客户端的浏览器信息
2.error_log
error_log为错误日志,记录下任何错误的处理请求,它的位置和内容由ErrorLog指令控制,通常服务器出现什么错误,首先对它进行查阅,是一个最重要的日志文件
tail error_log,随意摘取一个记录
[Fri Dec 10 15:03:59 2010] [error] [client 218.19.140.242] File does not exist: /home/htmlfile/tradedata/favicon.ico
同样也是分为几个项
[Fri Dec 10 15:03:59 2010]
[error]
[client 218.19.140.242]
File does not exist: /home/htmlfile/tradedata/favicon.ico
1) [Fri Dec 10 15:03:59 2010] 记录错误发生的时间,注意,它跟我们上面access_log记录的时间格式是不同的
2) [error] 这一项为错误的级别,根据LogLevel指令来控制错误的类别,上面的404是属于error级别
3) [client 218.19.140.242] 记录客户端的ip地址
4) File does not exist: /home/htmlfile/tradedata/favicon.ico 这一项首先对错误进行了描述,例如客户端访问一个不存在或路径错误的文件,就会给出404的提示错误
二.实用的日志分析脚本
了解日志的各种定义后,这里分享一下从网上淘来的一些对日志分析的脚本
1.查看apache的进程数
ps -aux | grep httpd | wc -l
2.分析日志查看当天的ip连接数
cat default-access_log | grep “10/Dec/2010″ | awk ‘{print $2}’ | sort | uniq -c | sort -nr
3.查看指定的ip在当天究竟访问了什么url
cat default-access_log | grep “10/Dec/2010″ | grep “218.19.140.242″ | awk ‘{print $7}’ | sort | uniq -c | sort -nr
4.查看当天访问排行前10的url
cat default-access_log | grep “10/Dec/2010″ | awk ‘{print $7}’ | sort | uniq -c | sort -nr | head -n 10
5.看到指定的ip究竟干了什么
cat default-access_log | grep 218.19.140.242 | awk ‘{print $1″\t”$8}’ | sort | uniq -c | sort -nr | less
6.查看访问次数最多的几个分钟(找到热点)
awk ‘{print $4}’ default-access_log |cut -c 14-18|sort|uniq -c|sort -nr|head
三.使用awstats自动分析日志
当然啦,如果想最简单和最直观的分析日志还是用工具,现在网上较流行的工具是awstats,一个基于perl的web日志分析工具,功能很强大也支持IIS等服务器
下载地址
人气软件

V1.0 绿色免费版")
 v1.0.2 中文安装版")
")

 ADSL动态换IP刷流量工具")
相关文章
-
搜外内容管家(关键词挖掘采集)V1.8.0 官方绿色版
搜外内容管家支持键词挖掘、文章采集、问答组合功能,同时支持将文章自动发布到网站上,本站提供的是这款软件的安装版本...
-
 水淼网站权重查询助手 V1.0.0.0 绿色便携版
水淼网站权重查询助手 V1.0.0.0 绿色便携版水淼网站权重查询助手支持查询百度PC、百度移动、搜狗PC、搜狗移动等,本站提供的是这款软件的绿色版本...
-
讯飞绘文(智能写作分析软件)v3.1.1 官方安装版
讯飞绘文是一款AI智能写作软件,支持选题、写作、配图、排版、润色、发布、数据分析等功能,适用于公众号、头条号和新闻等多种场景,该软件集成了内容运营的全流程,能够实时捕...
-
网站爬虫实时分析 VovSoft SEO Checker v9.4 多语绿色便携版
VovSoft SEO Checker是一款易于使用的网站爬虫,能够高效地爬取小型和超大型网站,同时让您找到失效链接,实时分析结果,收集现场数据,欢迎需要的朋友下载使用...
-
 全网热点要闻采集器 V2.0 绿色便携版
全网热点要闻采集器 V2.0 绿色便携版全网热点要闻采集器支持一键采集全网热点要闻,是自媒体从业者必备神器等...
-
 VovSoft Bulk Domain Appraisal 破解补丁/注册机 v3.4 绿色版 附激活教程
VovSoft Bulk Domain Appraisal 破解补丁/注册机 v3.4 绿色版 附激活教程VovSoft Bulk Domain Appraisal 激活补丁,域名评估软件,VovSoft Bulk Domain Appraisal是一款域名评估软件,也是站长必备工具之一,但是VovSoft Bulk Domain Appraisal需...



下载声明
☉ 解压密码:www.jb51.net 就是本站主域名,希望大家看清楚,[ 分享码的获取方法 ]可以参考这篇文章
☉ 推荐使用 [ 迅雷 ] 下载,使用 [ WinRAR v5 ] 以上版本解压本站软件。
☉ 如果这个软件总是不能下载的请在评论中留言,我们会尽快修复,谢谢!
☉ 下载本站资源,如果服务器暂不能下载请过一段时间重试!或者多试试几个下载地址
☉ 如果遇到什么问题,请评论留言,我们定会解决问题,谢谢大家支持!
☉ 本站提供的一些商业软件是供学习研究之用,如用于商业用途,请购买正版。
☉ 本站提供的Apache|Nginx日志分析工具 绿色中文免费版资源来源互联网,版权归该下载资源的合法拥有者所有。